

Enquanto estudava Node.js me deparei com um elemento chave que não temos como ignorar quando o assunto é essa tecnologia. Estou falando do Event Loop.
Grande parte das características e principalmente das vantagens do Node.js se devem ao funcionamento do seu loop single-thread principal e como ele se relaciona com as demais partes do Node, como a biblioteca C++ libuv.
Assim, a ideia deste artigo é ajudar você a entender como o Event Loop do Node.js funciona, o que deve lhe ajudar a entender como tirar o máximo de proveito dele.
Vamos ver neste artigo:
Você pode acompanhar este conteúdo através do vídeo abaixo, o conteúdo é o mesmo.

O problema
Antes de entrar no Event Loop em si, vamos primeiro entender porque o Node.js possui um e qual o problema que ele propõe resolver.
A maioria dos backends por trás dos websites mais famosos não fazem computações complicadas. Nossos programas passam a maior parte do tempo lendo ou escrevendo no disco, ou melhor, esperando a sua vez de ler e escrever, uma vez que é um recurso lento e concorrido. Quando não estamos nesse processo de ir ao disco, estamos enviando ou recebendo bytes da rede, que é outro processo igualmente demorado. Ambos processos podemos resumir como operações de I/O (Input & Output) ou E/S (Entrada & Saída).
Processar dados, ou seja executar algoritmos, é estupidamente mais rápido do que qualquer operação de IO que você possa querer fazer. Mesmo se tivermos um SSD em nossa máquina com velocidades de leitura de 200-730 MB/s fará com que a leitura de 1KB de dados leve 1.4 micro-segundos. Parece rápido? Saiba que nesse tempo uma CPU de 2GHz consegue executar 28.000 instruções.
Isso mesmo. Ler um arquivo de 1KB demora tanto tempo quanto executar 28.000 instruções no processador. É muito lento.
Quando falamos de IO de rede é ainda pior. Faça um teste, abra o CMD e execute um ping no site do google.com, um dos mais rápidos do planeta:
|
1 2 3 4 5 6 |
$ ping google.com 64 bytes from 172.217.29.78: icmp_seq=0 ttl=52 time=25.753 ms 64 bytes from 172.217.29.78: icmp_seq=1 ttl=52 time=28.658 ms 64 bytes from 172.217.29.78: icmp_seq=2 ttl=52 time=19.592 ms |
A latência média nesse teste é de 24 milisegundos. Ou seja, enviar um ping de 64 bytes para o Google demora o mesmo tempo que uma CPU necessita para executar 480 milhões de operações.
Ou seja, quando estamos fazendo uma chamada a um recurso na Internet, poderíamos estar fazendo até 480 milhões de coisas diferentes na CPU.
É muita diferença!
A solução
A maioria dos sistemas operacionais lhe fornece mecanismos de programação assíncrona, o que permite que você mande executar tarefas concorrentes que não ficam esperando uma pela outra, desde que uma não precise do resultado da outra, é claro.
Esse tipo de comportamento pode ser alcançado de diversas maneiras, sendo a forma mais comum de fazer isso é através do uso de threads o que geralmente torna nosso código muito mais complexo. Por exemplo, ler um arquivo em Java é uma operação bloqueante, ou seja, seu programa não pode fazer mais exceto esperar a comunicação com a rede ou disco terminar. O que você pode fazer é iniciar uma thread diferente para fazer essa leitura e mandar ela avisar sua thread principal quando a leitura terminar.
Novas formas e programação assíncrona tem surgido com o uso de interfaces async como em Java e C#, mas isso ainda está evoluindo. Por ora isso é entediante, complicado, mas funciona. Mas e o Node? A característica de single-thread dele obviamente deveria representar um problema uma vez que ele só consegue executar uma tarefa de um usuário por vez, certo? Quase.
O Node usa um princípio semelhante ao da função setTimeout(func, x) do Javascript, onde a função passada como primeiro parâmetro é delegada para outra thread executar após x milisegundos, liberando a thread principal para continuar seu fluxo de execução. Mesmo que você defina x como 0, o que pode parecer algo inútil, isso é extremamente útil pois força a função a ser realizada em outra thread imediatamente.
Vamos falar melhor dessa solução na sequência.

Node.js Event Loop
Sempre que você chama uma função síncrona (i.e. “normal”) ela vai para uma “call stack” ou pilha de chamadas de funções com o seu endereço em memória, parâmetros e variáveis locais. Se a partir dessa função você chamar outra, esta nova função é empilhada em cima da anterior (não literalmente, mas a ideia é essa). Quando essa nova função termina, ela é removida da call stack e voltamos o fluxo da função anterior. Caso a nova função tenha retornado um valor, o mesmo é adicionado à função anterior na call stack. Falo mais sobre esse gerenciamento de memória no vídeo abaixo.

Mas o que acontece quando chamamos algo como setTimeout, http.get, process.nextTick, ou fs.readFile? Estes não são recursos nativos do V8, mas estão disponíveis no Chrome WebApi e na C++ API no caso do Node.js.
Vamos dar uma olhada em uma aplicação Node.js comum – um servidor escutando em localhost:3000. Após receber a requisição, o servidor vai tentar acessar outro site para ver se ele está “up” e imprimir algumas mensagens no console, retornando a resposta HTTP ao término de tudo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import axios from 'axios'; function getLuizToolsHome(response) { axios.get("https://www.luiztools.com.br") .then(({ data }) => { response.send(data); console.log("LuizTools' up!"); }) .catch(err => { console.log("LuizTools' down"); return response.status(500).send('Erro ao acessar o site.'); }) console.log('Acessando o site, aguarde...'); } function sayHi() { console.log('Hi'); } import express from "express"; const app = express(); app.get('/', (req, res) => { getLuizToolsHome(res); sayHi(); }); app.listen(3000, () => console.log("Servidor executando na porta 3000")); |
O que será impresso no terminal quando uma requisição é enviada para localhost:3000?
Se você já mexeu um pouco com Node antes, não ficará surpreso com o resultado, pois mesmo que console.log(‘Acessando o site, aguarde…’) tenha sido chamado depois de console.log(“LuizTools’ up!”) no código, o resultado da requisição será como abaixo:
|
1 2 3 4 5 |
Acessando o site, aguarde... Hi LuizTools' up! |
O que aconteceu? Mesmo o V8 sendo single-thread, a API C++ do Node não é. Isso significa que toda vez que o Node for solicitado para fazer uma operação bloqueante, Node irá chamar a libuv que executará concorrentemente com o Javascript em background. Uma vez que esta thread concorrente terminar ou jogar um erro, o callback fornecido será chamado com os parâmetros necessários.
A libuv é um biblioteca C++ open-source usada pelo Node em conjunto com o V8 para gerenciar o pool de threads que executa as operações concorrentes ao Event Loop single-thread do Node. Ela cuida da criação e destruição de threads, semáforos e outras “magias” que são necessárias para que as tarefas assíncronas funcionem corretamente. Essa biblioteca foi originalmente escrita para o Node, mas atualmente outros projetos a usam também.
Resumindo: o Event Loop funciona em single thread, mas existe sim um pool de threads em background processando de maneira paralela as requisições, quando necessário (I/O Bloqueante).

Task/Event/Message Queue
Javascript é uma linguagem single-thread orientada a eventos. Isto significa que você pode anexar gatilhos ou listeners aos eventos e quando o respectivo evento acontece, o listener executa o callback que foi fornecido.
Como vimos anteriormente, toda vez que você chama setTimeout, http.get ou fs.readFile, Node.js envia estas operações para a libuv executá-las em uma thread separada do pool, permitindo que o V8 continue executando o código na thread principal. Quando a tarefa termina e a libuv avisa o Node disso, o Node dispara o callback da referida operação.
No entanto, considerando que só temos uma thread principal e uma call stack principal, onde que os callbacks ficam guardados para serem executados? Na Event/Task/Message Queue, ou o nome que você preferir. O nome ‘event loop’ se dá à esse ciclo de eventos que acontece infinitamente enquanto há callbacks e eventos a serem processados na aplicação.
Em nosso exemplo anterior, de acesso a um site, nosso event loop ficou assim:
- Express registrou um handler para o evento ‘request’ que será chamado quando uma requisição chegar em ‘http://localhost:3000/’
- ele começa a escutar na porta 3000
- a stack está vazia, esperando pelo evento ‘request’ disparar
- quando a requisição chega, o evento dispara e o Express chama o handler anônimo da rota ‘GET /’
- o handler anônimo é empilhado na call stack
- getLuizToolsHome é chamado dentro da função anterior e é também empilhado na call stack
- axios.get é chamado e definimos o handler/callback para o evento de término da requisição.
- a requisição HTTP para https://www.luiztools.com.br é enviada para uma thread em background e a execução continua;
- ‘Acessando o site, aguarde.’ é impresso no console e getLuizToolsHome retorna
- sayHi é chamada, ‘Hi’ é impresso no console
- o handler anônimo do Express retorna, é retirado da call stack, deixando-a vazia
- ficamos esperando pela chamada de https://www.luiztools.com.br nos responder
- uma vez que a resposta chegue, o evento de ‘then’ é disparado
- o handler anônimo que passamos para .then() é chamado, é colocado na call stack com todos as variáveis locais, o que significa que ele pode ver e modificar os valores de response, axios, app e todas funções que definimos
- response.send() é chamado com um status code de 200 ou 500, mas isso também é executado em uma thread do pool para a stream de respostas não fique bloqueada e o handler anônimo é retirado da pilha.
E é assim que tudo funciona!
Vale salientar que por padrão o pool de threads da libuv inicia com 4 threads concorrentes e que isso pode ser configurado conforme a sua necessidade.

Microtasks e Macrotasks
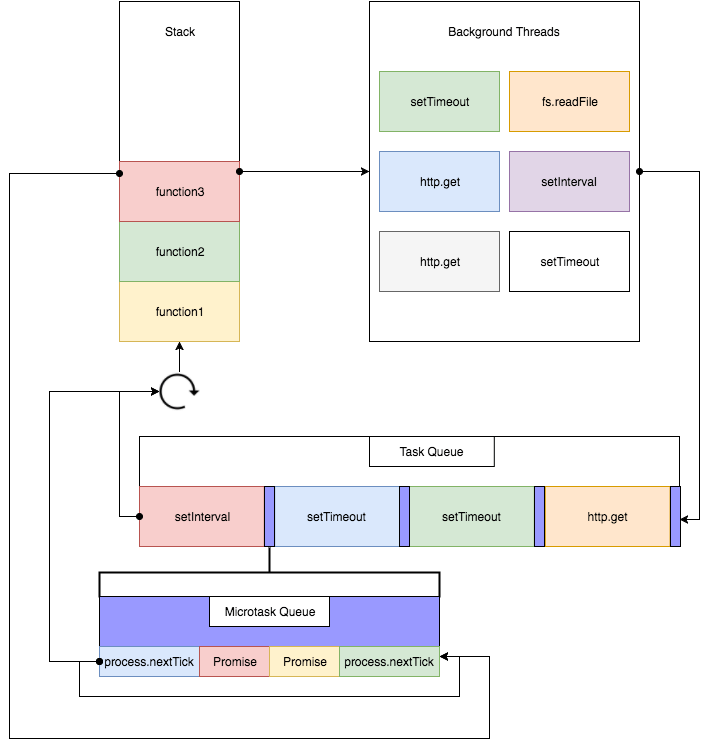
Além disso, como se não fosse o bastante, nós temos duas task queues, não apenas uma. Uma task queue para microtasks e outra para macrotasks.
Exemplos de microtasks
- process.nextTick
- promises
- Object.observe
Exemplos de macrotasks
- setTimeout
- setInterval
- setImmediate
- I/O
Para mostrar isso na prática, vamos dar uma olhada no seguinte código (note que uso promises aqui):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
console.log('script iniciando') const interval = setInterval(() => { console.log('setInterval') }, 0) setTimeout(() => { console.log('setTimeout 1') Promise.resolve().then(() => { console.log('promise 3') }).then(() => { console.log('promise 4') }).then(() => { setTimeout(() => { console.log('setTimeout 2') Promise.resolve().then(() => { console.log('promise 5') }).then(() => { console.log('promise 6') }).then(() => { clearInterval(interval) }) }, 0) }) }, 0) Promise.resolve().then(() => { console.log('promise 1') }).then(() => { console.log('promise 2') }) |
a saída no console é:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
script iniciando promise1 promise2 setInterval setTimeout1 promise3 promise4 setInterval setTimeout2 promise5 promise6 |
De acordo com a especificação da WHATWG, uma macrotask deve ser processada da macrotask queue em um ciclo do event loop. Depois que essa macrotask terminar, todas as microtasks existentes são processadas dentro do mesmo ciclo. Se durante este processamento de microtasks novas microtasks surgirem, elas são processadas também, até a microtask queue ficar vazia.
Este diagrama do site Rising Stack ilustra bem o event loop completo:
Conclusões
Como você pôde ver, se quisermos ter total controle de nossas aplicações Node.js devemos prestar atenção nestes detalhes de como as tarefas são executadas dentro do event loop, principalmente para não bloquearmos sua execução sem querer.
O conceito do event loop pode ser um tanto complicado no início mas uma vez que você entender seu funcionamento na prática você não conseguirá mais imaginar sua vida sem ele. Obviamente o uso intenso de callbacks é muito chato de gerenciar por isso o recomendado é usar Promises em nossos códigos Javascript ou Async/Await que permitem deixar as tarefas assíncronas mais inteligíveis.
Outra dica é que você também pode enviar seus processamentos longos (mas que não são operações de IO), que normalmente seriam executados na thread principal para as threads em background usando recursos como filas (RabbitMQ, AWS SQS, etc).
Uma última dica é que você pode paralelizar o seu event loop fazendo forks nele, com Node Cluster:

Recomendo agora colocar a mão na massa com esse tutorial de Node.js com MongoDB que preparei pra você!






Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.