
Quando estamos desenvolvendo nossa aplicação podemos adicionar console.log, depurar e até mesmo olhar o código fonte o tempo todo, a fim de entender o que está acontecendo com ela. Assim, erros encontrados são facilmente identificados e corrigidos, estamos no controle da situação.
Mas e quando subimos ela para produção e dá um problema, como lidamos com esta situação?
O primeiro caminho a seguir é o tratamento de erros adequado, que já foi assunto de outro tutorial aqui do blog.
Isso vai evitar que a aplicação caia em caso de erro, que o usuário sempre tenha um retorno adequado às suas requisições e também mantém a gestão centralizada dos erros, o que facilita também o logging, que é o assunto do tutorial de hoje.
Sendo assim, este é um tutorial básico de logging de aplicações Node.js usando o pacote Winston, um dos mais populares para esta finalidade.
Se preferir, você pode acompanhar o conteúdo deste tutorial no vídeo abaixo, a partir da metade dele.
Vamos lá!

O que é Logging?
Logging é o ato de criar logs, que são registros de mensagens e eventos da sua aplicação. Esses registros podem ou não ser persistentes, ou seja, você pode registrar na saída do console e quem viu, viu, como no caso do console.log. Você pode registrar logs de informação e de erro, via console.log.
|
1 2 3 4 5 6 7 |
//imprime em stdout console.log('info, o mesmo que console.debug e console.info'); //imprime em stderr console.error('erro, o mesmo que console.warn'); |
Isso é o que a maioria dos devs iniciantes fazem, mas não costuma ser o bastante para ambientes em produção. E saber como lidar com aplicações em produção é o que separa os devs amadores dos profissionais.
A alternativa ao console.log efêmero é registrar as mensagens em um arquivo ou banco de logs para visualização posterior, quando houver necessidade. Ou ainda usar algum mecanismo que se conecte às streams stdout e stderr da sua aplicação para capturar os seus console.log. Independente da abordagem, como logging é algo que vai rodar 24×7, é interessante que você saiba dosar o quê, como, quando e onde logar o que acontece na sua aplicação, caso contrário terá problemas.
Como assim?
Se você logar pouco, ou muito mas com poucas informações relevantes, o log em si será irrelevante. Se você logar muito, o log se torna difícil de usar (muito verboso) e principalmente, se tornará um problema para armazenar (cresce muito rápido).
Como resolver?
Não existem respostas universais para todos estes questionamentos, cabendo ao desenvolvedor analisar o contexto para entender o quê deve logar e quando deve logar.
Via de regra, você vai querer logar no mínimo os erros da sua aplicação, incluindo além do erro e do stacktrace, informações do acontecimento que originou o problema (momento, usuário, dados da transação, etc)
Em algumas áreas como o setor bancário, você deve logar absolutamente todas as transações, não apenas as que deram erro e esse log deve ser feito em banco de dados.
Agora, o como e o onde, esses questionamentos tenho algumas boas práticas para compartilhar.

Log Local x Log na Nuvem
Sobre COMO logar, isso vai depender de ONDE você vai logar. Sendo assim, vamos falar do ONDE primeiro.
Basicamente existem dois “ONDES” possíveis: localmente, junto da aplicação, ou na nuvem. Já trabalhei com ambas as formas e diversas variações híbridas e não há uma solução perfeita ou definitiva, então vale dissertar um pouco sobre o assunto.
Quando falo Log Local me refiro a logs armazenados de maneira que somente estando conectado ao servidor onde os mesmos foram salvos é que podemos coletá-los. Geralmente é feito usando Log Files ou ainda em banco de dados, mas sem qualquer acesso externo.
As vantagens desta abordagem são a simplicidade de implementação e baixíssimo custo, pois geralmente acaba-se muitas vezes utilizando serviços já existentes da aplicação como disco, banco de dados, etc.
As desvantagens desta abordagem é que não é nada prático de lidar com logs locais e geralmente por uma questão de segurança, pouquíssimas pessoas na empresa têm acesso aos servidores e banco de dados das aplicações, logo, o acesso aos logs se torna restrito também.
Quando falo Log na Nuvem me refiro a logs armazenados em serviços especializados para logging ou pelo menos serviços de armazenamento de arquivos que sejam acessíveis pela nuvem sem a necessidade de entrar no servidor ou banco de dados da aplicação.
As vantagens desta abordagem são a praticidade e velocidade com a qual você irá utilizar os logs, geralmente impactando diretamente na velocidade com que seu time irá conseguir encontrar e resolver os problemas, aumentando a satisfação dos usuários da aplicação.
As desvantagens desta abordagem é que geralmente são soluções com um setup mais complexo do que apenas escrever um log file local e é comum que possuam custos também, caso sejam serviços gerenciados de logging.
Enfim, note que a decisão não é tão simples, então é importante que você conheça bem o seu contexto e a demanda que terá por esses logs, para só então tomar a decisão mais apropriada.

Log Local com Winston
Neste primeiro tutorial de logging eu irei tomar a decisão de escrever logs localmente. Poderíamos fazer isso de maneira aparentemente fácil usando o pacote fs do Node.js, mas isso nos traria uma série de problemas como tamanho dos logs, criação de arquivos, log level, etc.
Ao invés disso, vou poupar o seu tempo e vamos já sair usando log files gerenciados pelo pacote Winston, um dos mais populares para Node.js. Futuramente podemos explorar outras alternativas em nuvem ou até um modelo híbrido, o que pode fazer sentido em algumas arquiteturas mais complexas.
Assim, crie um projeto Node.js e instale o Winston nele.
|
1 2 3 4 |
npm init -y npm i winston |
Agora crie um arquivo logger.js na raiz da aplicação para configurarmos nossas regras de logging.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
//logger.js const winston = require('winston'); const logger = winston.createLogger({ format: winston.format.combine( winston.format.errors({ stack: true }), winston.format.json() ), transports: [ new winston.transports.File({ filename: 'error.log', level: 'error' }), new winston.transports.File({ filename: 'info.log', level: 'info' }), ], }); if (process.env.NODE_ENV !== 'production') { logger.add(new winston.transports.Console({ format: winston.format.simple() })); } module.exports = logger; |
Acima eu coloquei algumas regras de exemplo, dentre as inúmeras possibilidades do Winston, começando pela criação do logger. Neste momento, podemos definir o formato que vamos usar para registro dos mesmos, onde deixei configurado para que os erros incluam o stacktrace e que os logs sejam registrados em formato JSON.
A configuração logo abaixo, transports, diz respeito aos possíveis destinos dos logs, sendo que no exemplo coloquei dois arquivos diferentes baseados no log level. Importante ressaltar que os log levels são incrementais, ou seja, ‘info’ vai exibir info e error (por ser menos restritivo), enquanto error vai exibir somente error.
E por fim, o último bloco é apenas perfumaria, informando que em ambientes que não sejam o de produção vamos logar no console também.
Agora, crie um arquivo index.js na raiz da sua aplicação para eu poder lhe mostrar como usar esse logger.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//index.js const logger = require('./logger'); const obj = { name: 'luiztools' } //const obj = undefined; //descomente essa linha para provocar o erro try { console.log(obj.name); logger.info('tudo funcionando!'); } catch (error) { logger.error(error); } |
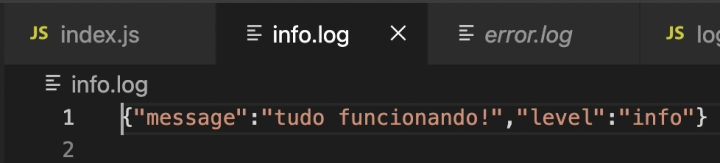
Execute este arquivo e o resultado será a criação de um arquivo info.log na raiz da sua aplicação com o conteúdo da mensagem registrada.
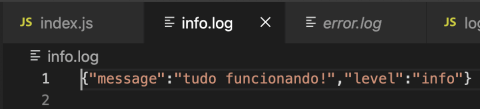
Agora ajuste a index.js para que ela cause um erro que será capturado pelo try/catch.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//index.js const logger = require('./logger'); //const obj = { name: 'luiztools' } const obj = undefined; try { console.log(obj.name); logger.info('tudo funcionando!'); } catch (error) { logger.error(error); } |
Executando agora o index.js modificado, você notará que tanto o info.log quanto o error.log criados na raiz da sua aplicação irão incluir o JSON de erro. Além disso, se olhar o seu console, verá que foi impressa lá a informação do erro também, por estarmos em ambiente de desenvolvimento.
Tenho certeza que juntando esses conhecimentos com outros tantos que você já deve ter ou que pode buscar em meu blog, meus livros e meus cursos, você conseguirá implementar esta solução na sua aplicação.
Quer aprender como fazer logging na nuvem com AWS CloudWatch? Leia este tutorial.
Um abraço e até a próxima!
Curtiu o tutorial? Quer aprender como construir aplicações web profissionais utilizando a stack completa do JavaScript? Conheça meu curso clicando no banner abaixo.








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.