
Recentemente escrevi um artigo ensinando sobre como usar a técnica de mocking, muito popular e útil para TDD, com a suíte de testes Jest, para aplicações Node.js. No entanto, senti que alguns conceitos importantes não foram abordados e que podem levar a um uso equivocado da técnica, impactando principalmente na cobertura de código da sua aplicação (code coverage).
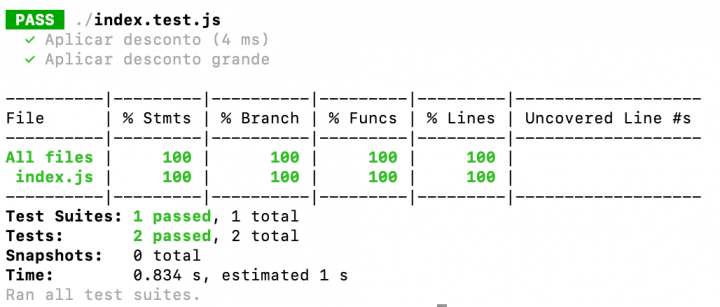
Se você usa Jest há algum tempo, deve saber que um dos grandes benefícios dele em relação a outras suítes como Tape é a coleta de coverage metrics. Ele não apenas roda suas baterias de testes automatizados como faz a análise e apresenta métricas da proporção de testes varrendo todo o seu código, como na imagem acima.
No entanto, quando começamos a mockar nossas funções, a tendência é que os testes comecem a percorrer as funções fake e não as reais, portanto caindo drasticamente a nossa cobertura de código pois ele de fato não está sendo testado, mas sim mockado. Por exemplo, o relatório abaixo é de um projeto real, que estava com +80% de cobertura de código com testes mas que caiu drasticamente por causa de apenas dois pequenos módulos que foram mockados.
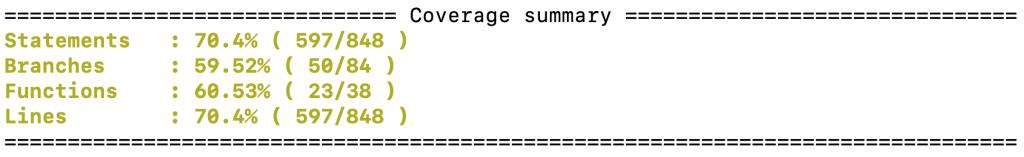
Mas o que fazer nestes casos então, devemos usar mocks e abandonar coverage? Ou devemos focar em coverage e abandonar mocks?
Nenhum dos dois, devemos primeiro entender o que devemos e mockar e o que não devemos mockar!

O que devemos mockar?
O intuito e benefícios de utilizar mocking foi dito no último artigo, mas talvez não tenha ficado claro, então vou explicar de forma diferente.
Partes da sua aplicação como um todo não são de sua gestão ou controle. Por exemplo, sua aplicação usa o pacote fs? Se o fs se comporta estranho, você mexe no fonte dele, escreve testes e commita no repo? Até poderia, já que o Node.js é open-source, mas esse é um exemplo de aspecto da sua aplicação que você não gerencia, mas depende para o seu código funcionar, toda vez que quer mexer no sistema de arquivos.
O mesmo vale para o seu banco de dados e APIs externas. Sua aplicação depende deles para funcionar, mas você não gerencia o código deles, apenas usa, geralmente através de pacotes que, apesar de serem open-source muitas vezes, você não gerencia com frequência também.
Esses pacotes e recursos não-gerenciáveis por você, cujo código você usa mas não mexe, são os fortes candidatos a serem mockados. Porque eles costumam muitas vezes tornar os seus testes dependentes, acoplados, lentos e falhos, além de exigir muito setup e cleanup, antes e depois dos testes respectivamente.
Tentando trazer de uma maneira bem prática, se você se focar em mockar módulos da node_modules ao invés de seus módulos, você estará atacando o mal das dependências na raiz e ao mesmo tempo poderá seguir buscando uma alta cobertura de testes no SEU código, pois o código da node_modules não entra no coverage report.
Para ajudar a tornar esta explicação mais convincente, vou trazer um case que acho que pode ajudar: mocks do Sequelize.

Sequelize Mock
Quando trabalhamos com bancos SQL é muito comum o uso de ORMs, que são bibliotecas que nos facilitam muito a vida mapeando as tabelas do banco em objetos na nossa aplicação. Em Node.js, o ORM mais popular é o Sequelize, que já ensinei a usar aqui no blog antes.
Ele possui suporte a vários bancos SQL diferentes e você cria e manipula os schemas e dados de maneira completamente agnóstica de vendor. O exemplo abaixo é de definição de uma tabela de clientes, por exemplo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
//cliente.js const Sequelize = require('sequelize'); const database = require('./db'); const Cliente = database.define('cliente', { id: { type: Sequelize.INTEGER, autoIncrement: true, allowNull: false, primaryKey: true }, nome: { type: Sequelize.STRING, allowNull: false }, idade: { type: Sequelize.INTEGER }, uf: { type: Sequelize.STRING(2) } }, { timestamps: false }) module.exports = Cliente; |
Sendo que este model cliente.js usa um módulo db.js, como abaixo:
|
1 2 3 4 5 6 7 8 |
//db.js require('dotenv-safe').config(); const Sequelize = require('sequelize'); const sequelize = new Sequelize(process.env.DATABASE_URL, {dialect: 'mysql'}); module.exports = sequelize; |
Querendo ver estes dois módulos em ação, você vai precisar instalar os módulos sequelize, mysql2, dotenv-safe e do jest, além de um banco MySQL criado e sua connection string definida em um arquivo .env, com uma variável DATABASE_URL (olhe o .env.example dos fontes do tutorial se quiser fazer isso).
Uma coisa muito comum é a gente não manipular diretamente o Sequelize na aplicação, mas ao invés disso, criamos um módulo de repositório, como abaixo:
|
1 2 3 4 5 6 7 8 9 10 |
//clienteRepository.js const Cliente = require('./cliente'); function findAll(limit) { return Cliente.findAll({ limit }); } module.exports = { findAll } |
E com uma chamada como abaixo você faz ele funcionar via index.js, retornando 10 clientes do banco de dados.
|
1 2 3 4 5 6 7 8 9 |
(async () => { const repository = require('./clienteRepository'); const clientes = await repository.findAll(10); console.log(clientes); })(); |
Aqui eu criei uma IIFE que será disparada assim que o index.js for chamado. Ela é necessária para que possamos usar async await neste módulo, funcionalidades mais modernas do JavaScript. Internamente ao IIFE o código não tem nada demais, apenas uma chamada ao módulo de repositório que criamos.
Enquanto que o código abaixo poderia ser o index.test.js dentro de uma pasta __tests__
|
1 2 3 4 5 6 7 8 9 |
//__tests__/index.test.js const repository = require('../clienteRepository'); test('findAll', async () => { const result = await repository.findAll(10); expect(result.length).toEqual(10); }) |
O que acontece se eu rodar este teste?
Se eu tiver configurado o .env corretamente, se eu tiver criado o banco corretamente no MySQL e se nele tiver uma tabela clientes com 10 registros, ele deve passar com sucesso. No entanto, se qualquer uma destas variáveis der uma leve oscilada, ele não vai funcionar. Agora escale isso mentalmente para dezenas ou centenas de testes (algo normal em um projeto de médio porte) necessitando de vários bancos, várias tabelas e de registros específicos nelas para funcionar.
Certo, isso é a parte mais simples e óbvia. Temos que mockar este recurso de banco de dados, certo?

Como mockar o Sequelize?
Se você pegar o que ensinei no último tutorial e não pensar muito a respeito, a primeira coisa que você tende a fazer é criar uma pasta __mocks__ dentro de libs e colocar um clienteRepository.js dentro dela, mockando a função findAll, certo?
No entanto, se você fizer isso, você não estará testando o MySQL (ok) e nem o seu clienteRepository (não ok), sua cobertura de teste ficará baixíssima. E isso não é legal. O SEU código DEVE estar sendo testado e com uma boa cobertura de testes ainda por cima (>80%). Sendo assim, você NÃO deve mockar ele, mas sim, mockar o código DOS OUTROS, como o código interno do Sequelize, por exemplo.
Para isso, você pode usar o pacote sequelize-mock que facilita bastante esta atividade (ou o seu fork mais moderno, o sequelize-mock-v5). Com ele, você cria os mocks dos models e o retorno das queries. Por exemplo, abaixo, temos um clienteMock.js usando sequelize-mock.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
const SequelizeMock = require('sequelize-mock'); const dbMock = new SequelizeMock(); const ClienteMock = dbMock.define('cliente', { id: 1, nome: 'Luiz', idade: 32, uf: 'RS' }); ClienteMock.$queryInterface.$useHandler((query, queryOptions, done) => { if (query === 'findAll') { const limit = queryOptions[0].limit ?? 10; const result = []; for (let x = 0; x < limit; x++) result.push(ClienteMock.build({ id: x, nome: 'cliente ' + x, idade: x, uf: 'RS' })); return result; } }) module.exports = ClienteMock; |
O define do SequelizeMock já define um objeto padrão para aquele model, que será retornado por padrão quando chamarmos as funções de query do Sequelize, que são todas sobrescritas pelo sequelize-mock. Caso queiramos resultados diferentes para as consultas que serão testadas, podemos usar a estrutura $querInterface.$useHandler para definir comportamentos específicos, como fiz acima com o findAll que vai retornar um array de elementos conforme o limit especificado.
Note como usei o parâmetro query para ver o nome da função chamada e o queryOptions para pegar os parâmetros dela (limit no caso). Também usei uma função build para criar um novo objeto mockado de ClienteMock.
Para usarmos este mock do model de Cliente ao invés do original nos testes do nosso repositório, precisamos injetá-lo sobre o módulo original. Podemos fazer isso usando o próprio Jest, como fiz abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//__tests__/index.test.js const repository = require('../clienteRepository'); jest.mock('../cliente', () => { return require('../clienteMock'); }); test('findAll', async () => { const result = await repository.findAll(10); console.log(result); expect(result.length).toEqual(10); }) |
No código acima, importamos o repositório normalmente, não há qualquer alteração necessária nele. Depois, usamos o jest.mock para dizer que o módulo cliente em memória deve ser substituído pelo clienteMock, o que vai afetar diretamente o comportamento do repository.findAll no teste interno e qualquer outra função de teste que usaria originalmente o model cliente, mesmo que internamente.
Assim, esse teste irá funcionar independente das suas variáveis de ambiente para o Sequelize, independente das suas configurações do banco de dados e independente dos registros existentes na tabela de clientes. Ele é um teste unitário da função findAll do clienteRepository. Ponto.
Note no entanto, que o Jest está achando que devemos ter cobertura de código no módulo de mock, quando na verdade isso é um engano.
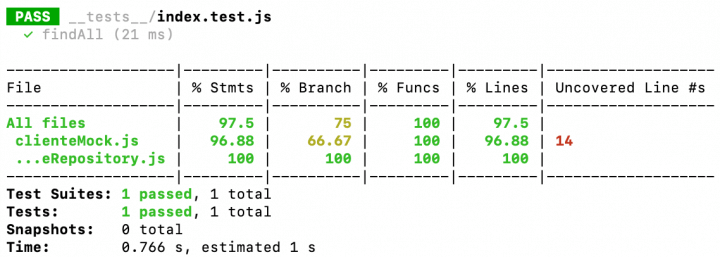
Para resolver isso, vamos colocar todos nossos mocks em uma pasta __mocks__ na raiz do projeto e renomear o arquivo clienteMock.js para cliente.js. Desta forma, podemos simplificar o mock do Jest.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
//__tests__/index.test.js const repository = require('../clienteRepository'); jest.mock('../cliente'); test('findAll', async () => { const result = await repository.findAll(10); console.log(result); expect(result.length).toEqual(10); }) |
Isso porque o Jest entende que deve existir uma pasta __mocks__ no mesmo nível do módulo cliente que ele deve mockar e que dentro desta pasta ele deve procurar um outro cliente.js para substituir o original. Além disso, arquivos na pasta __mocks__ não são computados na cobertura de código. Repare como o arquivo clienteMock.js não é mais citado no arquivo abaixo e nossa cobertura foi a 100%.

Rodando os testes agora, você manterá uma cobertura de teste alta sobre o SEU código. O código do Sequelize, esse sim não estará sendo testado, ou sequer a infraestrutura do MySQL, mas isso não é responsabilidade dos testes unitários, certo?
Outras coisas comuns de querermos fazer com Sequelize Mock é sobrescrever as funções estáticas do model, como a count por exemplo. Escreva o código abaixo dentro do arquivo do ClienteMock.
|
1 2 3 |
ClienteMock.count = () => { return 10; } |
E por último, outra customização útil é sobrescrever métodos de instância, como o save, para fazer valer regras do seu banco que por padrão o mock não daria bola como constraints.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
const ClienteMock = dbMock.define('cliente', { id: 1, nome: 'Luiz', idade: 32, uf: 'RS' }, { instanceMethods: { save: function () { if (this.nome.length > 150) throw new Error('MAX LENGTH ERROR'); this.id = 2; return this; } } }); |
Note que esta função save só existe em objetos que você tenha criado usando ClienteMock.build(), como mostrei antes!
Você ainda pode querer testes integrados, mas em menor volume, bem como ainda pode querer testes manuais, em volume menor ainda, mas o seu código, esse sim você deve ter um grande volume e rodar muitas e muitas vezes a cada alteração no projeto, adição de funcionalidades, refatorações, antes de deploy, etc.
E para conseguir isso sem ter uma série de problemas, você precisa aplicar técnicas como mocking corretamente. Por isso escrevi este artigo. 🙂
Espero ter ajudado.
Um abraço e sucesso.






Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.