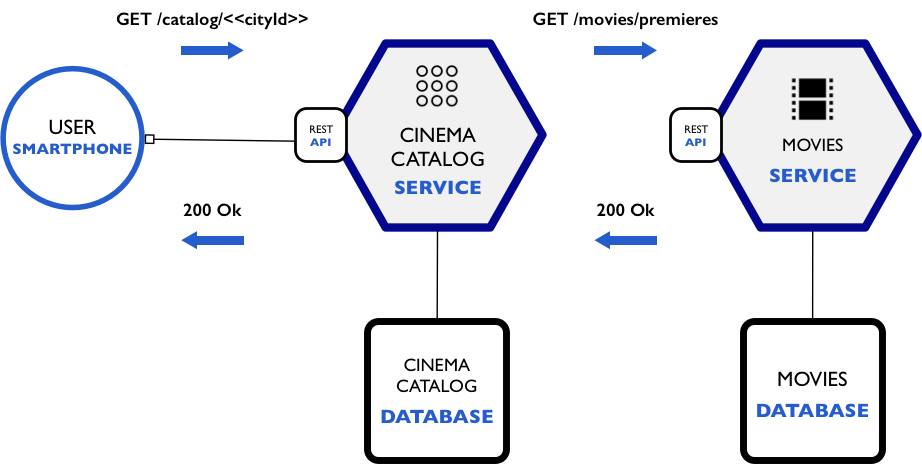

E chegamos à quinta parte da nossa série de artigos sobre como implementar na prática um projeto de sistema usando arquitetura de microservices usando Node.js e MongoDB. Essa que já é uma das séries de artigos mais longevas aqui do blog!
Segue o índice da série até o momento, caso tenha caído de pára-quedas no blog só agora:
- Parte 1: introdução teórica e case que estudaremos;
- Parte 2: estrutura do projeto, camadas de dados e testes unitários;
- Parte 3: primeiro microservice finalizado (movies-service);
- Parte 4: iniciando desenvolvimento do segundo microservice (cinema-catalog-service);
Nesta quinta parte, vamos fazer o desenvolvimento das demais funções do repository.js do micro serviço cinema-catalog-service, lembrando que queremos fornecer através deste micro serviço acesso ao front-end mobile a funções como consulta de cinemas por cidade, de filmes em exibição por cinema, sessões dos filmes e por aí vai.
Veremos nesta etapa da série:

#1 – Finalizando o Repositório
Onde paramos no artigo anterior? Ah sim, tínhamos a seguinte lista de funções a serem criadas no repository.js:
- pesquisar cidades em que a rede possui cinema;
- pesquisar cinemas por id da cidade;
- pesquisar filmes disponíveis em um cinema;
- pesquisar filmes disponíveis em uma cidade;
- pesquisar sessões disponíveis para um filme em uma cidade;
- pesquisar sessões disponíveis para um filme em um cinema;
Enquanto que as duas primeiras foram feitas ainda no tópico anterior, as demais não. Elas guardam uma complexidade que ainda não tivemos de lidar no nosso projeto: agregações. Como nosso documento é relativamente complexo, com mais de um nível de profundidade, se faz necessário navegar e agrupar dados entre os níveis para oferecer informação relevante e fácil de ser manipulada pela camada de API que ainda nem construímos.
Assim, abra o seu cinema-microservice/cinema-catalog-service/src/repository/repository.js e adicione a seguinte função:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
async function getMoviesByCinemaId(cinemaId) { const objCinemaId = ObjectId.createFromHexString(cinemaId); const db = await database.connect(); return db.collection("cinemaCatalog").aggregate([ { $match: { "cinemas._id": objCinemaId } }, { $unwind: "$cinemas" }, { $unwind: "$cinemas.salas" }, { $unwind: "$cinemas.salas.sessoes" }, { $group: { _id: { filme: "$cinemas.salas.sessoes.filme", idFilme: "$cinemas.salas.sessoes.idFilme" } } } ]).toArray(); } module.exports = { getAllCities, getCinemasByCityId, disconnect, getMoviesByCinemaId } |
Respire por um momento que aqui temos uma série de novos operadores e a novíssima função aggregate.
A função aggregate substitui a função find quando nossa consulta irá manipular os dados resultantes para realizar agregações de diversos tipos. A função aggregate executa um pipeline de comandos contidos no array que ela recebe por parâmetro, seguindo exatamente a ordem do array. Assim, do primeiro operador do nosso pipeline de agregação temos:
- $match: este operador é um filtro, tal qual os possíveis de serem utilizados no find. Aqui, estou dizendo para filtrar apenas pelos documentos cujo id do cinema seja igual ao recebido;
- $unwind: este operador desconstrói campos multivalorados em novos documentos, repetindo os demais dados do documento pai do array. Ou seja, se eu tinha uma cidade com dois cinemas dentro, o primeiro $unwind vai fazer com que eu tenha duas cidades repetidas, mas cada uma com um cinema apenas (o campo multivalorado vira univalorado);
- os $unwinds seguintes vão desconstruindo os demais arrays do documento;
- $group: uma vez que eu tenho todos os documentos com apenas documentos e subdocumentos (sem arrays), é hora de agrupar eles para evitar as repetições e também para pegar apenas os dados que me interessam, que são os ids e nomes dos filmes que estão em exibição no cinema em questão;
Essa agregação toda, no final das contas, gera um array de filmes no formato id/nome bem simples de ser recebido e utilizado pela API.
Na mesma ideia da função anterior, vamos criar mais três delas, finalizando nosso repository.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
async function getMoviesByCityId(cityId) { const objCityId = ObjectId.createFromHexString(cityId); const db = await database.connect(); const sessions = await db.collection("cinemaCatalog").aggregate([ { $match: { "_id": objCityId } }, { $unwind: "$cinemas" }, { $unwind: "$cinemas.salas" }, { $unwind: "$cinemas.salas.sessoes" }, { $group: { _id: { filme: "$cinemas.salas.sessoes.filme", idFilme: "$cinemas.salas.sessoes.idFilme" } } } ]).toArray(); return sessions.map(item => { return { idFilme: item._id.idFilme, filme: item._id.filme } }); } async function getMovieSessionsByCityId(movieId, cityId) { const objMovieId = ObjectId.createFromHexString(movieId); const objCityId = ObjectId.createFromHexString(cityId); const db = await database.connect(); const sessions = await db.collection("cinemaCatalog").aggregate([ { $match: { "_id": objCityId } }, { $unwind: "$cinemas" }, { $unwind: "$cinemas.salas" }, { $unwind: "$cinemas.salas.sessoes" }, { $match: { "cinemas.salas.sessoes.idFilme": objMovieId } }, { $group: { _id: { filme: "$cinemas.salas.sessoes.filme", idFilme: "$cinemas.salas.sessoes.idFilme", idCinema: "$cinemas._id", sala: "$cinemas.salas.nome", sessao: "$cinemas.salas.sessoes" } } } ]).toArray(); return sessions.map(item => { return { idFilme: item._id.idFilme, filme: item._id.filme, idCinema: item._id.idCinema, sala: item._id.sala, sessao: item._id.sessao } }); } async function getMovieSessionsByCinemaId(movieId, cinemaId) { const objCinemaId = ObjectId.createFromHexString(cinemaId); const objMovieId = ObjectId.createFromHexString(movieId); const db = await database.connect(); const sessions = await db.collection("cinemaCatalog").aggregate([ { $match: { "cinemas._id": objCinemaId } }, { $unwind: "$cinemas" }, { $unwind: "$cinemas.salas" }, { $unwind: "$cinemas.salas.sessoes" }, { $match: { "cinemas.salas.sessoes.idFilme": objMovieId } }, { $group: { _id: { filme: "$cinemas.salas.sessoes.filme", idFilme: "$cinemas.salas.sessoes.idFilme", sala: "$cinemas.salas.nome", sessao: "$cinemas.salas.sessoes" } } } ]).toArray(); return sessions.map(item => { return { idFilme: item._id.idFilme, filme: item._id.filme, sala: item._id.sala, sessao: item._id.sessao } }); } module.exports = { getAllCities, getCinemasByCityId, disconnect, getMoviesByCinemaId, getMoviesByCityId, getMovieSessionsByCityId, getMovieSessionsByCinemaId } |
Note que nestas funções ainda temos mais alguns complicadores.
Primeiro, todas elas estão tratando o retorno da consulta para passar à camada superior objetos mais “mastigados” uma vez que o operador $group do MongoDB costuma deixar um nível desnecessário dentro dos documentos que ele retorna, fora nomenclaturas e etc que podemos tratar melhor usando a boa e velha função ‘map’ do JavaScript.
Além disso, as duas últimas funções usaram um operador $match adicional para fazer um novo filtro após os $unwinds, diminuindo ainda mais a carga do operador $group. Usar o operador $match o quanto antes do final do pipeline de agregação é sempre uma boa prática para diminuir a carga da função aggregate que é bem pesada.
E ‘bora criar novos testes unitários para cobrir estas novas funções no repository.test.js, como abaixo. Coloque estes testes após o teste da função ‘Repository getCinemasByCityId’ e antes do teste da função ‘disconnect’.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
test('Repository getMoviesByCinemaId', async () => { const result = await repository.getMoviesByCinemaId(testCinemaId); expect(Array.isArray(result)).toBeTruthy(); expect(result.length).toBeGreaterThan(0); }) test('Repository getMoviesByCityId', async () => { const result = await repository.getMoviesByCityId(testCityId); expect(Array.isArray(result)).toBeTruthy(); expect(result.length).toBeGreaterThan(0); }) test('Repository getMovieSessionsByCityId', async () => { const result = await repository.getMovieSessionsByCityId(testMovieId, testCityId); expect(Array.isArray(result)).toBeTruthy(); expect(result.length).toBeGreaterThan(0); }) test('Repository getMovieSessionsByCinemaId', async () => { const result = await repository.getMovieSessionsByCinemaId(testMovieId, testCinemaId); expect(Array.isArray(result)).toBeTruthy(); expect(result.length).toBeGreaterThan(0); }) |
Note que os testes acima usam algumas variáveis como testMovieId e testCinemaId que ainda não estamos carregando. Sendo assim, ajuste o seu beforeAll para carregá-las apropriadamente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//repository.test.js require('dotenv-safe').config(); const repository = require('./repository'); let testCityId = null; let testCinemaId = null; let testMovieId = null; beforeAll(async () => { const cities = await repository.getAllCities(); testCityId = cities[1]._id;//Porto Alegre testCinemaId = cities[1].cinemas[0]._id; testMovieId = cities[1].cinemas[0].salas[0].sessoes[0].idFilme; }) |
Isso nos dará uma cobertura de 100% das nossas funções até o momento, nos dando a garantia que podemos avançar para a camada de API do nosso microservice sem medo de ter deixado alguma ponta solta para trás!

#2 – Programando a API Cinema-Catalog-Service
Nosso próximo passo é criar a API propriamente dita. Seguiremos a mesma arquitetura da API anterior, a movies-service, apenas definindo um novo conjunto de rotas coerente com a responsabilidade desse microservice novo que é a localização de salas e sessões de cinema a partir de informações como cidade, filme, etc.
Baseado no que temos de funções em nosso repository.js, podemos definir que devemos fornecer o tratamento das seguintes rotas na nossa API:
- GET /cities
- lista todas cidades em que a rede possui cinema;
- GET /cities/:city/movies
- lista todos os filmes em exibição na cidade especificada;
- GET /cities/:city/movies/:movie
- lista todos as sessões do filme escolhido na cidade especificada;
- GET /cities/:city/cinemas
- lista todos os cinemas em determinada cidade;
- GET /cinemas/:cinema/movies
- lista todos os filmes em exibição no cinema especificado;
- GET /cinemas:cinema/movies/:movie
- lista todas as sessões do filme escolhido no cinema especificado;
Novamente vamos adotar a abordagem de não fazer o CRUD completo mas apenas as chamadas que possibilitem ao front-end poder construir suas telas e seu funcionamento de navegação.
Obviamente você pode pensar em rotas adicionais à estas ou até em uma ‘pureza’ maior do conceito de RESTful.
Com esse mapeamento das rotas em mente, vamos criar nosso arquivo cinema-microservice/cinema-catalog-service/src/api/cinema-catalog.js com o seguinte conteúdo que não tem nada demais em relação à API anterior que já criamos (movies-service):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
//cinema-catalog.js module.exports = (app, repository) => { app.get('/cities', (req, res, next) => { repository.getAllCities((err, cities) => { if(err) return next(err); res.json(cities); }); }) app.get('/cities/:city/movies', (req, res, next) => { repository.getMoviesByCityId(req.params.city, (err, movies) => { if(err) return next(err); res.json(movies) }); }) app.get('/cities/:city/movies/:movie', (req, res, next) => { repository.getMovieSessionsByCityId(req.params.movie, req.params.city, (err, sessions) => { if(err) return next(err); res.json(sessions) }); }) app.get('/cities/:city/cinemas', (req, res, next) => { repository.getCinemasByCityId(req.params.city, (err, cinemas) => { if(err) return next(err); res.json(cinemas) }); }) app.get('/cinemas/:cinema/movies', (req, res, next) => { repository.getMoviesByCinemaId(req.params.cinema, (err, movies) => { if(err) return next(err); res.json(movies) }); }) app.get('/cinemas/:cinema/movies/:movie', (req, res, next) => { repository.getMovieSessionsByCinemaId(req.params.movie, req.params.cinema, (err, sessions) => { if(err) return next(err); res.json(sessions) }); }) } |
Note que como o trabalho pesado ficou todo no repository.js e suas inúmeras agregações, aqui basta receber a requisição, pegar os parâmetros adequados e chamar a função correspondente no repositório. Simples assim.
Da mesma forma que mencionei em outro artigo desta série, também é necessário aplicar validação dos inputs recebidos, por segurança. Falo sobre isto nesse outro artigo aqui.
Para escrever nossos testes, usaremos como base as mesmas ferramentas e princípios dos testes de API que fizemos na Parte 3 usando a biblioteca supertest como apoio (lembrando que instalamos todas as dependências deste projeto no artigo anterior). Assim, crie o arquivo cinemaCatalog.test.js e adicione os seguintes testes dentro dele:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
//cinemaCatalog.test.js require('dotenv-safe').config(); const supertest = require('supertest'); const movies = require('./cinemaCatalog'); const server = require("../server/server"); const repository = require("../repository/repository"); let testCityId = null; let testMovieId = null; let testCinemaId = null; let app = null; beforeAll(async () => { app = await server.start(movies, repository); const cities = await repository.getAllCities(); testCityId = cities[1]._id;//Porto Alegre testCinemaId = cities[1].cinemas[0]._id; testMovieId = cities[1].cinemas[0].salas[0].sessoes[0].idFilme; }) afterAll(async () => { await server.stop(); await repository.disconnect(); }) test('GET /cities', async () => { const response = await supertest(app) .get('/cities'); expect(response.status).toEqual(200); expect(Array.isArray(response.body)).toBeTruthy(); expect(response.body.length).toBeGreaterThan(0); }) test('GET /cities/:city/movies', async () => { const response = await supertest(app) .get(`/cities/${testCityId}/movies`); expect(response.status).toEqual(200); expect(Array.isArray(response.body)).toBeTruthy(); expect(response.body.length).toBeGreaterThan(0); }) test('GET /cities/:city/movies/:movie', async () => { const response = await supertest(app) .get(`/cities/${testCityId}/movies/${testMovieId}`); expect(response.status).toEqual(200); expect(Array.isArray(response.body)).toBeTruthy(); expect(response.body.length).toBeGreaterThan(0); }) test('GET /cities/:city/cinemas', async () => { const response = await supertest(app) .get(`/cities/${testCityId}/cinemas`); expect(response.status).toEqual(200); expect(Array.isArray(response.body)).toBeTruthy(); expect(response.body.length).toBeGreaterThan(0); }) test('GET /cinemas/:cinema/movies', async () => { const response = await supertest(app) .get(`/cinemas/${testCinemaId}/movies`); expect(response.status).toEqual(200); expect(Array.isArray(response.body)).toBeTruthy(); expect(response.body.length).toBeGreaterThan(0); }) test('GET /cinemas/:cinema/movies/:movie', async () => { const response = await supertest(app) .get(`/cinemas/${testCinemaId}/movies/${testMovieId}`); expect(response.status).toEqual(200); expect(Array.isArray(response.body)).toBeTruthy(); expect(response.body.length).toBeGreaterThan(0); }) |
O que tem de novo aqui que valha a pena ser explicado? Absolutamente nada, e espero que a esta altura do campeonato você consiga criar este arquivo e seus testes sem ter de necessariamente copiar e colar este bloco inteiro de código. Caso ainda não consiga, tente ao menos copiar apenas um teste e escrever de próprio punho os demais, para ir pegando prática.
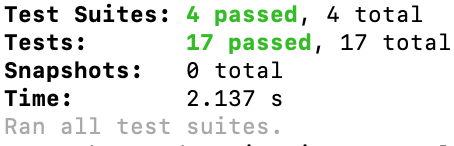
Para verificar se os testes estão funcionando, rode com um ‘npm test’ e se fez tudo certinho, verá uma beleza de bateria de testes tendo sucesso.
Para finalizar nosso micro serviço precisamos construir o nosso index.js que é praticamente idêntico ao do outro projeto, mudado apenas o módulo da API:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//index.js (async () => { require("dotenv-safe").config(); const cinemaCatalog = require('./api/cinemaCatalog'); const server = require("./server/server"); const repository = require("./repository/repository"); try { await server.start(cinemaCatalog, repository); console.log('Server is up and running at ' + process.env.PORT); } catch (error) { console.error(error); } })(); |
Isso deve ser o suficiente pra fazer o nosso serviço cinema-catalog-service funcionar. Com a criação deste segundo micro serviço, uma série de dúvidas devem lhe surgir, por exemplo, como manter controle dos múltiplos endpoints entre múltiplos microservices? Como garantir segurança de maneira uniforme entre os microservices sem ter de compartilhar dados de usuários autorizados entre todas bases de dados? E porque cinema-catalog-service não consome movies-service como imaginamos inicialmente?
Eu começo a responder estas e outras perguntas nos próximo posts, sobre API Gateways e JSON Web Token, além deste onde falo de boas práticas em arquiteturas de microservices e como refatorar um monolito em micro serviços.

Curtiu o post? Então clica no banner abaixo e dá uma conferida no meu livro sobre microservices com Node.js!






Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.