

Um caso de uso de Node.js muito comum, como já expliquei em outros artigos antes, é o de construção de webapis e microsserviços que aguentam grande carga de requisições. Até aqui, isso não deve ser novidade para você.
No entanto, uma fraqueza do Node (e do JavaScript em geral) é a sua performance não tão boa quando o assunto é processamento pesado e/ou tarefas bloqueantes que demoram um tempo razoável para serem concluídas. Isso no Node.js pode ser um grande ofensor uma vez que o event loop trabalha com single thread, certo? Bloqueie esta thread principal e os demais clientes chamando sua API terão uma experiência bem ruim…
Seja nos casos em que o volume de requisições exceda a sua capacidade de resolvê-las rapidamente ou nos casos em que o processamento seja demorado, adotar uma arquitetura que opere de forma assíncrona não apenas garante que você vai conseguir atender todas requisições como vai fazê-lo em um tempo adequado.
No tutorial de hoje vou falar de como construir uma arquitetura simples, porém robusta, usando Node.js e Redis para processamento assíncrono de requisições recebidas em uma web API RESTful.
#1 – Processamento Assíncrono
A explicação abaixo pode ser conferida no vídeo, ao invés de ler.

O primeiro conceito que você tem de entender é que apesar do HTTP ser síncrono, já faz quase 20 anos que a Internet (e os sistemas que rodam nela) já entendeu que trabalhar de maneira assíncrona é uma forma de proporcionar experiências cada vez melhores aos usuários.
Em uma requisição síncrona, a request é enviada ao servidor, que a processa e devolve uma response. Tudo de uma vez só. Enquanto a response não é retornada, a conexão fica presa e o usuário fica esperando. Se demorar demais, a conexão pode ser encerrada abruptamente e o cliente terá de fazê-la de novo, sem saber exatamente o que acontecer nesta segunda chamada.
Em uma requisição assíncrona, a request é enviada ao servidor, que registra a mesma e automaticamente responde ao cliente que vai realizar a tarefa em breve, avisando-o de alguma maneira quando ela for concluída. Um outro processo cuida de processar essa requisição armazenada e notificar o cliente de alguma forma, se necessário.
A imagem abaixo ilustra um pouco dessa diferença.
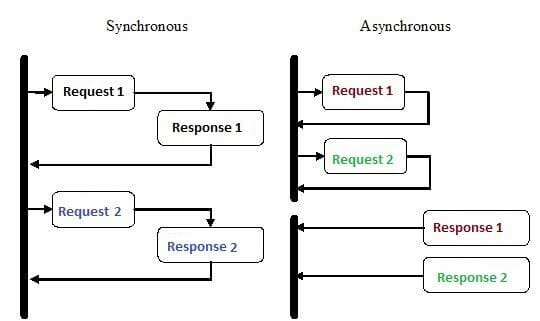
Obviamente o segundo modelo é um pouco mais complexo de lidar, mas possui algumas vantagens muito interessantes.
Enquanto que processamento síncrono dá uma resposta mais direta e rápida para o cliente quando o servidor não está sobrecarregado de requisições, é quando a carga de chamadas às suas APIs é muito alta que ele se mostra inviável. Neste caso, apenas registrar as requisições, para processá-las em uma fila, por exemplo, garante que todos vão ser atendidos, cada um no seu tempo e nenhuma request vai ser dropada.
Assim, pensando nessa arquitetura, eu proponho neste tutorial o uso de Redis, uma tecnologia poderosíssima que pode ser usada como fila para as suas requisições, visando processamento assíncrono pelo Node.js. Mais do que isso, implementaremos um padrão chamado PubSub, onde um elemento que seja publicado na fila (publish) possa ser consumido por diversos assinantes (subscribers).

#2 – O que é Redis?
Redis é um “banco de dados” (não confundir com SGBD) in-memory e open-source, usado geralmente como cache ou como message broker (tipo RabbitMQ e AWS SQS). Ele fornece estruturas de dados como strings, hashes, listas, conjuntos, conjuntos ordenados, bitmaps, índices geoespaciais, streams, entre outros. Falo mais sobre Redis no vídeo abaixo, caso prefira assistir ao invés de ler.

Apesar de ser muito associado como “banco em memória”, Redis tem diferentes níveis de persistência, transações, replicação e permite fazer clusterização. E apesar também de ser muito associado a estruturas chave-valor, ele permite uma grande gama de operações diferentes do que apenas consultar e armazenar baseado em chaves.
Neste tutorial usaremos ele como message broker, ou seja, como uma ferramenta que irá receber mensagens, vai enfileirar elas e depois vai entregar uma a uma aos destinatários. Isso garante que nenhuma requisição seja perdida, pois tudo que chegar será registrado, e que conforme as tarefas vão sendo executadas, os requisitantes vão sendo notificados. Isso pode ser feito na relação 1×1, que seria uma fila comum sendo consumida por um worker (processador de tarefas), como abaixo.

Ou na relação de 1:n, que costumamos chamar de PubSub, onde temos um único publisher (alguém que recebe e registra as requisições no canal) e vários subscribers (destinatários ou workers diferentes) que estão esperando por mensagens, como mostra a arquitetura abaixo.
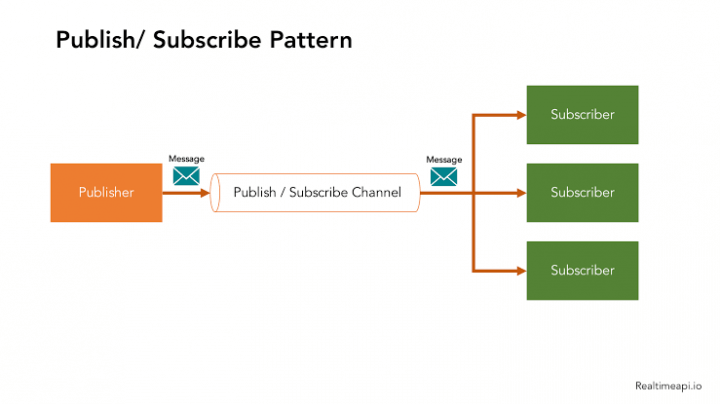
Em nosso exemplo, o Redis será o canal ali no meio, uma web API Node.js será o publisher e os subscribers podem ser workers escritos em qualquer tecnologia que converse com Redis. Faremos aqui com Node.js, por praticidade.
Para usuários Mac e Linux, existem pacotes prontos de Redis que você pode instalar via Homebrew ou APT (respectivamente). Outra opção de instalação, que também contempla usuários Windows é via imagem Docker que ensino a seguir, tanto no vídeo quanto no texto.

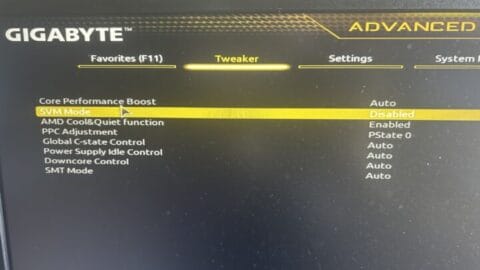
Para isso você vai precisar ter primeiro o Docker instalado na sua máquina, que você pode baixar e instalar executando até o final a partir do site oficial, Docker.com. O Docker vai exigir duas coisas para funcionar: no Windows, ele exige que seu WSL esteja habilitado e atualizado, mas não se preocupe, se isso estiver pendente, ele vai te avisar na inicialização e te dar os comandos de terminal que precisam ser executados. Outro requisitos é que você tenha suporte a virtualização de CPU habilitado na sua BIOS, algo que varia de computador para computador, então procure aí na sua e veja se está habilitado (exemplo da minha abaixo, ainda desabilitada, chamada SVM).
Com o Docker 100% operacional, é hora de criar seu container com Redis, usando o comando abaixo para a versão 8.2 (mais recente na data que escrevo este tutorial).
|
1 2 3 |
docker run -d --name redis -p 6379:6379 redis:8.2 |
Isso vai fazer com que seja baixado e executado localemente um container na porta 6379 com Redis na versão 8.2. Após a criação finalizar com sucesso, você pode testar a sua instância de Redis subindo o redis-cli (Redis Client) com o comando abaixo:
|
1 2 3 |
docker exec -it redis redis-cli |
Se tudo der certo, o terminal vai exibir uma conexão estabelecida e você poderá enviar comandos para o Redis.

#3 – Como usar com Node.js?
Se preferir, você pode assistir ao vídeo abaixo ao invés de ler o tutorial.

Para uso com Node.js você irá precisar de uma aplicação Node.js básica que você pode criar rapidamente aí na sua máquina e de uma biblioteca de uso do Redis para Node, como a Node Redis. Também aproveitarei para instalar o Express junto, pois vamos precisar mais à frente.
|
1 2 3 |
npm i redis express |
A Node Redis faz uma transcrição literal em JavaScript de TODOS os comandos possíveis de serem executados em um servidor Redis, mas aqui vamos fazer um uso bem simples dele. Abaixo, um exemplo simples de cliente que se conecta em um Redis padrão (localhost sem usuário e senha), e expõe duas funções, uma para publicar mensagens em um canal e outra para assinar mensagens de um canal. Chamei este módulo de queue.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
//queue.js const redis = require('redis'); const client = redis.createClient(); client.connect(); client.on("error", (error) => { console.error(error); }); async function publish(channel, value) { console.log('Message sent!'); return client.publish(channel, JSON.stringify(value)); } async function subscribe(channelSubscribed, callback) { client.subscribe(channelSubscribed, (channel, message) => { console.log('Message arrived!'); callback(message); }); } module.exports = { publish, subscribe } |
Aquele objeto client expõe todos os comandos existentes no Redis, amplamente documentados e que recomendo que você dê uma olhada caso queira ir além do publish e subscribe que usei ali, que são o básico do básico do Redis como message broker.
Eu criei este módulo genérico e separado para que possamos utilizá-lo tanto pelo publisher quanto pelo subscriber. Nosso publisher será uma web API Node.js e será muito simples, uma vez que o objetivo aqui não é ensinar a criar webapis. Apenas copie e cole o código abaixo em um arquivo publisher.js na raiz do projeto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
//publisher.js const express = require('express'); const app = express(); const queue = require("./queue"); app.use(express.json()); const router = express.Router(); router.post('/channel1', (req, res) => { queue.publish("channel1", req.body); res.json({ message: 'Your request will be processed by Channel 1!' }); }); router.post('/channel2', (req, res) => { queue.publish("channel2", req.body); res.json({ message: 'Your request will be processed by Channel 2!' }); }); app.use('/', router); app.listen(3000); |
Repare como tenho duas rotas POST que fazem a mesma coisa, mas em canais diferentes. Se você rodar esta web api com node publisher.js verá que ele recebe requisições normalmente se testar via Postman ou outro HTTP client. Essas requisições terão seus corpos enviados para o Redis como string (único formato suportado pela função publish).
Mas e agora, como fazemos os workers que vão consumir estes canais 1 e 2?

#4 – Subscribers/Workers
Da mesma forma, nosso worker de exemplo será muito simples, uma vez que não é o foco do artigo. Apenas copie e cole o código abaixo em um arquivo subscriber1.js na raiz do projeto:
|
1 2 3 4 5 6 7 8 9 |
//subscriber1.js console.log("Worker started"); const queue = require("./queue"); queue.subscribe("channel1", message => { console.log("processing"); console.log(message); }) |
Esse worker é muito simples, ele apenas fica escutando ao canal channel1 (a mesma em que o publisher vai jogar as mensagens) e quando chega alguma coisa lá, o callback pega a mensagem e apenas imprime o conteúdo no console. Você inclusive pode criar cópias deste worker para fazer testes mais elaborados de PubSub.
Uma vez que você já tenha o servidor de Redis rodando, testar é muito simples, basta subir a publisher.js via terminal, nossa web API, e depois subir um ou mais subscribers.js em outro terminal, em qualquer ordem.
Você deve começar o teste pelo publisher, ou seja, abra o POSTMAN e envie um objeto JSON qualquer via POST para localhost:3000/channel1 ou channel2 que isso deve disparar a mensagem pra fila que deve ser consumida pelos subcribers que estiverem ouvindo quase imediatamente.
Claro, este é um subscriber meeega simples. Subscribers reais vão processar dados da mensagem, fazer operações em banco e até mesmo chamar outras APIs se necessário, principalmente para avisar que essa requisição já foi processada. Você pode querer também alterar a interface para dar uma resposta ao usuário e por aí vai.
Um ponto importante: uma vez que use um cliente de Redis como publisher ou subscriber, você não conseguirá usar ele para outras atividades. Isso quer dizer que, se você quiser pegar/enviar dados ao Redis (principalmente dentro do callback de mensagem recebida), terá de inicializar outro cliente. Esse é um erro bem comum e passei muita raiva até entender, vai ter um erro de “can’t get in this context” ou algo assim.
Mas enfim, a ideia deste artigo era te ajudar a fazer o Redis funcionar como PubSub com Node.js e espero que você tenha conseguido. Caso contrário, apenas baixe os meus fontes usando o formulário ao final do tutorial.
Dois concorrentes do Redis para esta finalidade é o RabbitMQ e o AWS SQS.
Espero que tenha gostado do tutorial.
Um abraço e até a próxima!






Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.