
Que os bancos não relacionais revolucionaram a indústria de banco de dados, isso não podemos negar. Inicialmente com grande foco em Big Data e mais tarde como alternativas à abordagem relacional para resolver problemas específicos, como falo neste artigo.
No entanto, cada um deles possui todo um paradigma diferente de modelagem de seus dados, enquanto nos bancos relacionais de diferentes fabricantes temos o mesmo paradigma, o que acaba causando muita confusão, mesmo entre desenvolvedores veteranos.
Especificamente falando do MongoDB, o NoSQL mais popular do mercado, iniciei no artigo passado uma série sobre padrões de modelagem baseado em documentação oficial dos arquitetos do MongoDB, de onde vem também a imagem abaixo que resume os padrões definidos e suas aplicações na indústria. 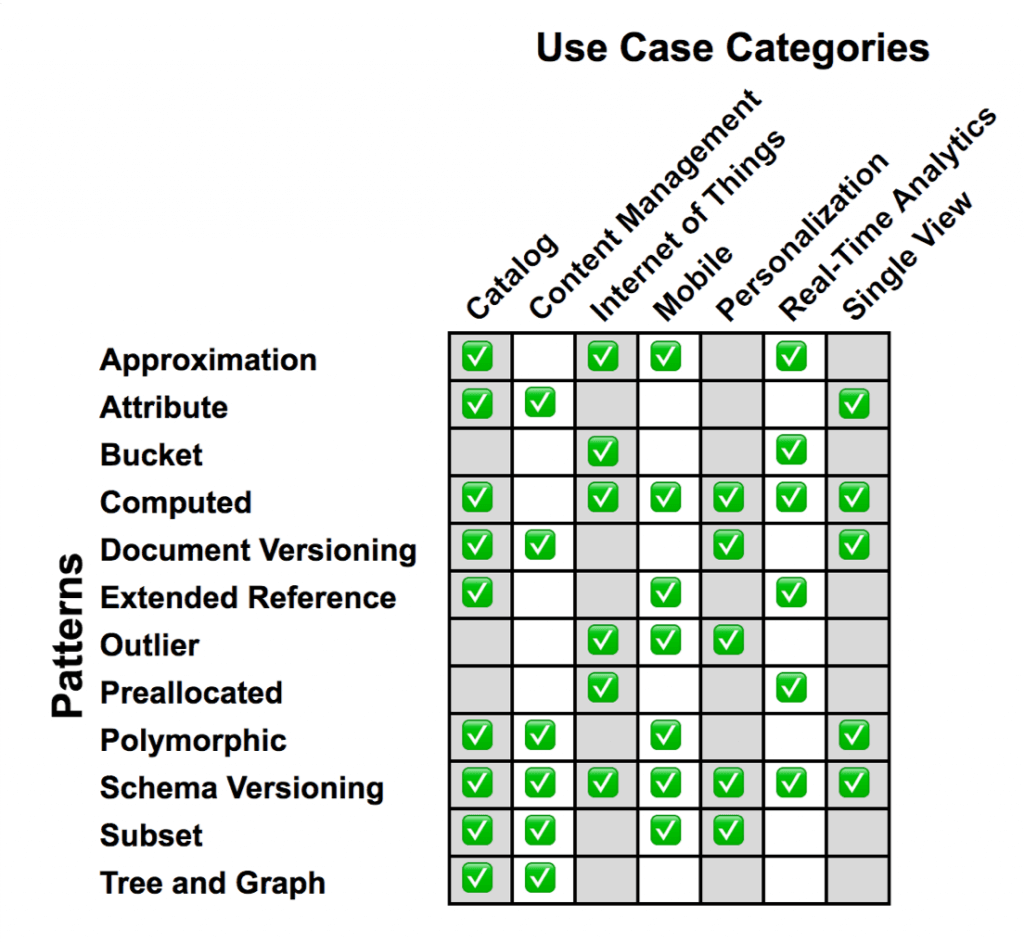 Os padrões que já exploramos até o momento foram:
Os padrões que já exploramos até o momento foram:
- Approximation: para maior performance em escrita de estatísticas mas com menos precisão, adicionando uma camada de controle na aplicação;
- Attribute: para maior performance em buscas de campos similares que estão sofrendo com múltiplos índices, tornando-os um atributo array;
- Bucket: para reduzir o tamanho da base que cresce rapidamente com registros em real time, agregando-os em documentos;
- Computed: para aumentar a performance de consulta de agregações de dados que podem ser pré-computados;
Seguiremos vendo mais padrões hoje, na parte 2 desta série.

Document Versioning
Este padrão, Versionamento de Documento, é útil quando você precisa manter versões anteriores de um mesmo documento, para fins de histórico, mas o mais comum de ser acessado é o atual. Ex: contratos e leis que são alteradas ao longo do tempo mas que não podem ser simplesmente sobrescritas/atualizadas.
Para resolver este problema, cria-se uma coleção para fins de histórico do documento em questão e coloca-se um campo para versionamento do mesmo (um id, uma data, etc). Na coleção principal, fica sempre a versão mais recente do documento, para consulta rápida, e na coleção secundária, todas as versões, sendo esta uma coleção muito maior e consequentemente mais lenta para consulta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
//único documento na coleção principal para este cliente { _id: ObjectId<ObjectId>, name: 'Bilbo Baggins', revision: 2, items_insured: ['Elven Sword', 'One Ring'], ... } //documentos existentes na coleção de arquivo { _id: ObjectId<ObjectId>, name: 'Bilbo Baggins', revision: 1, items_insured: ['Elven Sword'], ... } { _id: ObjectId<ObjectId>, name: 'Bilbo Baggins', revision: 2, items_insured: ['Elven Sword', 'One Ring'], ... } |
Como desvantagens deste padrão temos o dobro de escritas (sempre uma vez na coleção corrente e outra na coleção arquivo) e também deve ajustar sua aplicação para sempre pegar o documento da coleção certa.
Mais informações em Document Versioning.
Extended Reference
Este padrão, Referência Extendida, é útil quando você teria de fazer diversos JOINs no modelo relacional para ter os dados que precisa que sejam exibidos juntos no sistema com grande frequência, juntando dados de diversas tabelas. Ex: catálogo de produtos, ordem de compra em um ecommerce, prontuário médico de paciente, etc.
Para resolver este problema, mantém-se a divisão em várias coleções, porém agregam-se os dados mais necessários de maneira duplicada no documento principal. Por exemplo, uma ordem de pedido, ao invés de ter apenas o id do cliente que fez a compra, pode ter também seu nome e seu telefone principal, bem como o nome, quantidade e preço de cada produto adquirido, que são os dados que serão exibidos no sistema na tela de resumo do pedido.

Na minha opinião, esse é um dos padrões que mais usei nos projetos que apliquei MongoDB como persistência e até conhecer esse nome eu chamava de Light Sub-documents, pois já entendia que usar versões menores (mais “light”) de documentos maiores funcionava muito bem nesse modelo de banco.
A desvantagem mais óbvia deste padrão é a duplicação dos dados entre os diferentes documentos, então o ideal é não fazer uma referência extendida de campos que possam mudar com frequência.
Mais informações em Extended Reference.

Outlier
Este padrão, Caso Isolado, é útil quando sua coleção está modelada de um jeito bacana, mas alguns documentos dela fogem à regras gerais que você criou, o que pode pôr abaixo toda a modelagem da maioria, por causa de um problema de poucos documentos. Ex: um usuário de rede social que tem os seus amigos em um array, mas alguém muito popular, tem tantos amigos, que não cabe em um array do MongoDB. Um documento de produto que possui fotos junto dos dados do produto, mas que alguns possuem tantas fotos que não cabem no mesmo documento.
Para resolver este problema, mantém-se na coleção os documentos com a modelagem que atende à maioria. No documento que foge à regra de modelagem, cria-se um campo que sinaliza que este documento possui dados adicionais, em outra coleção, como abaixo, de um documento de livro que contém tantos clientes que compraram ele, que precisa alocar os clientes adicionais em outra coleção (has_extras sinaliza isso).
|
1 2 3 4 5 6 7 8 9 10 |
{ "_id": ObjectID("507f191e810c19729de860ea"), "title": "Harry Potter, the Next Chapter", "author": "J.K. Rowling", …, "customers_purchased": ["user00", "user01", "user02", …, "user999"], "has_extras": "true" } |
A aplicação então, quando vai carregar os dados deste documento, ao encontrar a flag de que possui campos adicionais, os procura na outra coleção, usando o _id do documento original como filtro.
É verdade que o schema em MongoDB é dinâmico e que você pode pensar que não faz sentido este padrão se simplesmente podem haver campos diferentes entre os documentos. No entanto, existem limites do próprio MongoDB, de itens em um array, de KB em um documento e por aí vai.
Assim, ao invés de particionar toda sua coleção por causa de poucos documentos, você mantém os dados juntos e somente nos documentos que é necessário o particionamento, você o faz.
A desvantagem desta padrão é que a aplicação tem de manter este controle, de carregar dados adicionais quando encontrar a flag, adicionando complexidade adicional. Além disso, esses Casos Isolados terão uma performance inferior do que o normal da aplicação.
Mais informações em Outlier.
Pre-allocation
Este padrão, Pré-alocação, é útil quando você sabe a estrutura exata que seu documento vai ter e a sua aplicação apenas vai preenchê-lo com dados. Ex: documento de sala de cinema que já poderia ter os subdocumentos dos assentos pré-alocados.
Este padrão era mais útil nas versões anteriores à 3.2 do MongoDB, quando alocar espaço de maneira adiantada dava ganhos de performance no antigo sistema de arquivos MMAPv1. Com o advento do Wired Tiger e consequente descontinuação do MMAPv1, ele não é mais tão útil quanto antigamente.
A vantagem desta solução é a simplicidade da solução apenas, já que a performance não é mais significativa na alocação de espaço e como desvantagem temos o uso mais intenso de disco e memória por causa dos documentos maiores desde o início.
Sinceramente? Não vejo mais utilidade neste pattern, mas pode ser miopia da minha parte.
Para mais informações, leia Pre-allocation.
Na próxima parte desta série (clique aqui para ler), vou explicar os 4 últimos padrões de modelagem do MongoDB. Até lá!
* Espero que este artigo tenha sido útil para você que está aprendendo MongoDB. Para conteúdo mais aprofundado, recomendo meus livros. Para videoaulas, recomendo o meu curso online (abaixo).







Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.