

Nos últimos anos JavaScript deixou de ser uma linguagem satélite para se tornar o core de muitos projetos de tecnologia. Cada vez mais desenvolvedores têm adotado esta tecnologia não apenas para o front mas para o backend, fazendo-a se tornar a linguagem mais popular do mundo segundo o StackOverflow ou a #7 segundo o Tiobe (ao que parece a galera de JS usa muito o StackOverflow, hehe).
JavaScript é uma linguagem simples de aprender o básico (Stanford que o diga!) e em conjunto com Node.js lhe permite construir todo o tipo de aplicação.
No entanto, dominar JavaScript e Node.js não é tão simples assim e, no artigo de hoje, quero trazer 6 truques/dicas/segredos de performance para você aplicar em seus projetos Node.js.
As dicas que veremos são:
- Faça caching
- Tenha índices
- Arquitetura Assíncrona
- Use protocolos modernos
- Use um cluster
- Monitore sua aplicação
Se preferir, você pode conferir estas mesmas dicas no vídeo abaixo.

#1 – Faça caching
O uso de uma camada de cache na sua aplicação ajuda e muito a ganhar velocidade no acesso a dados recorrentes que os usuários solicitam e/ou que a aplicação precisa e uma das formas mais usadas de mecanismo de caching com Node.js é o Redis. Se preferir, você pode assistir ao vídeo abaixo onde mostro a diferença de performance em ação.
Redis é um mecanismo de armazenamento em memória que pode ser usado como base de dados, cache e message broker. Ele suporta estruturas de dados como strings, hashes, listas, conjuntos, conjuntos ordenados, bitmaps, logs, índices geoespaciais e streams de dados. Em outra oportunidade, quero trazer um tutorial de Redis para vocês.
Por enquanto, compare o código abaixo sem usar Redis. É um cliente que consome a API de livros do Google, sempre indo na mesma pegar os livros:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
'use strict'; //dependências const express = require('express'); const responseTime = require('response-time') const axios = require('axios'); var app = express(); //cria um middleware pra capturar o tempo de resposta app.use(responseTime()); const getBook = (req, res) => { let isbn = req.query.isbn; let url = `https://www.googleapis.com/books/v1/volumes?q=isbn:${isbn}`; axios.get(url) .then(response => { let book = response.data.items res.send(book); }) .catch(err => { res.send('Book not found !!!'); }); }; app.get('/book', getBook); app.listen(3000, function() { console.log('Servidor na porta 3000!') }); |
A performance desse código não é ruim, leva pouco menos de 1s para ir no Google pegar esta informação:
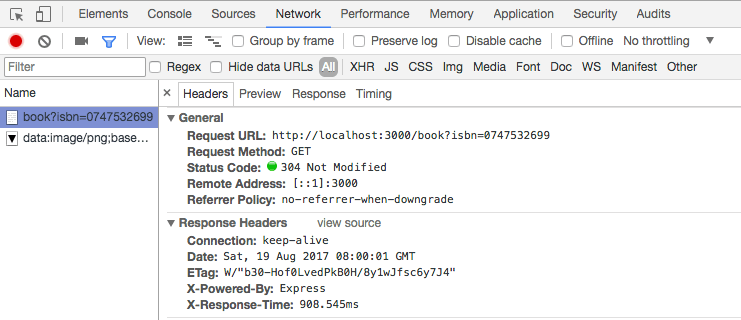
Agora, o mesmo código mas usando Redis, criando uma camada de cache intermediária:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
'use strict'; const express = require('express'); const responseTime = require('response-time') const axios = require('axios'); const redis = require('redis'); const client = redis.createClient(); var app = express(); app.use(responseTime()); const getBook = (req, res) => { let isbn = req.query.isbn; let url = `https://www.googleapis.com/books/v1/volumes?q=isbn:${isbn}`; return axios.get(url) .then(response => { let book = response.data.items; // Define a string isbn como a chave do nosso cache. O conteúdo é o título. // Expiração do cache para 1h (60min x 60s) client.setex(isbn, 3600, JSON.stringify(book)); res.send(book); }) .catch(err => { res.send('Book not found !!!'); }); }; const getCache = (req, res) => { let isbn = req.query.isbn; //Verifica os dados do cache primeiro client.get(isbn, (err, result) => { if (result) { res.send(result); } else { getBook(req, res); } }); } app.get('/book', getCache); app.listen(3000, function() { console.log('Servidor na 3000!') }); |
A diferença entre um e outro é que, no segundo código, eu sempre verifico se eu já não tenho o título no cache, baseado no ISBN. Se eu tiver, retorno o que está no cache, caso contrário, vou no Google pesquisar e, além de retornar, salvo no cache para consultas mais rápidas posteriormente.
O resultado, quando o dado já está em cache, é assustadoramente mais rápido, menos de 1ms. Sim, menos de um milissegundo!!!
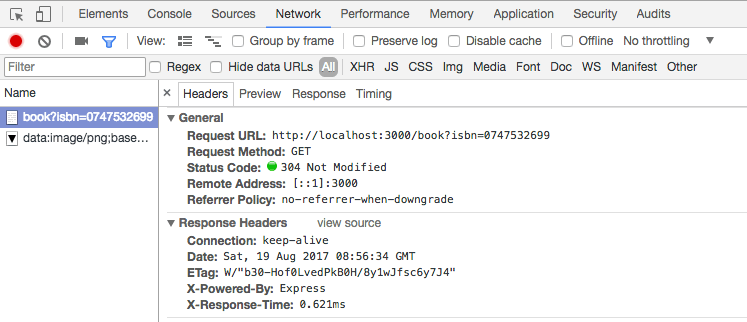
Aprenda a usar Redis com Node.js neste tutorial aqui do blog.

#2 – Tenha índices
Todo mundo que já trabalhou com banco de dados já deve ter ouvido falar de índices alguma vez na sua vida. Nem que seja o mais básico de todos que é o índice primário/chave primária. No entanto, geralmente ele não é o bastante em aplicações do mundo real.
Vamos pegar o MongoDB como exemplo, um banco de dados NoSQL muito utilizado em conjunto do Node.js. Antes de falar de índices pra ele, vamos descobrir como entender se a sua coleção precisa de um novo índice. Para analisar a performance de uma consulta em MongoDB, usamos a função explain, como abaixo:
|
1 2 3 |
A consulta será executada e como retorno teremos os dados de seu planejamento e da sua execução.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
{ "queryPlanner" : ... }, "winningPlan" : { "stage" : "COLLSCAN", "filter" : { "email" : { } }, "direction" : "forward" }, "rejectedPlans" : [ ] }, "executionStats" : { "executionSuccess" : true, "nReturned" : 1, "executionTimeMillis" : 0, "totalKeysExamined" : 0, "totalDocsExamined" : 1039, "executionStages" : { ... }, ... } }, "serverInfo" : { ... }, "ok" : 1 } |
Do trecho acima, tem dois pontos importantes a serem analisados:
- nReturned: número de documentos retornados, neste caso, apenas 1;
- totalDocsExamined: número total de documentos scaneados para encontrar o que queríamos, neste caso 1039;
Entendeu o drama? O MongoDB teve de olhar, um a um, 1039 documentos até encontrar o que queríamos!
Aqui um código rápido de criação de índice no campo email da coleção users:
|
1 2 3 4 5 6 7 8 9 |
db.getCollection("users").createIndex({ "email": 1 }, { "name": "email_1", "unique": true }) { "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1 } |
E o resultado da mesma consulta, 1 documento consultado e 1 retornado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
{ "queryPlanner" : ..., "winningPlan" : { "stage" : "FETCH", "inputStage" : { "stage" : "IXSCAN", "keyPattern" : { "email" : 1 }, "indexName" : "email_1", "isMultiKey" : false, "isUnique" : true, ... } }, "rejectedPlans" : [ ] }, "executionStats" : { "executionSuccess" : true, "nReturned" : 1, "executionTimeMillis" : 0, "totalKeysExamined" : 1, "totalDocsExamined" : 1, ... } } }, "serverInfo" : { ... } |
Em relação ao tempo de execução, ambas foram instantâneas (executionTimeMillis: 0), mas porque tem poucos dados na base. Em volumes gigantes (big data), a diferença de tempo será gritante também.
Eu falo em mais detalhes de MongoDB em meu livro.

#3 – Arquitetura Assíncrona
Programar de forma assíncrona é entender que tudo tem seu tempo, mas que nem por isso devemos fazer com que nosso usuário fique esperando por uma resposta. Node.js traz o modelo de programação assíncrona por padrão para o mundo JavaScript, com Callbacks, Promises e Async/Await. No entanto, apenas usar estes recursos, sem pensar na sua arquitetura para que ela funcione de maneira assíncrona, é deixar muita “performance na mesa”.
Primeiro, vamos falar de processamento assíncrono.
Se o seu backend tem uma demanda muito alta de requisições e cada requisição exige um certo processamento para ser devolvida, você não deveria responder de forma síncrona. Todo mundo que já tentou atender grandes cargas de requests simultâneas de maneira síncrona caiu no mesmo problema: requests dropando, timeouts estourando e o usuário insatisfeito. Você deveria usar uma solução profissional de filas, como Kafka, RabbitMQ ou AWS SQS (clique nos nomes para ver tutoriais). Ou ainda, elevando esta solução a outro nível de sistema distribuído, usando serverless para processar em background o resultado da requisição.
Com estas soluções, você recebe a requisição, enfileira para processamento (que será feito por um worker consumindo a fila) e responde ao usuário que dará um retorno mais tarde. Quando o worker finalizar o seu trabalho, aí sim é hora de dar uma resposta melhor para o usuário.
Mas como devolver uma resposta assíncrona para o usuário?
Aí que entra o segundo ponto que queria trazer: dados assíncronos.
Quando você quiser enviar mensagens/dados/whatever para o usuário sem que ele tenha de ativamente ficar lhe mandando requests de tempos em tempos (o famoso polling), a maneira mais performática de fazer isso é tendo um canal de comunicação aberto com ele, o que normalmente é feito com tecnologias como WebHooks, WebSockets ou Socket.io.
Uma vez estabelecido um canal cliente-servidor com websockets, por exemplo, o server pode associar requests a streams de dados e sempre que tiver novidades, enviar para um ou mais clientes facilmente, no exato instante que for necessário, criando aquela gostosa sensação de atualização em tempo real.
Repare que esta arquitetura não é trivial de ser implementada e implantada. Além disso, para projetos pequenos, ela não faz sentido uma vez que existe toda uma carga a mais e camadas a serem percorridas pelas requests, o que consome mais tempo do que apenas receber uma request e devolver uma response. No entanto, pelos problemas que citei acima, essas perdas iniciais se pagam, e muito, para aplicações grandes, além de manter um alto nível de confiança de que tudo que foi recebido, será processado, mais cedo ou mais tarde.
#4 – Use protocolos modernos
HTTP/2 comumente chamado de SPDY é o protocolo padrão para a web mais recente, desenvolvido pelo grupo de trabalho HTTP da IETF. HTTP/2 torna a navegação web mais rápida, fácil e usando menos banda. Ele foca em performance, especialmente para resolver problemas que ainda ocorrem na versão mais usada do HTTP, a 1.x.
Atualmente, grandes nomes com Google, Facebook e Youtube já implementam este protocolo em suas páginas e estão encorajando a cada vez mais desenvolvedores usarem o mesmo. Ele é um pouco mais complexo que o normal, pois, por exemplo, exige conexão criptografada (SSL).
Abaixo, um exemplo de server HTTP/2 em Node.js, do site oficial:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
const http2 = require('http2'); const fs = require('fs'); const server = http2.createSecureServer({ key: fs.readFileSync('localhost-privkey.pem'), cert: fs.readFileSync('localhost-cert.pem') }); server.on('error', (err) => console.error(err)); server.on('stream', (stream, headers) => { // stream is a Duplex stream.respond({ 'content-type': 'text/html', ':status': 200 }); stream.end('<h1>Hello World</h1>'); }); server.listen(8443); |
Para gerar os certificados (arquivos PEM) que ele precisa no código, você pode usar o OpenSSL via linha de comando:
|
1 2 3 4 |
openssl req -x509 -newkey rsa:2048 -nodes -sha256 -subj '/CN=localhost' -keyout localhost-privkey.pem -out localhost-cert.pem |
Ou gerar no seu servidor usando Lets Encrypt, como comento neste post.
Outra dica é dar uma olhada a respeito de gRPC, uma implementação em cima do HTTP/2 cada vez mais popular para micro serviços.

#5 – Use um cluster
Por padrão, Node.js roda em uma thread única e consequentemente em um único core do processador, o tornando ineficiente se estiver em uma máquina com múltiplos cores.
Mas já tem muito tempo que isso foi resolvido através da implementação de clusterização de thread em Node.js, o que permite criar processos filhos que compartilham a porta do servidor, permitindo que o Node possa aguentar um grande volume de requests em servidores com vários cores. Ensino como fazer no vídeo abaixo.
Outro jeito bem fácil de clusterizar a sua aplicação Node.js é usando o PM2, como mencionei no vídeo acima também. Já falei do PM2 em mais de uma oportunidade aqui no blog e até gravei um vídeo falando sobre ele. Basicamente ele é um gerenciador de processos que pode ser usado com Node.js para garantir que ele vai estar sempre rodando no servidor.
Quando usamos PM2, podemos subir um cluster de processos iguais sem fazer qualquer modificação no seu código, apenas passando um parâmetro na hora de inicializar o seu processo com este utilitário:
|
1 2 3 |
pm2 start app.js -i 0 |
Assim, o PM2 automaticamente já vai escalar a sua aplicação para TODOS os cores da máquina em que ele estiver rodando.

Vale ressaltar que subir sua aplicação em cluster exige alguns cuidados pois, por exemplo, elas não pode compartilhar dados in memory, apenas usando serviços em comum como bancos de dados, Redis, filas, etc. Uma dica para quem quiser desenvolver com cluster em mente é seguir a metodologia 12-factor app.
#6 – Monitore a sua aplicação
Uma das coisas que mais afeta as aplicações em produção são os erros. Não apenas porque eles estragam a experiência dos usuários, mas porque eles degradam a performance da aplicação em si, pois erros derrubam threads, geram efeitos colaterais e muitas vezes são invisíveis.
Com isso em mente, a última dica é uma das mais importantes: monitore a sua aplicação!
E quando falo em monitoria não é apenas ficar olhando uso de memória e CPU no servidor, mas sim usar alguma solução profissional de monitoria como New Relic, Dynatrace, Stackify, Ruxit, LogicMonitor e Monitis.
Somente com uma ferramenta de monitoria em tempo real você poderá garantir que a sua aplicação está tendo uma boa performance e seus usuários estão sendo bem atendidos do ponto de vista sistêmico, ao menos.
Se você não puder contratar ferramentas como essas, precisamos ao menos expor os erros com logs. E não falo de console.log, mas de uso de pacotes de logging mais profissionais como Winston, que eu fiz tutorial aqui no blog (clique no nome).
Abaixo, um exemplo básico de uso do Winston:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
const winston = require('winston'); let logger = new winston.Logger({ transports: [ new winston.transports.File({ level: 'verbose', timestamp: new Date(), filename: 'filelog-verbose.log', json: false, }), new winston.transports.File({ level: 'error', timestamp: new Date(), filename: 'filelog-error.log', json: false, }) ] }); logger.stream = { write: function(message, encoding) { logger.info(message); } }; |
Se possível, eu particularmente acho mais prático armazenar os logs na nuvem ao invés de log files no servidor. Para esta finalidade, recomento o AWS CloudWatch Logs, que também é suportado pelo Winston.
Outra dica legal ainda dentro do âmbito de monitoração é fazer periodicamente testes de stress com a sua aplicação. Para isso eu recomendo usar o Artillery, como mostro no vídeo abaixo.
Até a próxima!
Gostou do artigo? Conheça meu curso online de Node.js e MongoDB clicando no banner abaixo!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.
Conteúdo de altíssima qualidade, obrigado Professor.
Fico feliz que tenha gostado Uhelliton!