

Atualizado em 24/10/2021!
Um caso de uso de Node.js muito comum, como já expliquei em outros artigos antes, é o de construção de webapis e microsserviços que aguentam grande carga de requisições. Até aqui, isso não deve ser novidade para você.
No entanto, uma fraqueza do Node (e do JavaScript em geral) é a sua performance não tão boa quando o assunto é processamento pesado e/ou tarefas bloqueantes que demoram um tempo razoável para serem concluídas. Isso no Node.js pode ser um grande ofensor uma vez que o event loop trabalha com single thread, certo? Bloqueie esta thread principal e os demais clientes chamando sua API terão uma experiência bem ruim…
Seja nos casos em que o volume de requisições exceda a sua capacidade de resolvê-las rapidamente ou nos casos em que o processamento seja demorado, adotar uma arquitetura que opere de forma assíncrona não apenas garante que você vai conseguir atender todas requisições como vai fazê-lo em um tempo adequado.
No tutorial de hoje vou falar de como construir uma arquitetura simples, porém robusta, usando Node.js e RabbitMQ para processamento assíncrono de requisições recebidas em uma web API RESTful.

Processamento Assíncrono
O primeiro conceito que você tem de entender é que apesar do HTTP ser síncrono, já faz quase 20 anos que a Internet (e os sistemas que rodam nela) já entendeu que trabalhar de maneira assíncrona é uma forma de proporcionar experiências cada vez melhores aos usuários.
Em uma requisição síncrona, a request é enviada ao servidor, que a processa e devolve uma response. Tudo de uma vez só. Enquanto a response não é retornada, a conexão fica presa e o usuário fica esperando. Se demorar demais, a conexão pode ser encerrada abruptamente e o cliente terá de fazê-la de novo, sem saber exatamente o que acontecer nesta segunda chamada.
Em uma requisição assíncrona, a request é enviada ao servidor, que registra a mesma e automaticamente responde ao cliente que vai realizar a tarefa em breve, avisando-o de alguma maneira quando ela for concluída. Um outro processo cuida de processar essa requisição armazenada e notificar o cliente de alguma forma, se necessário.
A imagem abaixo ilustra um pouco dessa diferença.
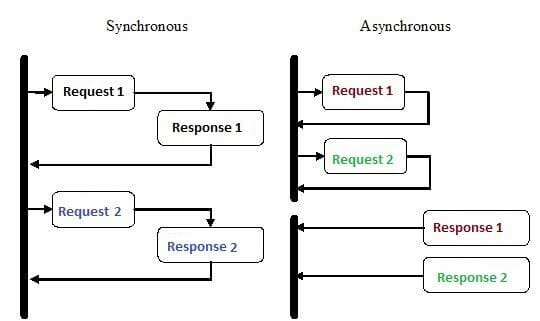
Obviamente o segundo modelo é um pouco mais complexo de lidar, mas possui algumas vantagens muito interessantes.
Enquanto que processamento síncrono dá uma resposta mais direta e rápida para o cliente quando o servidor não está sobrecarregado de requisições, é quando a carga de chamadas às suas APIs é muito alta que ele se mostra inviável. Neste caso, apenas registrar as requisições, para processá-las em uma fila, por exemplo, garante que todos vão ser atendidos, cada um no seu tempo e nenhuma request vai ser dropada.
Assim, pensando nessa arquitetura, eu proponho neste tutorial o uso de RabbitMQ, uma tecnologia gratuita e open-source escrita em Erlang para ser usada como fila para as suas requisições, visando processamento assíncrono pelo Node.js.

RabbitMQ
O MQ no nome do Rabbit vem de Message Queue ou Fila de Mensagens, o que é exatamente o que ele é. O RabbitMQ é hoje a tecnologia de fila mais popular do mercado e fornece integração com todas as tecnologias comerciais mais utilizadas, incluindo aí Node.js. Ele é construído com a linguagem funcional Erlang e implementando o protocolo AMQP (Advanced Message Queue Protocol ou Protocolo Avançado de Filas de Mensagens).
Um dos possíveis casos de uso do RabbitMQ é a construção de arquiteturas para processamento assíncrono usando o padrão Producer/Consumer (Produtor/Consumidor), onde de um lado eu vou ter um produtor que envia mensagens pra uma fila (queue) e de outro lado um consumidor que é notificado que uma nova mensagem chegou, para processá-la. Existem arquiteturas mais complexas possíveis de serem feitas, com N para N, mas meu intuito aqui é manter simples neste primeiro momento.
Para efeitos mais práticos e simples, imagine que de um lado eu tenho uma API (producer) que recebe uma grande carga de requisições, ela enfileira essas requisições no Rabbit e um worker (consumer) vai processando essas mensagens uma a uma, conforme ele vai conseguindo dar conta.
A imagem abaixo ilustra uma possibilidade como essa, onde aquele canal no meio é onde fica o RabbitMQ.

Para rodar o RabbitMQ na sua máquina você vai precisar ter o Erlang instalado e depois pode baixar o Rabbit e executá-lo via linha de comando mesmo. A área de downloads dá as melhores instruções para instalação conforme o seu sistema operacional.
Com tudo instalado, eu costumo subir um servidor de filas do Rabbit usando o utilitário rabbitmq-server dentro da pasta sbin, como no comando abaixo (em Windows ajuste o path do cd e você não precisa do ./ no início do comando também)
|
1 2 |
cd /pasta-aplicacoes/rabbitmq-3.8.1/sbin ./rabbitmq-server |
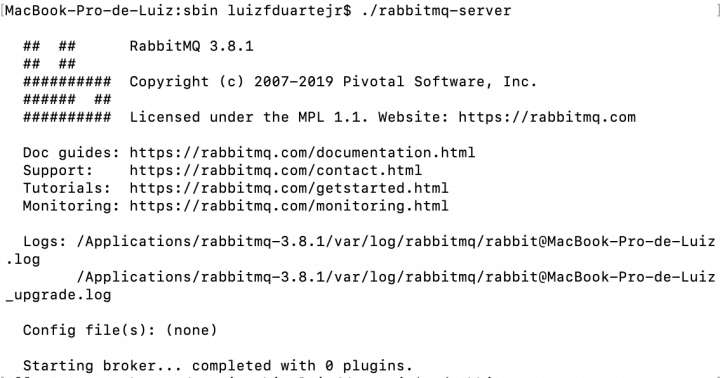
Quando o servidor sobe corretamente você deve ver algo parecido com a imagem abaixo no seu terminal.
Cliente RabbitMQ em Node.js
O RabbitMQ possui clientes nas mais variadas tecnologias, incluindo Node.js como já mencionei antes. Uma vez com o servidor do RabbitMQ rodando, crie uma nova pasta e rode um npm init para iniciar um novo projeto Node.js nela.
Você tem de instalar as seguintes dependências no seu projeto:
- express
-
amqplib
Vamos criar um módulo JavaScript que vai encapsular a nossa lógica de produzir e consumir mensagens, bem como de criar a fila no Rabbit. Esse módulo depois será usado pela webapi e pelo worker (note que uso promises aqui).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
//queue.js function connect(){ return require('amqplib').connect("amqp://localhost") .then(conn => conn.createChannel()); } function createQueue(channel, queue){ return new Promise((resolve, reject) => { try{ channel.assertQueue(queue, { durable: true }); resolve(channel); } catch(err){ reject(err) } }); } function sendToQueue(queue, message){ connect() .then(channel => createQueue(channel, queue)) .then(channel => channel.sendToQueue(queue, Buffer.from(JSON.stringify(message)))) .catch(err => console.log(err)) } function consume(queue, callback){ connect() .then(channel => createQueue(channel, queue)) .then(channel => channel.consume(queue, callback, { noAck: true })) .catch(err => console.log(err)); } module.exports = { sendToQueue, consume } |
Esse módulo é bem simples, possui 4 funções e expõe apenas duas, uma que vai ser usada pelo producer (sendToQueue) e outra pelo consumer (consume).
A primeira função, connect, é autoexplicativa, ela carrega a dependência do pacote amqplib e conecta-se na URL do servidor RabbitMQ, retornando o canal de comunicação. Essa função é usada pelas demais e é a recomendação, abrir sempre o canal de comunicação para garantir que não terá problemas com conexão.
A segunda função createQueue, é chamada pelas outras duas para garantir a existência, mas não se preocupe pois ela é idempotente, ou seja, depois de criada, ela não criará repetida e nem dará erro de que já existe. É mais uma recomendação de boa prática.
A terceira função, sendToQueue, será usada pelo producer (webapi) e na minha implementação ele está esperando um objeto JSON como argumento da função, sendo que ele serializa o mesmo para ser enviado ao Rabbit. Você pode ter várias filas diferentes, então esta função espera como argumento o nome da fila onde você vai adicionar essa mensagem.
E por fim, a função consume, que será usada pelo consumer (worker). Essa função espera um callback que é a função do cliente dessa lib que vai ser disparada toda vez que entrar uma mensagem nova na fila, é a função que vai processar a requisição agendada.
Atenção: sim, você tem de usar um callback ali, a lib foi construída dessa forma pois ela tem um segundo callback no final, ou seja, não dá para usar promises ou async/await para tratar aquele callback do meio da função. Documentação oficial com exemplo de código e arquivo que mostra o fonte e dá para entender porque usar promise ou async/await não terá o resultado esperado.
Agora vamos criar o produtor e o consumidor.

Produtor e Consumidor
Nossa API de exemplo será muito simples, uma vez que o objetivo aqui não é ensinar a criar webapis. Apenas copie e cole o código abaixo em um arquivo webapi.js na raiz do projeto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
//webapi.js const express = require('express'); const app = express(); const queue = require("./queue"); app.use(express.json()); const router = express.Router(); router.post('/task', (req, res) => { queue.sendToQueue("fila1", req.body); res.json({message: 'Your request will be processed!'}); }); app.use('/', router); app.listen(3000); |
Essa API espera um POST em um endpoint /task com um JSON no body da requisição. Ela apenas pega esse body e joga pra fila.
Da mesma forma, nosso worker de exemplo será muito simples, uma vez que não é o foco do artigo. Apenas copie e cole o código abaixo em um arquivo worker.js na raiz do projeto:
|
1 2 3 4 5 6 7 |
//worker.js console.log("worker started"); const queue = require("./queue"); queue.consume("fila1", message => { //process the message console.log("processing " + message.content.toString()); }) |
Esse worker é muito simples, ele apenas fica escutando a fila1 (a mesma em que o producer vai jogar as mensagens) e quando chega alguma coisa lá, o callback pega a mensagem e apenas imprime o conteúdo no console.
Testando e Além
Uma vez que você já tenha o servidor de RabbitMQ rodando, testar é muito simples, basta subir a webapi via terminal e depois subir o worker em outro terminal, em qualquer ordem.
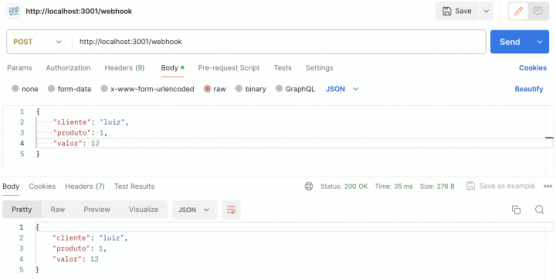
Você deve começar o teste pelo producer, ou seja, abra o POSTMAN e envie um objeto JSON qualquer via POST para localhost:3000/task que isso deve disparar a mensagem pra fila que deve ser consumida pelo worker quase imediatamente.
Claro, este é um consumer meeega simples. Consumers reais vão processar dados da mensagem, fazer operações em banco e até mesmo chamar outras APIs se necessário, principalmente para avisar que essa requisição já foi processada. Você pode querer também alterar a interface para dar uma resposta ao usuário e por aí vai.
Você pode ainda explorar mais possibilidades desta arquitetura como o padrão com múltiplos consumers concorrentes (1xN) ou ainda o padrão Pub-Sub (Publish/Subscribe) onde podemos ter uma relação de NxN.
Mas enfim, a ideia deste artigo era te ajudar a fazer o Rabbit funcionar com Node.js e espero que você tenha conseguido. Caso contrário, apenas baixe os meus fontes usando o formulário ao final do tutorial.
Um concorrente do RabbitMQ que é mais fácil de usar mas que é pago, é o AWS SQS, que ensino a utilizar neste tutorial.
Outra boa dica é paralelizar a capacidade da sua web API de fazer múltiplas atividades e uma forma de fazer isso é usando Node Cluster.
Até a próxima!
Curtiu o post? Então clica no banner abaixo e dá uma conferida no meu curso sobre programação web com Node.js!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.