
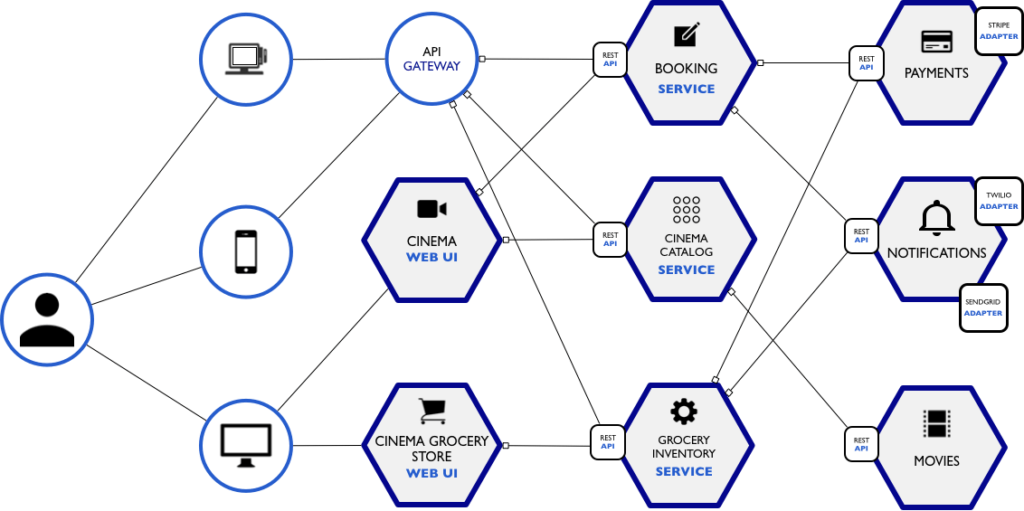
E chegamos à quarta parte da nossa série de artigos sobre como implementar na prática um projeto de sistema usando arquitetura de microservices usando Node.js e MongoDB.
Na primeira parte desta série eu dei uma introdução teórica sobre microservices, além de falar do propósito de usar Node e Mongo, apresentando nosso case que é ‘digno de cinema’. 😉
Na segunda parte, começamos a estruturar nosso projeto e preparamos toda a camada de dados e testes unitários do primeiro micro serviço.
Na terceira parte, finalizamos o desenvolvimento do primeiro micro serviço, o movies-service, que nos forneceu acesso a três chamadas:
- /movies: traz todos filmes;
- /movies/premieres: traz todos lançamentos;
- /movies/{id}: traz um filme por id;
Nesta quarta parte, conforme o trecho abaixo do case, vamos construir o microservice cinema-catalog-service, aproveitando bastante da expertise que obtivemos com o micro serviço anterior. A ideia é que este serviço receba a requisição do front-end e providencie o restante, inclusive chamando o movies-service quando necessário.
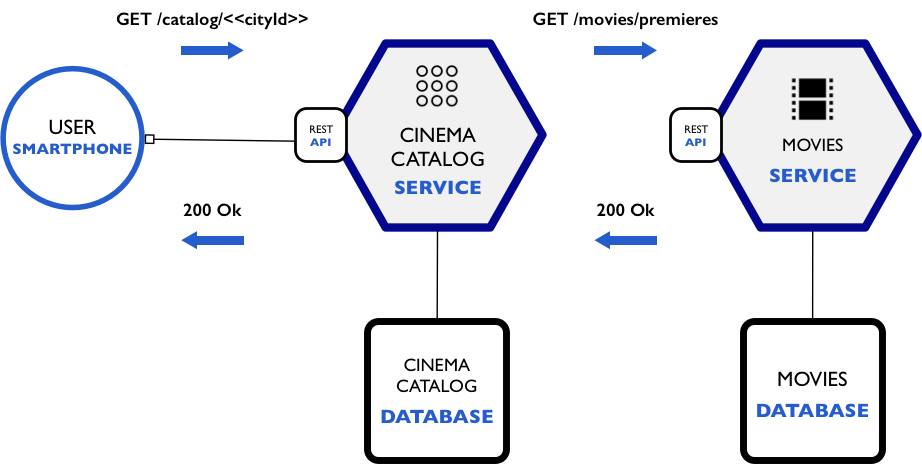
Veremos nesta etapa da série:
- Estruturando o Micro Serviço
- Modelando o banco de dados
- Subindo o banco e conectando
- Iniciando o Repositório
Então mãos à obra!

#1 – Estruturando o Micro Serviço
Este microservice chamado cinema-catalog-service deve ser uma pasta dentro do seu projeto cinema-microservice. No seu terminal, navegue até a pasta src com ‘cd’ e depois use o comando ‘npm init’ para gerar o package.json e adicione o script ‘start’ nele para facilitar nossas execuções depois, deixando-o como abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "name": "cinema-catalog-service", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "start": "node ./src/index", "test": "jest" }, "keywords": [], "author": "LuizTools", "license": "MIT" } |
Na sequência, crie pastas e arquivos para ficar com a seguinte configuração abaixo:
- cinema-microservice
- cinema-catalog-service
- data
- src
- api
- cinema-catalog.js
- cinema-catalog.test.js
- config
- database.js
- database.test.js
- repository
- repository.js
- repository.test.js
- server
- server.js
- server.test.js
- index.js
- index.test.js
- packages.json
- .env
- .env.example
- api
- cinema-catalog-service
Lembrando que na pasta data você deve apontar o seu banco de dados quando criarmos ele.
Aproveite este momento de configuração para rodar os comandos abaixo no terminal (dentro da pasta cinema-catalog-service) para instalar as dependências que vamos precisar:
|
1 2 3 4 5 |
npm i express morgan mongodb dotenv-safe npm i -D supertest jest npx create-jest |
Alguns dos arquivos acima nós vamos conseguir aproveitar do outro micro serviço. Sim, nós copiaremos alguns arquivos na cara dura. Essa é uma atitude bem polêmica dentro da engenharia de software mas perfeitamente natural sob a ótica da arquitetura de micro serviços.
Copie os seguintes arquivos do outro microservice para este:
- /config/database.js
- /config/database.test.js
- /server/server.js
- /server/server.test.js
- /.env.example
Mesmo os demais arquivos não sendo copiados na íntegra, aproveitaremos e muito a lógica deles, como você verá mais tarde.

#2 – Modelando o Banco de Dados
Vamos voltar a falar de banco de dados?
Isso porque cada microservice deve ter a sua própria base de dados, para garantir sua independência dos demais. No caso do movies-service, o banco armazena os dados dos filmes. No caso deste cinema-catalog-service, o banco armazenará os dados das salas de cinema da rede.
O domínio deste banco de dados são as seguintes informações:
- id da cidade;
- nome da cidade;
- uf da cidade (sigla string);
- código do país (duas letras, opcional, caso seja uma rede internacional);
- cinemas da cidade;
- id do cinema;
- nome do cinema (geralmente nome da rede + nome do shopping);
- salas de cinema;
- nome da sala;
- sessões;
- data e hora (date);
- id do filme (referente ao banco de filmes);
- nome do filme;
- valor (decimal);
- assentos;
- número do assento;
- disponível (booleano);
Note que já deixei a modelagem desse banco meio tendenciosa com a indentação acima, mas vale alguma discussão do porquê desta estrutura. Primeiro, lembre-se que o objetivo deste banco é fornecer os dados das salas de cinema de uma cidade, fornecendo a agenda e disponibilidade das mesmas, para que o app de cinema permita essas consultas.
Segundo, temos uma série de típicas relações aqui:
- cada país tem N estados (1-N);
- cada estado tem N cidades (1-N);
- cada cidade tem N cinemas (1-N);
- cada cinema tem N salas (1-N);
- cada sala de cinema tem N sessões (1-N);
- cada sessão tem N assentos (1-N);
- cada sessão tem 1 filme (1-1);
Note que em um banco relacional típico, seguindo todas as Formas Normais, teríamos 6 tabelas e 7 relacionamentos. Em MongoDB e mais ainda, em um micro serviço com foco na entrega de informações de salas de cinema, não há a necessidade de quebrarmos em tantas divisões assim. Isso porque a forma como este banco será consultado é bem específica: um usuário irá passar (de forma automática ou manual) a informação da sua cidade para saber as salas de cinema e suas sessões.
Dentro desse contexto, nossa chave com certeza é a informação da cidade e, a partir daí, desenrolamos o restante das informações na proporção de 1-N. Se a informação de cidade por si só não agrega informação ao sistema, ela tranquilamente pode estar atrelada diretamente às demais informações. Caso ela tivesse relevância, seria não apenas o caso de ser outra coleção mas sim outro microservice, focado em locais, certo?
Sendo assim, temos o seguinte schema (que facilmente pode ser modificado depois, afinal estamos falando de MongoDB):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
{ _id: ObjectId("sasacsa85s7sdc7sd"), cidade: "Porto Alegre", uf: "RS", pais: "BR", cinemas: [ { _id: ObjectId("68df5gd5g6ddf"), nome: "Cinemark Bourbon Ipiranga", salas: [ { nome: '1', sessoes: [ { data: ISODate("2018-06-01T09:00:00Z"), idFilme: ObjectId("9ds68dsvdsvs876v"), filme: "Vingadores: Guerra Infinita", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: false }, ] }, { data: ISODate("2018-06-01T11:00:00Z"), idFilme: ObjectId("9ds68dsvdsvs876v"), filme: "Vingadores: Guerra Infinita", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: true }, ] } ] } ] } ] } |
Algumas informações são nomes, como o nome dos filmes, que vamos “repetir” aqui em relação à informação original que fica no outro micro serviço e consequentemente no outro banco de dados. Em bancos relacionais, garantimos a integridade desta informação através da segregação da mesma em uma tabela separada e chaves estrangeiras, no entanto, isso deixa a informação mais custosa de ser obtida de volta (os famosos JOINs).
Assim, em uma abordagem não-relacional deixamos a responsabilidade de garantir a integridade dos nomes para a aplicação. No caso dos nomes dos filmes disponíveis nas sessões, replicamos esta informação para que em listagens simples não seja necessário pedir ao outro microservice, assim, somente temos de ir no movies-service em caso de pegar detalhes de um filme, caso em que usaremos o id do mesmo (que deve ser igual entre todas bases que fizerem referências a filmes). Essa responsabilidade de integridade do nome dos filmes inclusive deve ser uma preocupação nos casos em que o nome tenha de ser atualizado por algum motivo, pois assim ele deverá ser atualizado em mais de um banco, o que gerará mais transtorno do que o normal, mas não é impossível (é o preço que se paga por facilidade nas consultas).
Relações 1-N de entidades simples, como assentos, podem facilmente ser substituídas por campos multivalorados (arrays) e mesmo entidades mais complexas, mas que não fazem sentido existirem de maneira independente, são arrays de subdocumentos.
Uma regra boa de decidir se um documento deve existir de maneira independente como outra coleção ou se deve ser um subdocumento de outro já existente é se lembrar dos conceitos de Agregação e Composição da Orientação à Objetos. Se o objeto seria uma agregação, ou seja, existe de mesmo que o objeto “pai” seja destruído, ele deve ser de outra coleção no MongoDB, caso contrário, faça-o ser um subdocumento do documento “pai”.
E com isso, temos o nosso banco modelado de maneira adequado à forma como ele será utilizado neste micro serviço. Obviamente existem dezenas, se não centenas, de formas diferentes de modelar este banco, mas já temos um bom começo!

#3 – Subindo o banco e conectando
Agora que definimos o schema com o qual iremos trabalhar, vamos subir nossa instância de banco de dados, lembrando que localmente devemos usar outra porta que não a 27017 para não dar conflito com o banco do outro microserviço. Sendo assim, suba sua instância de mongod com o comando abaixo (considerando que o seu terminal está apontando para a pasta bin do MongoDB):
|
1 2 3 |
./mongod --dbpath /pasta-do-seu-microservice/data --port 27018 |
Note que no Windows você apenas digita ‘mongod’ (sem o ./ no início) e que nesse SO o seu caminho até a pasta ‘data’ irá iniciar com ‘C:’ou equivalente, preenchendo todo o caminho até chegar na pasta ‘data’ dentro de cinema-catalog-service.
Agora que temos a instância de MongoDB deste microservice funcionando, vamos nos conectar nele através do utilitário ‘mongo’ passando a porta correta:
|
1 2 3 |
./mongo --port 27018 |
E depois vamos nos conectar no novo banco que deve ser criado:
|
1 2 3 |
use cinema-catalog-service |
Para em seguida podermos adicionar uma carga de dados, como abaixo (essa carga de dados encontra-se no zip do projeto, na pasta ‘config’, que você pode baixar no final deste post). Antes de você copiar e colar o trecho abaixo no seu console, preste muita atenção aos campos ‘idFilme’, substitua o ObjectId passado ali pelo ObjectId do banco movies-service do seu outro microservice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
db.cinemaCatalog.insert([ { cidade: "Gravataí", uf: "RS", cinemas: [] }, { cidade: "Porto Alegre", uf: "RS", pais: "BR", cinemas: [ { _id: ObjectId(), nome: "Cinemark Bourbon Ipiranga", salas: [ { nome: '1', sessoes: [ { data: ISODate("2018-06-01T09:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e57"), filme: "Vingadores: Guerra Infinita", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: false }, ] }, { data: ISODate("2018-06-01T11:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e57"), filme: "Vingadores: Guerra Infinita", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: true }, ] }, { data: ISODate("2018-06-01T13:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e58"), filme: "Vingadores: Era de Ultron", valor: 20.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: false }, { numero: 2, disponivel: true }, ] } ] }, { nome: '2', sessoes: [ { data: ISODate("2018-06-01T09:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e58"), filme: "Vingadores: Era de Ultron", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: false }, ] }, { data: ISODate("2018-06-01T11:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e58"), filme: "Vingadores: Era de Ultron", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: true }, ] }, { data: ISODate("2018-06-01T13:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e58"), filme: "Vingadores: Era de Ultron", valor: 20.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: false }, { numero: 2, disponivel: true }, ] } ] } ] }, { _id: ObjectId(), nome: "GNC Lindóia", salas: [ { nome: '100', sessoes: [ { data: ISODate("2018-06-01T09:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e59"), filme: "Os Vingadores", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: false }, ] }, { data: ISODate("2018-06-01T11:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e59"), filme: "Os Vingadores", valor: 25.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: true }, ] }, { data: ISODate("2018-06-01T13:00:00Z"), idFilme: ObjectId("5aefc5029ce83b1eb6b89e58"), filme: "Vingadores: Era de Ultron", valor: 20.00, assentos: [ { numero: 1, disponivel: true }, { numero: 2, disponivel: false }, { numero: 2, disponivel: true }, ] } ] } ] } ] }]) |
Agora que temos dados populados na nossa coleção ‘cinemas’, vamos configurar nosso arquivo de variáveis de ambiente, .env, para apontar a string de conexão do módulo mongodb.js para a instância de servidor correta:
|
1 2 3 4 5 6 |
#.env, don't commit to repo MONGO_CONNECTION=mongodb://localhost:27018 DATABASE_NAME=cinema-catalog-service PORT=3001 |
Note que defini a porta do servidor de Mongo para 27018, e que já aproveitei para deixar a variável de porta do Express já definida como 3001, visto que a 3000 está ocupada com o movies-service.
Será que nosso database.js já está funcionando com o novo banco? Que tal rodarmos os testes unitários que possuímos para ele? O mesmo vale para os testes do módulo server.js também, já que a porta dele está configurada no .env também. E em nosso package.json, ajuste o script de test para apontar para nosso índice de testes.
No seu terminal, navegue até a pasta raiz do projeto e rode um ‘npm test’ (certifique-se que o package.json está configurado corretamente para rodar os testes) para ver o resultado dos nossos testes:
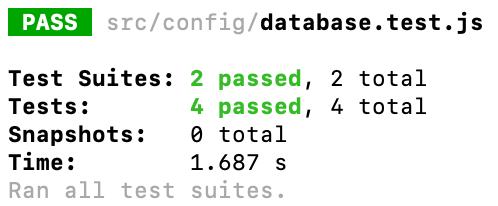
Assim, já temos a garantia que dois dos nossos módulos básicos já estão funcionando!
#4 – Iniciando o Repositório
Agora que temos o banco de dados e o servidor, que tal programarmos o repositório? Mas que funções precisaremos ter nele?
Isso depende do poder que queremos dar aos nossos usuários no front-end. Que tal começarmos com as possibilidades abaixo?
- pesquisar cidades em que a rede possui cinema;
- pesquisar cinemas por id da cidade;
- pesquisar filmes disponíveis em um cinema;
- pesquisar filmes disponíveis em uma cidade;
- pesquisar sessões disponíveis para um filme em uma cidade;
- pesquisar sessões disponíveis para um filme em um cinema;
Com isso, habilitaremos uma usabilidade potencialmente boa para quem for consumir nossa API. Sendo assim abra o seu arquivo cinema-catalog-service/src/repository/repository.js e adicione as três funções mais simples de todas: getAllCities, getCinemasByCityId e disconnect, sendo que esta última é opcional, só serve para os testes unitários:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
//repository.js const database = require("../config/database"); const { ObjectId } = require("mongodb"); async function getAllCities() { const db = await database.connect(); return db.collection("cinemaCatalog").find({}, { cidade: 1, uf: 1, pais: 1 }).toArray(); } async function getCinemasByCityId(cityId) { const objCityId = ObjectId.createFromHexString(cityId); const db = await database.connect(); const cities = await db.collection("cinemaCatalog").find({ _id: objCityId }, { cinemas: 1 }).toArray(); return cities[0].cinemas; } async function disconnect() { return database.disconnect(); } module.exports = { getAllCities, getCinemasByCityId, disconnect } |
Note que não há nada demais nas funções acima que mereçam grandes explicações. Na primeira função usei um projeção, que talvez seja algo novo para você: no segundo parâmetro do find podemos passar quais campos que queremos retornar na consulta, sendo que o padrão é retornar todos (equivalente a um ‘SELECT *’).
Já na segunda função ao invés de jogar o callback diretamente no toArray eu optei por tratá-lo melhor, passando adiante apenas o array de cinemas ao invés do documento inteiro de cidade, facilitando a vida de quem for consumir esta função mais tarde.
Vamos escrever os testes unitários destas três funções?
Crie um arquivo /cinema-microservice/cinema-catalog/src/repository/repository.test.js e coloque o seguinte código de teste dentro dele:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
//repository.test.js require('dotenv-safe').config(); const repository = require('./repository'); let testCityId = null; beforeAll(async () => { const cities = await repository.getAllCities(); testCityId = cities[1]._id;//Porto Alegre }) test('Repository getAllCities', async () => { const cities = await repository.getAllCities(); expect(Array.isArray(cities)).toBeTruthy(); expect(cities.length).toBeGreaterThan(0); }) test('Repository getCinemasByCityId', async () => { const cinemas = await repository.getCinemasByCityId(testCityId); expect(Array.isArray(cinemas)).toBeTruthy(); expect(cinemas.length).toBeGreaterThan(0); }) test('Repository Disconnect', async () => { const isDisconnected = await repository.disconnect(); expect(isDisconnected).toBeTruthy(); }) |
Se você fez todo o microservice anterior à este (o movies-service), já deve estar ‘careca’ de saber como funcionam os testes unitários via Jest. Aqui não há nada de diferente do que já fizemos na outra ocasião, apenas atente ao fato de que deixei uma variável movieId sem uso neste momento, mas que precisaremos mais tarde.
Para rodar este e os demais testes deste microservice, rode o comando ‘npm test’, que deve estar configurado no seu package.json.
Se tudo deu certo você deve ter recebido mensagens positivas nos testes e agora é hora de criar as funções mais avançadas do nosso repositório, que nos exigirão uma série de conceitos novos, principalmente de agregações em MongoDB.
Mas isso fica para a parte 5 da série!
Curtiu o post? Então clica no banner abaixo e dá uma conferida no meu livro sobre microservices com Node.js!









Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.