

Este artigo é uma continuação do tutorial de Webscrapping com Node.js que escrevi outro dia. Crawlers e webscrappers são peças fundamentais para a construção de mecanismos de busca e já há algum tempo que estava para escrever sobre eles a pedido de leitores e amigos.
Isso porque crio tais bots desde 2010, desde que comecei o projeto do Busca Acelerada pela primeira vez e de lá para cá não parei, tendo lançado diversos projetos para diversas empresas (como o BuildIn para a Softplan), e até mesmo alguns projetos pessoais (como o SóFamosos).
Mas por que um segundo tutorial sobre o mesmo assunto? Não ensinei tudo que tinha de ensinar no primeiro?
Quase. E neste tutorial vou explicar o problema com aquele primeiro webscrapper e mostrar outra alternativa.
Se preferir, pode assistir ao vídeo abaixo, tem o mesmo conteúdo.

Vamos lá!
O grande problema do webscrapping
O webscrapper que ensinei a criar no tutorial anterios é bem básico e sofre de alguns males bem comuns que quem já deve ter feito webscrapping antes deve conhecer: execução de scripts que tornam o HTML dinâmico.
Claro, existem outros problemas também, como o bloqueio do bot após crawling excessivo, mas considerando que quase a totalidade dos sites atuais possuem execução de scripts para tornar suas páginas dinâmicas (usando libs e frameworks como React, Angular e Vue), é quase certo que você mais cedo ou mais tarde terá problemas com o seu webscrapper enxergando um HTML x e você no navegador enxergando um HTML y, o que dificultará seu trabalho de capturar os dados corretamente.
Explicando melhor: quando você acessa um site via servidor, usando um script como o webscrapper do post anterior, você não executa o código front-end da página, não manipula o DOM final, não dispara as chamadas JS, etc. O seu robô apenas lê as informações que foram geradas no servidor do site-alvo, o que pode fazer com que seu robô nem tenha nada de útil pra ler na página caso a mesma seja uma SPA (Single Page Application) por exemplo.
A solução: Headless Browsers!
Os browsers web como conhecemos possuem 3 tarefas principais:
- dada uma URL, acessar uma página HTML (funcionalidade principal, o tronco do browser);
- carregar o DOM e executar os scripts front-end (os membros);
- renderizar visualmente o DOM (a cabeça);
Os primeiros browsers antigos, que eram em modo texto, só faziam o primeiro item. O browser que você está usando pra ler este post faz os três. Um headless browser faz somente os dois primeiros, ou seja, ele apenas não possui uma interface gráfica, mas carrega o HTML, o DOM e executa todos os scripts de front-end.
Esse tipo de browser é como se fosse um console application rodando em modo silencioso, apenas um processo no seu sistema operacional que age como um browser. No fundo ele é um browser, apenas não tem UI.
Muito útil para testes automatizados de interface, é comum os headless browsers exporem bibliotecas de manipulação do DOM como JQuery para permitir que através de scripts o programador consiga usar a página carregada pelo headless browser, como executar cliques em botões, preencher campos, etc; tudo isso sem estar enxergando uma UI ou sequer estar usando mouse e teclado.
Não é preciso ser um gênio para entender que podemos usar headless browsers para fazer webscrapping, certo? Com esse tipo de tecnologia conseguiremos que nosso bot leia a versão final do HTML, da mesma forma que um usuário “veria” no navegador, após a execução dos scripts de front-end. Não apenas isso, mas você consegue fazer com que seu bot não apenas leia conteúdo, mas que use a página em si, clicando em botões e selecionando opções, por exemplo.
Se DOM, HTML, front-end e outros termos utilizados aqui não forem de seu domínio, dificilmente você conseguirá criar um crawler realmente bom. Em meu livro de Programação Web com Node.js, cubro estes e outros aspectos essenciais da programação web, caso te interesse.

Escolhendo um headless browser
Existem diversas opções de headless browsers no mercado. A maioria é open-source e baseada no Webkit, a mesma base na qual o Apple Safari e o Google Chrome foram construídos, o que garante uma grande fidelidade em relação ao uso de web browser comuns para carregar o HTML+JS.
Algumas opções disponíveis são:
Destes, o SlimerJS usa a plataforma Gecko da Mozilla ao invés do Webkit, enquanto que o PhantomJS e o HtmlUnit são famosos por se integrarem ao Selenium, uma popular ferramenta de automação de testes. Além disso, o Phantom é o único que eu usei profissionalmente em uma startup que trabalhei que usava este headless browser para tirar screenshots de páginas web.
No entanto, meu intuito de escrever este post era justamente para aprender a usar outro headless browser que não o Phantom, pois este possui alguns problemas conhecidos como não-conformidade com ES6, obrigatoriedade de uso do JQuery e nenhuma novidade desde 2018 (o projeto está parado). Esses problemas (que não são o fim do mundo, mas que me motivaram a buscar outra tecnologia) são comentados neste excelente post do Matheus Rossi. Então se você realmente quer aprender a usar o PhantomJS, leia o post que acabei de citar.
Uma coisa que descobri recentemente é que desde a versão 59 do navegador Google Chrome que foi disponibilizada a opção de rodar o navegador do Google sem a interface gráfica funcionando, em modo headless. Usar o Chrome em modo headless é o sonho de muito testador por aí, pois representa rodar scripts de testes automatizados no navegador mais popular do mundo, com a maior fidelidade possível em relação ao que o usuário final vai usar.
Certo, headless browser escolhido, como fazer um webscrapper que use-o para carregar o mesmo DOM que um usuário do Chrome veria?

Manipulando o headless browser via Node.js
No mesmo Github do Google Chrome existe um projeto chamado Puppeteer, que em uma tradução livre seria um manipulador de marionetes, ou um mestre dos fantoches. Ele é essencialmente um módulo Node.js que permite manipular tanto o Headless Chrome quanto o Chrome “normal” para fazer tarefas como:
- gerar screenshots e PDFs de páginas web;
- fazer crawling em cima de páginas com Ajax e SPAs;
- automatizar o uso de UIs web;
- fazer webscrapping com alta fidelidade;
Para que o Puppeteer funcione você precisa ter o Node.js instalado na sua máquina. Também costumo utilizar o VS Code para escrever os códigos, ensino a instalar estas duas ferramentas no vídeo abaixo.

Depois que tiver o Node instalado, vamos criar um novo projeto Node.js chamado webscrapper2, criar um index.js vazio dentro dele, navegar via terminal até essa pasta e rodar um ‘npm init -y’ para configurá-lo com as opções default.
Se você nunca programou em Node.js antes, sugiro começar pelos tutoriais mais iniciantes de meu blog ou mesmo pelo meu livro, que pega o iniciante pela mão e ensina desde JS tradicional até diversos módulos do Node.
Agora rode o comando abaixo para instalar o Puppeteer no seu projeto, sendo que ele automaticamente irá baixar sua própria versão do Chrome, independente se você já possuir uma (ou seja, a instalação irá demorar um pouco mais que o normal para módulos NPM):
|
1 2 3 |
npm install puppeteer |
Usá-lo é muito simples, no seu index.js, inclua o seguinte código que representa a estrutura básica do nosso webscrapper:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
const puppeteer = require('puppeteer'); async function scrap() { const browser = await puppeteer.launch({ headless: "new" }); const page = await browser.newPage(); await page.goto('http://books.toscrape.com/'); await page.waitForNetworkIdle(); // Scrap browser.close(); console.log(result); return result; }; scrap(); |
Na primeira linha carregamos a dependência do módulo puppeteer. No bloco seguinte, criamos a função assíncrona que fará todo o trabalho de verdade, com a lógica de acesso à página e scrapping (comentado).
Neste primeiro momento, essa função scrap apenas executa o Headless Chrome, acessa uma nova página com a URL de um site fake de livros e espera até que a rede se acalme (idle, páre de fazer ou esperar requisições) antes de se fechar. Ainda não há a lógica de scrapping aqui.
No bloco final, executamos a função e quando ela terminar, o valor retornado pela função scrap será impresso no console. Se você executar o projeto agora, terá um erro de que result está undefined, mas isso é esperado já que sequer declaramos ele em lugar algum, mas o teste é válido pois te mostrará que passou por todas as linhas anteriores com sucesso.
Antes de fazer a versão completa da função scrap, temos de entender o que vamos capturar de informações da página em questão.

Fazendo HTML Scrapping
O site Books to Scrape serve para o único propósito de ajudar desenvolvedores a praticar webscrapping. Ele mostra um catálogo de livros, como na imagem abaixo:
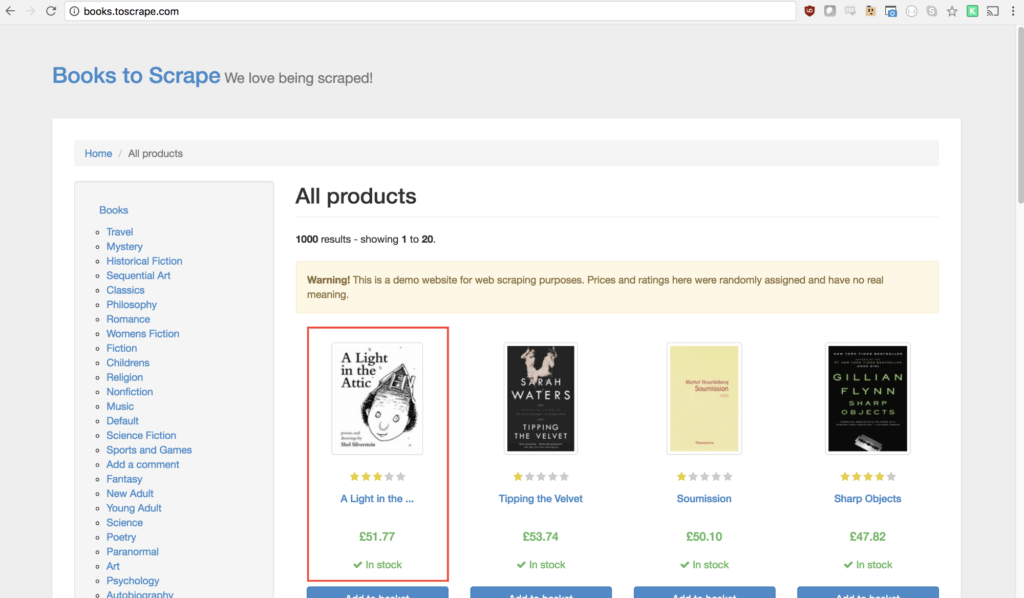
Acesse ele no seu navegador Chrome e com o clique direito do mouse sobre a área do primeiro livro da listagem, mais especificamente sobre o título dele e selecione a opção Inspecionar/Inspect.
Isso irá abrir a aba Elements do Google Developer Tools onde você poderá entender como construir um seletor que diga ao seu web scrapper onde estão os dados que ele deve ler. Neste caso, vamos ler apenas os nomes dos livros. Se você não está acostumado com CSS e/ou seletores (no melhor estilo JQuery), você pode usar o recurso Copy > Selector que aparece no painel elements para gerar o seletor para você, como mostra a imagem abaixo.
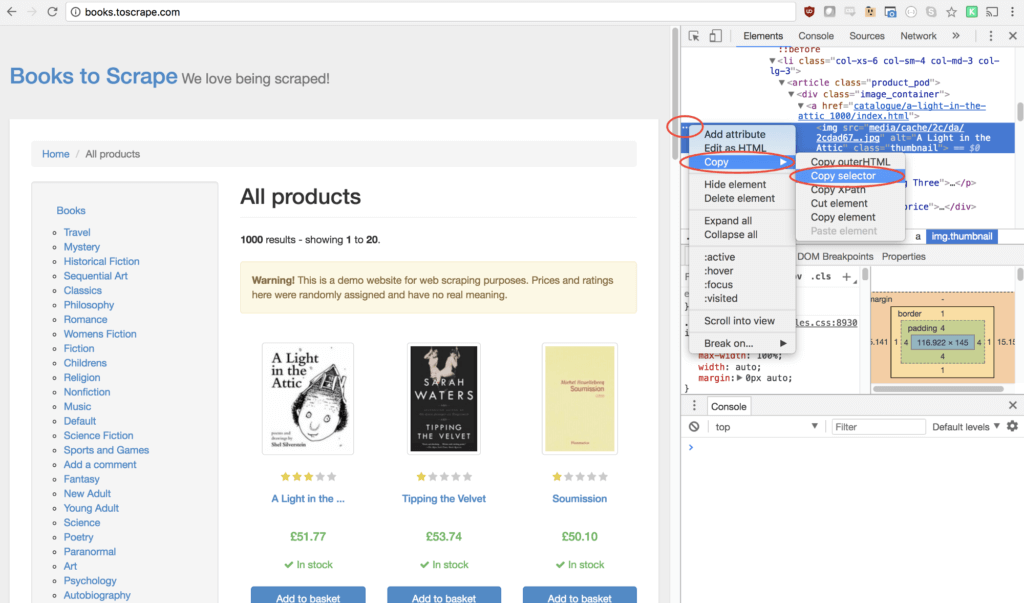
Nesse caso específico não usarei a sugestão do Chrome que é bem engessada. Usarei um seletor bem mais simples: “h3 > a”, ou seja, vou pegar o link/âncora de cada H3 do HTML dessa página. Os H3 dessa página são exatamente os títulos dos livros.
Se analisarmos em detalhes este bloco que queremos extrair o título, veremos que o texto interno da âncora nem sempre é o título fiel pois, por uma questão de espaço, algumas vezes ele está truncado com reticências no final. Sendo assim, o atributo HTML que vamos ler com o scraper é o title da âncora, que esse sim sempre possui o título completo.
Vamos atualizar nosso código de scrapping para pegarmos esta informação:
|
1 2 3 4 5 6 |
//scrap const result = await page.evaluate(() => { return document.querySelector('h3 > a').title }) |
Analisando apenas o bloco de código de scrapping, criamos uma função que executa um código JavaScript sobre a página que carregamos. A execução de scripts é realizada usando a função evaluate. Nesse código JavaScript, estamos usando a função querySelector no documento e o seletor que criamos anteriormente para acessar um componente do DOM da página. Sobre este componente, queremos o seu atributo title.
Se você rodar este código Node agora verá que ele retornará apenas o nome do primeiro livro, “A Light in the Attic”. Isso porque a função querySelector retorna apenas o primeiro componente que ela encontra com aquele seletor.
O código abaixo resolve isso:
|
1 2 3 4 5 6 7 8 |
//scrap const result = await page.evaluate(() => { const books = []; document.querySelectorAll('h3 > a').forEach(book => books.push(book.title)); return books }); |
Aqui, usei a querySelectorAll, sobre a qual apliquei um forEach. Para cada livro encontrado com aquele seletor, eu adiciono o title do livro em um array de livros, retornado ao fim do evaluate.
Com isso, se você executar novamente este script verá que ele retorna o título de todos os livros da primeira página do site, concluindo este post.
Qual seria o próximo passo? Navegar pelas demais páginas, coletando os títulos dos outros livros. Esta é a tarefa principal de um webcrawler ou webspider: crawl (rastejar). Ao algoritmo de webscrapping cabe apenas coletar os dados. Mas esse desagio eu deixo para você.
Até a próxima!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.
Luiz, tudo bem?
Estou atrás de um script que submeta vários formulários em várias páginas diferentes e busque um pdf que está abaixo deles.
Não sei se isso é um scrapper, um bot, uma macro… só sei que não consigo achar nada no npm que consiga me ajudar no trabalho de submeter o form e recuperar o binário. O tratamento do pdf acho que consigo sozinho 🙂
Pode me dar uma dica?
Submissão de formulários você consegue fazer tanto via cheerio (parte 1 desse post) quanto via Puppeteer (nesse post). Não está funcionando pra você? Claro, nunca fiz pra receber PDF de volta do POST, mas imagino que deva funcionar normalmente.
Eu acompanho seu blog desde o post Node + Mysql e comi bola no primeiro artigo. Vou verificar.
Valeu!