
No primeiro artigo desta série eu fiz um resumão do porque escolher uma arquitetura de micro serviços para seus sistemas vale a pena, quais as vantagens do modelo e indiquei Node e Mongo como uma dupla de tecnologias a serem consideradas para este tipo de abordagem. Finalizei o artigo passado explicando a arquitetura de um case de exemplo envolvendo um sistema para uma rede de cinemas.
Neste artigo continuaremos a série, mas desta vez colocando a mão na massa: organizaremos a estrutura padrão que será usada em nossos microservices, construiremos o primeiro deles e modelaremos o seu banco de dados.
Veremos neste artigo:
Então vamos lá!

#1 – Organizando a arquitetura
Relembrando rapidamente o primeiro cenário de uso da nossa arquitetura de microservices:
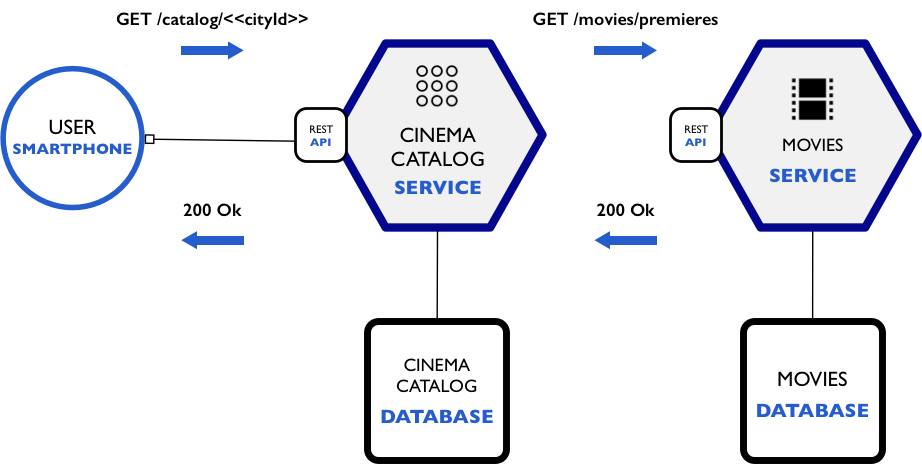
Neste cenário, iniciaremos nosso desenvolvimento com o microservice MOVIES e sua respectiva database. Cabe a esse serviço fornecer informações referentes ao catálogo de filmes cujos direitos de exibição foram comprados pela rede. Além do CRUD básico, espera-se deste serviço que seja possível saber quais filmes são os lançamentos da rede, basicamente os que entraram nos últimos 30 dias, que é mais ou menos a duração do status de lançamento de um filme.
Para estruturar este projeto como um todo, crie uma pasta central chamada cinema-microservice. Dentro dela colocaremos todos os microservices e dados dos mesmos, divididos em subpastas, por uma questão de organização, como mostra a hierarquia de pastas abaixo.
- cinema-microservice
- movies-service
- data
- src
- cinema-catalog-service
- data
- src
- movies-service
Obviamente quando fizermos o deploy dos mesmos, eles serão feitos de maneira independente, mas por uma questão de organização do projeto e do repositório se você vier a versionar este projeto, faz sentido agrupá-los desta forma. Apenas lembre-se de não versionar as pastas de dados e a node_modules de cada microservice, adicionando os respectivos caminhos no seu .gitignore.
Dentro da subpasta movies-service, que é a que vamos focar neste artigo, temos as pastas data e src. Na pasta data armazenaremos os dados do nosso banco MongoDB (basta apontar o dbpath para cá na inicialização do banco) deste microservice. Já na pasta src armazenaremos os códigos-fonte do mesmo.
Dentro da pasta src teremos a seguinte estrutura de pastas e arquivos, em todos os nossos microservices a partir deste aqui:
- movies-service
- src
- api
- config
- repository
- server
- index.js
- packages.json
- src
Os arquivos index.js e package.json são auto-explicativos no cenário de uma webapi em Node.js. Na pasta api teremos os módulos das rotas deste microservice. Na pasta config, os módulos de configuração e de acesso básico a dados (MongoDB cru). Na pasta repository nós teremos módulos seguindo o pattern Repository, uma versão mais “NoSQL” do pattern DAO (Data Access Object, focado em SQL).
E basicamente esta é a estrutura, agora vamos aos dados!

#2 – Organizando os dados
Como estamos focando no microservice MOVIES, nossa base de dados será bem tranquila pois teremos apenas uma coleção de documentos com todos os filmes dentro. Obviamente se você não está acostumado com modelagem de dados em MongoDB (se é que modelagem é o termo correto aqui), sugiro a série de artigos MongoDB para iniciantes em NoSQL e até mesmo o meu livro de MongoDB.
Também recomendo assistir ao curto vídeo abaixo, onde dou dicas sobre este assunto.

Nossos filmes possuem a seguinte informação:
- identificador único
- título
- duração (em minutos)
- imagem (capa promocional)
- sinopse
- data de lançamento
- categorias (ação, romance, etc)
Obviamente você deve imaginar que poderíamos ter muitas outras informações aqui como faixa etária, trailer, formato de tela, idioma, etc. Vou ficar só com essas por uma questão de simplicidade.
Em um banco relacional tradicional, como isso seria modelado? Algumas colunas da suposta tabela Filmes são bem óbvias como ID, Titulo, Duracao, Sinopse e DataLancamento. Mas e o campo imagem? Apesar dos bancos SQL suportarem BLOBs, nunca foi uma boa opção por pesar demais nos SELECTs e no crescimento do banco como um todo. No entanto, o mesmo não pode ser dito do MongoDB, onde podemos ter campos binários facilmente sem abrir mão da performance. Ainda assim entenderei se você decidir por armazenar apenas a URL da imagem em uma URL pública (AWS S3?).
Mas o que eu queria falar mesmo era das categorias. Esta é uma relação que pelas formas normais e levando muito a sério a não-repetição dos dados deveria ser N-N com 3 tabelas: uma Filmes, outra Categorias e a terceira CategoriaFilmes apenas com chaves-estrangeiras para as duas primeiras. No entanto, esta não é a abordagem sugerida para o MongoDB. Aqui até podemos ter uma coleção de documentos Categorias, se necessária, mas a abordagem mais comum é usar um campo multivalorado no documento de filme contendo as categorias do mesmo. Simples assim.
Obviamente você deve se preocupar em garantir que as categorias sejam escritas sempre da mesma forma, a nível de aplicação, caso contrário será terrível filtrar por elas mais tarde. Enfim, nossa coleção de Filmes possuirá documentos com a seguinte estrutura:
|
1 2 3 4 5 6 7 8 9 10 11 |
{ _id: ObjectId("sacbaskbcksabckscstds67ds"), titulo: "Vingadores: Guerra Infinita", sinopse: "Os heróis mais poderosos da Marvel enfrentando o Thanos", duracao: 120, dataLancamento: ISODate("2018-05-01T00:00:00Z"), imagem: "https://www.luiztools.com.br/vingadores-gi.jpg", categorias: ["Aventura", "Ação"] } |
Para subir o banco de dados do nosso microservice, apenas use uma instância do mongod apontando o dbpath para a pasta data dentro de cinema-microservice/movies-service/data. Obviamente em produção você terá uma abordagem diferente, mas ainda de um banco para cada microservice.

#3 – Conectando o banco
Agora que temos o modelo do nosso banco pronto e a estrutura de pastas organizada, vamos começar a programar nosso primeiro microservice.
Vamos começar acessando a pasta do nosso movie-service/src via terminal, criando um arquivo index.js na raiz desta pasta e usando o comando ‘npm init’ nela que é para criar o package.json do microservice. Depois, rode o comando abaixo pra garantir que teremos as nossas dependências mínimas garantidas e o Jest configurado.
|
1 2 3 4 5 |
npm i express mongodb dotenv-safe morgan npm i -D jest supertest npx create-jest |
Tem várias coisas que devemos fazer e não há necessariamente uma ordem certa para que elas funcionem. O primeiro microservice será um pouco chato e demorado de fazer, mas a partir do segundo será mais fácil. Sendo assim, vou começar por algo que acho que é mais fácil de todo mundo entender, o acesso a dados.
Dentro da pasta movie-service/src/config vamos criar um arquivo database.js, com o seguinte conteúdo dentro:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
const MongoClient = require('mongodb').MongoClient; let client = null; async function connect() { if (!client) client = new MongoClient(process.env.MONGO_CONNECTION); await client.connect(); return client.db(process.env.DATABASE_NAME); } async function disconnect() { if (!client) return true; await client.close(); client = null; return true; } module.exports = { connect, disconnect } |
Note que este módulo db.js cuida para que exista somente uma conexão ativa com o banco de dados através de uma série de testes sobre um objeto client e uma função isConnected dele.
Note também que esse módulo database.js espera que existam duas variáveis de ambiente para sabermos a string de conexão com o banco e o nome da base de dados. Essas variáveis de ambiente devem ser definidas em um arquivo sem nome com a extensão ‘.env’ na raiz do movie-service, sendo que o pacote dotenv-safe que instalamos anteriormente exige a existência de um ‘.env.example’ com a definição das variáveis de ambiente existentes.
|
1 2 3 4 5 6 |
#.env, don't commit to repo MONGO_CONNECTION=mongodb://127.0.0.1:27017 DATABASE_NAME=movie-service PORT=3000 |
|
1 2 3 4 5 6 |
#.env.example, commit to repo MONGO_CONNECTION= DATABASE_NAME= PORT= |
Para nos certificarmos que este módulo está funcionando, vamos escrever um teste unitário para ele? Se você nunca ouviu falar em testes unitários antes, recomendo ler este post sobre TDD.
Na mesma pasta movie-service/src/config crie um arquivo database.test.js e dentro escreva o seguinte código, que nada mais faz do que usar a biblioteca tape (que foi instalada anteriormente no nosso npm install) pra testar a conexão:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//database.test.js require('dotenv-safe').config(); const database = require('./database'); test('MongoDB Connection', async () => { const connection = await database.connect(); expect(connection).toBeTruthy(); }) test('MongoDB Disconnection', async () => { const isDisconnected = await database.disconnect(); expect(isDisconnected).toBeTruthy(); }) |
Note que também carreguei o módulo do dotenv-safe pois precisamos que as variáveis de ambiente estejam carregadas para que nossos testes funcionem.
Falando em funcionar, antes de rodar este teste abra o seu packages.json que fica na raiz de movie-service/src e edite-o para que os scripts de start e de test fiquem igual abaixo:
|
1 2 3 4 5 6 |
"scripts": { "start": "node ./src/index", "test": "jest" }, |
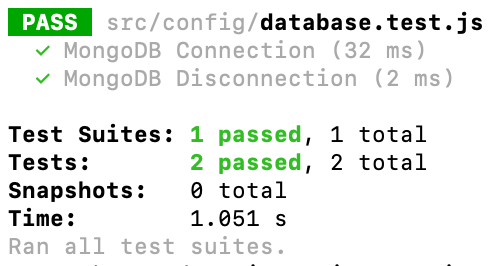
Se você rodar agora sua aplicação com ‘npm test’, todos os seus unit tests de movies-service devem ser executados, desde que atendam ao padrão de nome xxx.test.js.
|
1 2 3 |
npm test |
#4 – Consultando o banco
Agora que sabemos que nossa conexão com o banco funciona, vamos criar nosso módulo de repositório para que possamos fornecer os dados do MongoDB da maneira que as chamadas ao nosso serviço esperam.
Não vou fazer um CRUD completo aqui pois já abordei CRUDs de Node com Mongo em outras oportunidades aqui no livro, é só procurar. Dentro do nosso case de exemplo levarei em conta que precisamos implementar apenas o R (Read) para fornecer dados de filmes específicos (por id) e dos filmes que são lançamentos nos cinemas (lançados nos últimos 30 dias).
Para criar nosso módulo de repositório (que por sua vez usará o módulo database.js) entre na pasta movie-service/src/repository e crie dois arquivos, o repository.js e o repository.test.js, sendo que o primeiro deve ter o conteúdo abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
//repository.js const database = require("../config/database"); const { ObjectId } = require("mongodb"); async function getAllMovies() { const db = await database.connect(); return db.collection("movies").find().toArray(); } async function getMovieById(id) { const db = await database.connect(); return db.collection("movies").findOne({ _id: ObjectId.createFromHexString(id) }); } async function getMoviePremieres() { const monthAgo = new Date(); monthAgo.setMonth(monthAgo.getMonth() - 1); const db = await database.connect(); return db.collection("movies").find({ dataLancamento: { $gte: monthAgo } }).toArray(); } async function disconnect() { return database.disconnect(); } module.exports = { getAllMovies, getMovieById, getMoviePremieres, disconnect } |
Aqui temos uma função para cada um dos três métodos elementares que precisamos ter na API e uma última para desconectar o repositório do banco de dados, função esta que será usada em certas ocasiões como em testes unitários. Apenas atenção à função que retorna os lançamentos (premieres), que tem uma lógica para pegar filmes lançados nos últimos 30 dias apenas.
E no segundo arquivo, repository.test.js, colocamos os testes do primeiro, de maneira análoga ao que fizemos com o módulo database.test.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
//repository.test.js require('dotenv-safe').config(); const repository = require('./repository'); let testId = null; beforeAll(async () => { const movies = await repository.getAllMovies(); testId = movies[0]._id; }) test('Repository GetAllMovies', async () => { const movies = await repository.getAllMovies(); expect(Array.isArray(movies)).toBeTruthy(); expect(movies.length).toBeGreaterThan(0); }) test('Repository GetMovieById', async () => { const movie = await repository.getMovieById(testId); expect(movie).toBeTruthy(); expect(movie._id).toEqual(testId); }) test('Repository GetMoviePremieres', async () => { const movies = await repository.getMoviePremieres(); expect(Array.isArray(movies)).toBeTruthy(); expect(movies.length).toBeGreaterThan(0); }) test('Repository Disconnect', async () => { const isDisconnected = await repository.disconnect(); expect(isDisconnected).toBeTruthy(); }) |
Repare que usamos uma função beforeAll logo no início dos testes. Essa função irá executar antes de qualquer teste e serve para configurar ambiente, carregar variáveis de teste, etc. Usaremos ela para carregar um id de teste que será necessário em um dos testes mais abaixo.
Obviamente que estes testes não passarão se você rodar um ‘npm test’ no terminal, mas isso porque nosso banco de dados não possui qualquer informação de filme, o que você pode resolver abrindo uma instância do utilitário ‘mongo’ no terminal (executando um ‘use’ no banco ‘movie-service’) e inserindo o comando abaixo para adicionar uma carga de filmes (pelo menos um deles, ajuste a data para que seja um lançamento):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
db.movies.insert([{ titulo: "Os Vingadores: Ultimato", sinopse: "Os heróis mais poderosos da Terra enfrentando o Thanos. De novo.", duracao: 181, dataLancamento: ISODate("2019-04-25T00:00:00Z"), imagem: "https://m.media-amazon.com/images/M/MV5BMTc5MDE2ODcwNV5BMl5BanBnXkFtZTgwMzI2NzQ2NzM@._V1_UX182_CR0,0,182,268_AL_.jpg", categorias: ["Aventura", "Ação"] },{ titulo: "Os Vingadores: Guerra Infinita", sinopse: "Os heróis mais poderosos da Terra enfrentando o Thanos", duracao: 149, dataLancamento: ISODate("2018-04-26T00:00:00Z"), imagem: "https://m.media-amazon.com/images/M/MV5BMjMxNjY2MDU1OV5BMl5BanBnXkFtZTgwNzY1MTUwNTM@._V1_UX182_CR0,0,182,268_AL_.jpg", categorias: ["Aventura", "Ação"] },{ titulo: "Os Vingadores: Era de Ultron", sinopse: "Os heróis mais poderosos da Terra enfrentando o Ultron", duracao: 141, dataLancamento: ISODate("2015-04-23T00:00:00Z"), imagem: "https://m.media-amazon.com/images/M/MV5BMTM4OGJmNWMtOTM4Ni00NTE3LTg3MDItZmQxYjc4N2JhNmUxXkEyXkFqcGdeQXVyNTgzMDMzMTg@._V1_UX182_CR0,0,182,268_AL_.jpg", categorias: ["Aventura", "Ação"] },{ titulo: "Os Vingadores", sinopse: "Os heróis mais poderosos da Terra enfrentando o Loki", duracao: 143, dataLancamento: ISODate("2012-04-27T00:00:00Z"), imagem: "https://m.media-amazon.com/images/M/MV5BNDYxNjQyMjAtNTdiOS00NGYwLWFmNTAtNThmYjU5ZGI2YTI1XkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_UX182_CR0,0,182,268_AL_.jpg", categorias: ["Aventura", "Ação"] }]) |
Agora sim, ao rodar o ‘npm test’, todos seus testes unitários devem passar com sucesso (dos dois arquivos):
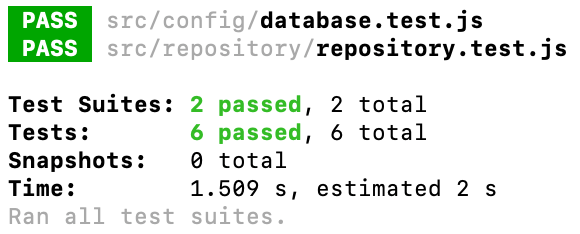
Com estes testes todos passando, temos a certeza de que a parte do banco de dados da nossa futura API estará 100% operacional, cabendo agora programarmos a API em si, que irá trabalhar com estes dados que viemos “brincando” até então.
No entanto, a programação da API movie-service ficou para a terceira parte desta série de artigos!






Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.