
No tutorial de hoje vou lhe ensinar a como construir um CRUD utilizando Node.js e SQLite com o ORM Sequelize.
Não sabe o que é um ORM? O que é o Sequelize? Ou até sabe mas não faz a mínima ideia de como usar?
Então este tutorial é pra você.
Atenção: este é um tutorial para quem já conhece Node.js. Se você não conhece esta tecnologia, comece por algo mais introdutório.
Se preferir, assista ao vídeo abaixo onde dou a mesma introdução ao Sequelize, independente do banco de dados.

ORM
Quando estamos construindo aplicações com bancos de dados, independente da linguagem, existem muitas, mas muitas atividades repetitivas mesmo entre sistemas completamente diferentes. Uma delas é a escrita dos comandos e consultas SQL para fazer inserções, atualizações, etc nas tabelas do seu banco e a outra é o mapeamento das entidades e relacionamentos em objetos ou módulos da sua aplicação.
Mapear tabelas para código é um padrão muito comum independente de linguagem ou framework pois te permite programar mais próximo da regra de negócio da empresa, reduz a carga cognitiva de ficar chaveando mentalmente entre as diferentes camadas da aplicação e lhe dá muita produtividade, uma vez que, depois do mapeamento feito, atividades triviais, porém trabalhosas, como ficar escrevendo os mesmos SQLs de sempre se tornam apenas simples chamadas de funções ou métodos.
Ainda assim, fazer este mapeamento na mão também é extremamente penoso e coloca uma curva inicial de trabalho grande em novos projetos. Aí que entram os ORMs ou Object-Relational Mappers.
Um ORM é um framework que lhe permite fazer este mapeamento de forma automática, como o Entity Framework da Microsoft, ou de forma manual, mas extremamente simplificada, como o Hibernate da RedHat, sendo este segundo tipo o mais popular porque muitas vezes a mágica dos geradores automáticos de mapeamento criam código com baixa qualidade e/ou possuem funcionalidades mais limitadas.
Por exemplo, se você tem uma tabela de clientes, você pode ter uma classe ou módulo clientes na sua aplicação e ao invés de escrever um INSERT para salvar um novo cliente na base, você usaria uma função ou método save/add ou equivalente. Assim, você estará manipulando o banco SQL sem precisar escrever SQL de fato, usando apenas a sua linguagem de programação favorita.
Outra coisa bacana de trabalhar com ORMs é que muitas vezes eles atuam com mais de um banco, facilitando portar o seu código para diferentes mecanismos de persistência ou até em cenários de persistência poliglota.
Em Node.js, o ORM mais popular é o Sequelize.
Sequelize e SQLite
O Sequelize, segundo o site oficial, é um ORM para Node.js baseado em Promises, para os bancos PostgreSQL, MySQL, MariaDB, SQLite e MS SQL Server. Então se você não usa SQLite mas usa qualquer um desses outros bancos aí, deve conseguir adaptar este tutorial para sua realidade.
Entre suas principais características estão o suporte a transações sólidas (ACID), relacionamentos, eager e lazy loading (carregamento adiantado ou tardio), replicação de leitura e muito mais.
“Mas Luiz, se suporta todos estes bancos, porque você vai me ensinar com SQLite?”
Se você nunca utilizou SQLite antes, saiba que ele é o banco número 1 no mundo quando o assunto é banco SQL local para dispositivos móveis e embarcados. Deixando mais claro: a maioria dos apps em Android e iOS, bem como smart TVs e outros devices que precisam de um banco SQL local, costumam usar SQLite por ele ser gratuito, open-source, leve, baseado em arquivo local e que sobe junto com o processo da sua aplicação, sem a necessidade de instalação prévia ou processo próprio rodando em background como a imensa maioria dos bancos de dados.
Na verdade, o SQLite é uma biblioteca escrita em C que implementa a especificação SQL até certo ponto, lhe fornecendo um banco de dados, mas não um SGBD completo, se é que me entende, o que tem um fit muito grande com pequenas aplicações e pequenos volumes de dados (poucos GB).
Você vai ver como é fácil utilizar ele, vou mostrar na prática!
Mas indo ao que interessa, crie uma aplicação Node.js na sua máquina com npm init e instale as dependências do Sequelize e do SQLite no seu package.json.
|
1 2 3 |
npm install sequelize sqlite3 |
Agora crie um arquivo db.js na raiz do seu projeto para fazermos a primeira conexão com o banco de dados.
|
1 2 3 4 5 6 7 8 9 |
const Sequelize = require('sequelize'); const sequelize = new Sequelize({ dialect: 'sqlite', storage: './database.sqlite' }) module.exports = sequelize; |
O código é bem direto, ele carrega a dependência do Sequelize, inicializa um novo objeto usando o construtor dele que espera a configuração do banco. Esta configuração é o dialeto a ser usado (sqlite) e o arquivo onde nosso banco será salvo (estou salvando na raiz do projeto).
Não precisamos nos preocupar em explicitamente criar uma conexão aqui. Internamente o Sequelize vai gerenciar isso pra gente usando o conceito de connection pool, onde ele vai abrir e fechar diversas conexões conforme a necessidade, priorizando performance.

Model
O próximo passo é criar nosso model/modelo, um módulo que vai conter as informações do nosso mapeamento objeto-relacional, ou seja, o código JavaScript que vai representar uma tabela do banco de dados.
Assim como o banco de dados, esta tabela nem vai existir ainda no SQLite, ela será criada pelo Sequelize quando necessário.
Crie um arquivo produto.js para inserir o código de definição do nosso modelo de produto, como abaixo. A recomendação é um nome no singular pois representa o schema para um produto, que usaremos várias vezes. O próprio Sequelize depois vai pluralizar este nome (funciona melhor com nomes em Inglês, então não se surpreenda se aparecer algum plural estranho).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
const Sequelize = require('sequelize'); const database = require('./db'); const Produto = database.define('produto', { id: { type: Sequelize.INTEGER, autoIncrement: true, allowNull: false, primaryKey: true }, nome: { type: Sequelize.STRING, allowNull: false }, preco: { type: Sequelize.DOUBLE }, descricao: Sequelize.STRING }) module.exports = Produto; |
O que o código acima faz é carregar a dependência do Sequelize para que possamos usar algumas constantes dele. Depois carrega a dependência do nosso banco de dados, que configuramos anteriormente.
Com essa dependência do banco de dados, vamos usar a function define para criar o schema da nossa tabela, sendo o primeiro parâmetro o nome que a mesma vai possuir. Resista à tentação de usar nomes diferentes, recomendo que modelo e tabela possuam o mesmo nome.
O segundo parâmetro é a definição do schema em si, onde temos campos e propriedades, bem autoexplicativas. Para o tipo de cada coluna/propriedade, usamos as constantes existentes no Sequelize (INTEGER, DOUBLE, etc), além dos modificadores como autoIncrement, allowNull, primaryKey, etc.
No fim, apenas exportamos este model, para que possamos utilizá-lo na nossa aplicação de fato.
Aplicação
O próximo passo é utilizar estes módulos que criamos de fato na nossa aplicação.
Como mencionei antes, o Sequelize vai fazer a gestão não apenas das conexões com o banco, como a criação das tabelas necessárias, se elas ainda não existirem.
Então em nosso index.js, a primeira coisa que vamos fazer é um sync do Sequelize com nosso banco de dados, para que as tabelas sejam mapeadas corretamente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
//index.js (async () => { const database = require('./db'); const Produto = require('./produto'); try { const resultado = await database.sync(); console.log(resultado); } catch (error) { console.log(error); } })(); |
Aqui eu criei uma IIFE que será disparada assim que o index.js for chamado. Ela é necessária para que possamos usar async await neste módulo, funcionalidades mais modernas do JavaScript. Internamente ao IIFE o código não tem nada demais, eu carrego a dependência do nosso banco de dados e chamo a função sync, imprimindo no console o resultado ou o erro.
Essa função sync irá verificar se o seu model está batendo com o seu banco de dados. As tabelas que estiverem faltando, ele cria para você, quando necessário.
Quando você executar este index.js, vai ver como resultado um monte de código explicando o sync realizado. A menos que dê um erro, não tem nada demais aqui. Você vai notar que na raiz do seu projeto apareceu um arquivo database.sqlite também e inclusive você pode abri-lo usando aplicativos como o SQLite Browser.

Create
Agora vamos iniciar nosso CRUD com o C de Create.
O Sequelize fornece algumas funções de inserção de dados, sendo a mais direta delas a create, que cria imediatamente o registro na tabela com o objeto passado por parâmetro (o código abaixo deve estar logo depois do sync).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
//index.js (async () => { const database = require('./db'); const Produto = require('./produto'); try { const resultado = await database.sync(); console.log(resultado); const resultadoCreate = await Produto.create({ nome: 'mouse', preco: 10, descricao: 'Um mouse USB bonitão' }) console.log(resultadoCreate); } catch (error) { console.log(error); } })(); |
Ao rodar a aplicação agora você vai notar que no console vão aparecer sim algumas informações relevantes desta vez, como por exemplo o SQL que foi utilizado para criar a tabela (porque ela não existia) bem como o SQL do INSERT que foi gerado automaticamente para você.
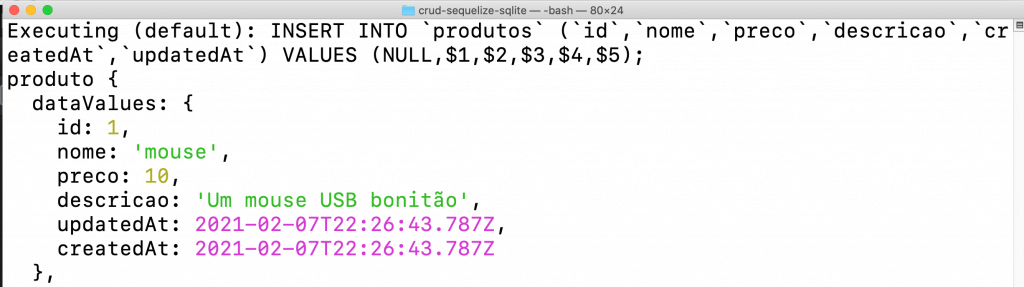
Aí que está uma das vantagens de usar um ORM!
Note que além de pluralizar o nome da tabela ao criá-la, o Sequelize também adicionou campos de timestamp para data de criação de data de atualização, que ele mesmo vai gerenciar, automaticamente.
E esse foi mais um brinde de usar Sequelize! 😀
Se você olhar no seu banco de dados com o SQLite DB Browser, verá que lá está uma tabela de produtos com este registro que acabamos de inserir.
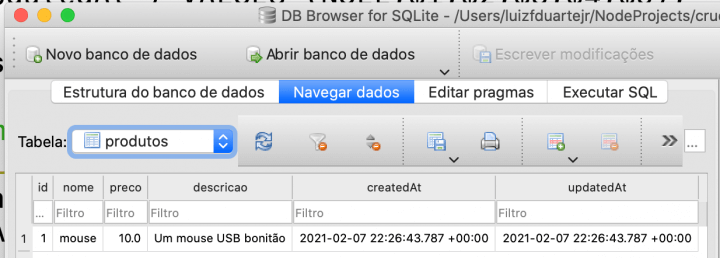
E com isso fechamos o CREATE!
Read
Agora vamos fazer o R do CRUD, de Read/Retrieve!
Ele é ainda mais simples do que o Create, basta usarmos a função findAll disponibilizada pelo nosso objeto Produto, que teremos um array de produtos à nossa disposição.
|
1 2 3 4 |
const produtos = await Produto.findAll(); console.log(produtos); |
Esta função findAll permite que a gente passe um objeto de opções por parâmetro para restringir os resultados da nossa consulta também, como mencionado na documentação oficial.
Outra opção, é usar a função findByPk para trazer apenas um produto baseado na chave-primária da tabela, ou seja, nosso id, como abaixo.
|
1 2 3 4 |
const produto = await Produto.findByPk(1); console.log(produto) |
E com isso, encerramos o R de Read/Retrieve!

Update
O próximo passo é atualizarmos um item da nossa tabela, o U do CRUD: Update!
Para atualizarmos um item, primeiro precisamos retorná-lo do banco de dados usando alguma função de find do Sequelize. No passo anterior, usamos a findByPk para retornar o produto com ID 1. Vamos escrever o nosso código de update imediatamente abaixo.
|
1 2 3 4 5 6 7 8 |
const produto = await Produto.findByPk(1); //console.log(produto); produto.nome = "Mouse Top"; const resultadoSave = await produto.save(); console.log(resultadoSave); |
Note que alterei apenas o nome do produto retornado pelo findByPk e depois chamei uma função save que vai justamente montar e executar o Update considerando apenas os novos valores do objeto produto.
Como resultado, apenas imprimo no console e você verá o UPDATE construído, bem como se olhar na base de dados, verá a linha da tabela atualizada.
Com isso, fechamos nosso update!
Delete
E por fim, vamos ao D do CRUD, de DELETE!
Assim como para salvar e retornar dados existem diversas formas de fazer, para o Delete não é diferente. Você pode usar Produto.destroy e passar um where por parâmetro, ou então retornar um produto e usar a função destroy do próprio objeto retornado, você decide.
|
1 2 3 4 5 6 7 8 |
//assim Produto.destroy({ where: { id: 1 }}); //ou assim const produto = await Produto.findByPk(1); produto.destroy(); |
A esta altura, o trecho de código acima é bem autoexplicativo e ambos os trechos fazem exatamente a mesma coisa, embora o primeiro seja mais performático.
D do CRUD? Check!
E com isso finalizamos este tutorial em que você aprendeu como fazer um CRUD bem simples usando Node.js, Sequelize e SQLite.
Tenho certeza que juntando com outros conhecimentos de Node.js vai lhe permitir construir aplicações de verdade, como este encurtador de URL que ensino a construir (incluindo videoaula)!
Um abraço e até a próxima!
Quer aprender a construir aplicações profissionais usando Node.js, Sequelize, banco SQL e muito mais? Clica no banner abaixo e conheça meu curso!






Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.
Gostei fiz pelo tutorial esquito do blog obrigado!!
Fico feliz que tenha gostado!