

Quem nunca precisou fazer a leitura de uma imagem via código? Quem já ouviu falar de OCR? Basicamente o Reconhecimento Ótico de Caracteres (OCR – Optical Character Recognition) funciona através de um rede neural que aprende a reconhecer os padrões das letras e números, e quanto melhor for treinada, melhor será sua precisão. Através de OCR é possível retirar a string de texto de dentro de uma imagem, geralmente de um documento digitalizado. Obviamente ele não faz milagres e existem algumas limitações.
Neste post iremos tratar de como utilizar a API de OCR do Microsoft Office em seus projetos C# para reconhecimento ótico de caracteres.
Veremos:
Vamos lá!

Microsoft Office Document Imaging
Existem diversas bibliotecas de OCR no mercado, em sua maioria pagas. Entretanto poucos sabem que o próprio Microsoft Office possui uma excelente API de OCR que pode ser usada através de uma referência a um componente COM+ do Microsoft Office 2003 ou 2007, chamado Microsoft Office Document Imaging. Na verdade o MODI é um aplicativo de scanner nativo do Office, mas o que nos interessa aqui é a sua API.
Esta API não é instalada por padrão quando se instala o MS Office, você terá que colocar o CD de instalação em seu computador e marcar a opção Microsoft Office Document Imaging dentro de Ferramentas do Office. Não se esqueça de marcar a opção de OCR, ou não funcionará.
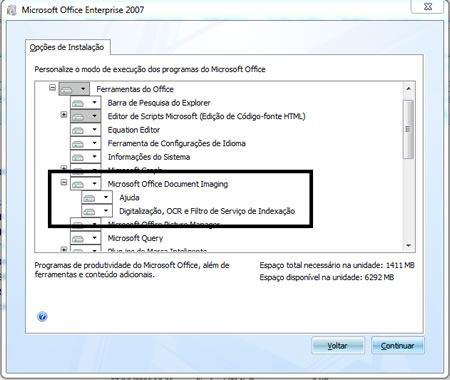
Após instalar a API de OCR, crie seu projeto no Visual Studio e adicione uma referência ao COM+ Microsoft Office Document Imaging. Note que esta é uma referência a um componente existente no Windows e para que funcione em seu ambiente de produção, você terá de ter o mesmo componente instalado lá (i.e. o MS Office).
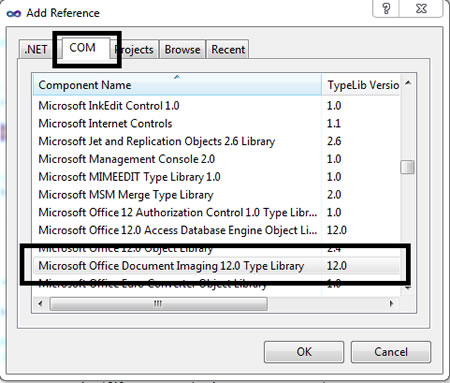
Agora vamos ao código.
Codificando uma aplicação de OCR
O código abaixo exemplifica como criar uma aplicação simples que lê uma imagem, cria um documento usando o a API do MODI (Microsoft Office Document Imaging) e depois faz o reconhecimento de caracteres em cima dele, retornando uma string com o texto.
|
1 2 3 4 5 6 7 |
MODI.Document md = new MODI.Document(); md.Create(@"C:\arquivo.jpg"); md.OCR(MODI.MiLANGUAGES.miLANG_PORTUGUESE, false, false); MODI.Image image = (MODI.Image)md.Images[0]; string texto = image.Layout.Text; |
Obviamente alguns erros podem acontecer e tentarei cobrir os mais comuns na próxima seção.
Erros Comuns
“Object hasn’t been initialized and can’t be used yet”
Ao contrário do que pode parecer, este erro não é problema com o documento. Na verdade este erro acontece quando o MODI não está instalado na máquina que está tentando executar o código. Verifique novamente se instalou o MODI com sucesso, sua instalação de Office deve ficar igual à imagem que coloquei no início deste post.
“OCR Running Error”
Este é um erro de reconhecimento ótico de caracteres, ou seja, a API de OCR não conseguiu entender o texto da imagem. Um dos principais problemas com OCR é que ele não consegue ler imagens muito pequenas. E estou falando da largura e altura da imagem e não do texto em si. Se suas imagens são pequenas, insira-as dentro de imagens maiores, preferencialmente com fundo branco para facilitar o reconhecimento. Tamanhos de 600x600px já resolvem o problema.
Outro motivo que pode gerar este erro é o uso de fundos muito poluídos (muitas cores ou textos sobrepostos como em CAPTCHAS) ou textos com má resolução (muito esticados ou embaçados, por exemplo). Nestes casos é provável que você tenha de tratar suas imagens antes de submetê-las à API.
Dúvidas ou sugestões, compartilhem nos comentários.





Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.