Node.js
Arquitetura de micro serviços em Node.js + MongoDB
Node.js
TDD: Como criar unit tests em Node.js com Jest
Web3 e Blockchain
3 dicas para diminuir smart contracts Solidity
Node.js
Arquitetura de micro serviços em Node.js + MongoDB: Parte 4
Pesquisando...
Inicial
Guias de Estudo
Cursos
Livros
Parceiros
Sobre
Pesquisar
nodejs
Junte-se a mais de 34 mil devs
Entre para minha lista e receba conteúdos exclusivos e com prioridade
Enviar
Todos
.NET
Agile
Android SDK
Bot Cripto
Carreira
Corona SDK
Empreendedorismo
Livros
Mobile
Node.js
React Native
Web
Web3 e Blockchain
Node.js
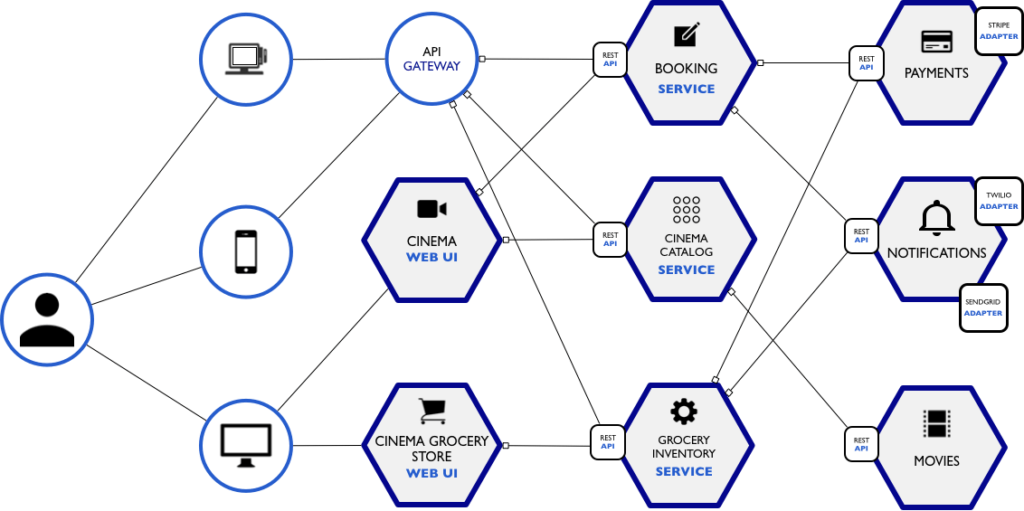
Arquitetura de micro serviços em Node.js + MongoDB
Node.js
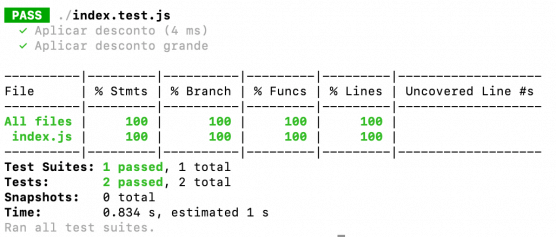
TDD: Como criar unit tests em Node.js com Jest
Node.js
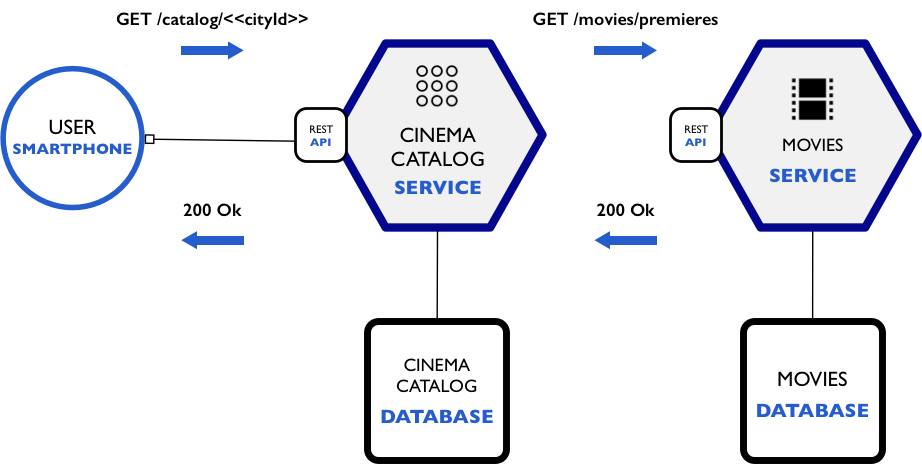
Arquitetura de micro serviços em Node.js + MongoDB: Parte 4
Web
Testes de front React com Storybook, Jest e Chromatic
Node.js
Arquitetura de micro serviços em Node.js + MongoDB: Parte 2
Node.js
Nodemail: Envio de email em ReactJS + Node.js + Nodemailer
Web
Como criar um frontend realtime com ReactJS e WebSockets
Node.js
Como enviar emails em aplicações NestJS
Bot Cripto
Como criar robô Trailing Stop para Binance Spot em Node.js
Bot Cripto
Como criar um bot para copy trade na Binance Spot com Node.js
Node.js
Como criar uma WebApi com Node.js, Express e TypeScript
Node.js
Como criar um encurtador de URL com Node.js e Sequelize
Node.js
Error Handling em Node.js com Express
Node.js
Como criar uma WebApi com Node.js, Express, TypeScript e MongoDB
Node.js
Arquitetura de micro serviços em Node.js + MongoDB: Parte 3
Node.js
Arquitetura de micro serviços em Node.js + MongoDB: Parte 5
Carregando mais conteúdo...
Entre para minha lista e receba conteúdos exclusivos e com prioridade
Junte-se a mais de 34 mil devs
Enviar
Categorias
.NET
(20)
Agile
(106)
Android SDK
(45)
Bot Cripto
(60)
Carreira
(76)
Corona SDK
(2)
Empreendedorismo
(68)
Livros
(58)
Mobile
(69)
Node.js
(211)
React Native
(16)
Web
(154)
Web3 e Blockchain
(107)
Últimas Novidades
Arquitetura de micro serviços em Node.js + MongoDB
TDD: Como criar unit tests em Node.js com Jest
3 dicas para diminuir smart contracts Solidity
Arquitetura de micro serviços em Node.js + MongoDB: Parte 4
Testes de front React com Storybook, Jest e Chromatic
Tags
agile
android
aws
blockchain
business
c#
camunda
carreira
corona
criptomoedas
digital ocean
heroku
ios
java
jira
mobile
mongodb
mssql
mysql
nestjs
nextjs
nodejs
phonegap
postgresql
prisma
react
redis
regex
resenha
seguranca
solana
solidity
sqlite
tdd
typescript
web
web3