

Nos últimos anos, além do REST como padrão consolidado para backend, um novo padrão vem sendo cada vez mais difundido devido ao fato que ele tem algumas vantagens em relação ao REST em alguns cenários: o GraphQL. Não exatamente uma novidade, já que o Facebook já criava suas APIs com esse padrão em 2012 (chamada na época de GraphAPI), mas foi só em 2015 que publicaram uma especificação aberta para a comunidade, ajudando na sua popularização.
Como todo padrão aberto, existem diversas implementações de GraphQL e neste tutorial eu vou, além de explicar o que é e para que serve GraphQL, mostrar como implementar uma API neste padrão usando Node.js, Express e TypeScript, uma combinação muito popular.
Se preferir, você pode assistir ao vídeo abaixo ao invés de ler, o conteúdo é o mesmo.
Vamos lá!
#1 – O que é o GraphQL?
Ao invés de te dar uma definição genérica do que é o GraphQL e para que ele serve, acho que convém primeiro te explicar a problemática por trás de sua criação. Quando criamos uma API REST, temos de antemão pensar em como os dados serão consultados e manipulados, certo? Isso porque os endpoints devem estar hard-coded em nosso backend, como uma rota GET /customers para listar os clientes ou outra POST /customers para salvar um. No entanto, esta abordagem rígida do REST traz dois problemas para muitas aplicações modernas.
Primeiro, se eu quiser filtrar clientes por um campo específico e não previsto inicialmente, ou eu tenho de criar e publicar uma nova rota (algo que pode levar tempo e até mesmo envolver outras pessoas) ou então eu tenho de retornar todos e fazer o filtro do meu lado, o que gera muito desperdício de tempo e processamento.
Segundo, se eu quiser utilizar apenas alguns dados dos clientes, ainda assim eu terei de receber todos os dados e pegar apenas o que eu preciso, gerando desperdício de tráfego na rede e consequentemente afetando o tempo no lado do usuário.
A ideia central do GraphQL é justamente permitir o data fetching declarativo, ou seja, quem está pedindo os dados é que decide como eles devem ser filtrados e quais dados devem ser retornados, e não o backend. De uma maneira grosseira de explicar, pense em uma API onde você mandasse a consulta SQL que deseja que ela execute do outro lado. Não é isso que GraphQL faz, não literalmente, mas ajuda a ilustrar bem o conceito.
Resumidamente, o GraphQL então é uma linguagem de consulta e manipulação de dados que permite a leitura dinâmica, escrita (chamada de mutação) e assinatura de alteração de dados (via websockets).

#2 – Setup do Express
Existem duas abordagens comuns para implementar APIs com GraphQL no mercado atualmente: com Apollo ou com Express. Neste tutorial vamos fazer com a segunda opção e em outro momento devo trazer algo com a primeira também. Como em qualquer fluxo de aprendizado de backend, vamos ver primeiro como fazer um CRUD com GraphQL, mais tarde trazendo aspectos mais intermediários como autenticação e até mesmo real-time (websockets).
Crie um novo projeto Node.js, inicialize o package.json e instale as seguintes dependências:
|
1 2 3 4 |
npm init -y npm install express express-graphql graphql |
A saber:
- Express: servidor web que vamos usar;
- GraphQL: pacote base do GraphQL para parsing de schemas, queries, etc
- Express-GraphQL: pacote para conseguir servir o GraphQL a partir do Express;
Na sequência ajuste o package.json para inicialização no index.js (que ainda não temos) e uso de ESModules:
|
1 2 3 4 5 6 |
"type": "module", "scripts": { "start": "npx nodemon index.js" }, |
Agora crie um servidor Express bem simples, como abaixo, em um arquivo index.js:
|
1 2 3 4 5 6 7 8 |
import express from "express"; const app = express(); app.use(express.json()); app.listen(3000, () => console.log("Servidor escutando na porta 3000...")); |
Teste ele subindo a aplicação pra ver se fez tudo certo até aqui.

#3 – Consultando com GraphQL
Agora que temos o servidor Express rodando, vamos configurar o GraphQL nele. Comece criando uma pasta graphql na raiz do projeto e dentro dela um schema.js, com o seguinte conteúdo, que explicarei a seguir:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import { buildSchema } from "graphql"; export default buildSchema(` type TestData { text: String! views: Int! } type RootQuery { hello: TestData! } schema { query: RootQuery } `); |
O import no topo serve para pegarmos a função buildSchema, que, recebendo uma string no padrão do GraphQL, monta internamente o grafo de informações para parsing posterior. No schema nós definimos as queries que vamos suportar, com o type RootQuery. No RootQuery, definimos cada uma das consultas e o tipo de retorno delas. No nosso caso, estou definindo apenas uma query chamada hello (atenção à esse nome) que retornará obrigatoriamente (o “!” garante isso) um objeto do tipo TestData. Já o tipo TestData possui duas propriedades obrigatórias: text e views.
Atenção aqui que o schema NÃO É JSON, ok? É parecido, mas não é igual.
Com o schema definido, ou seja, a estrutura de consultas e tipos da nossa API GraphQL, vamos criar outro arquivo na pasta graphql chamado resolvers.js:
|
1 2 3 4 5 6 7 |
export default { hello(){ return { text: "Hello World!", views: 100 }; } } |
Um resolver é basicamente uma função que é disparada quando uma determinada query é feita, ou seja, se temos uma query com nome “hello” no schema, temos de ter um resolver de mesmo nome para que essa query funcione, que é o que fiz acima. O objeto retornado atende perfeitamente ao schema dessa query, conforme vimos antes.
Agora vamos integrar o GraphQL ao Express, pra ele ser servido no endpoint graphql:
|
1 2 3 4 5 6 7 8 9 10 11 |
import { graphqlHTTP } from "express-graphql"; import schema from "./graphql/schema.js"; import resolvers from "./graphql/resolvers.js"; app.use("/graphql", graphqlHTTP({ schema, rootValue: resolvers, graphiql: true })); |
Aqui não tem muito mistério: começamos importando a dependência do express-graphql, do schema e do arquivo de resolvers, para então fornecer na rota /graphql o middleware do mesmo. O último parâmetro não importa agora, vou falar dele depois. Agora suba o seu servidor novamente e vá ao Postman para fazermos o teste, lembrando que ele tem de ser um POST, por isso a necessidade de ferramenta.
No Postman você vai criar um POST para o endereço do seu servidor, mais especificamente no endpoint onde está servindo o GraphQL. O grande segredo aqui é o conteúdo do body da requisição, que deve ser um JSON uma propriedade query, do tipo string, com um objeto contendo o schema da consulta. Neste schema, você informa o nome do resolver a ser utilizado e entre chaves, os campos que deseja ter no retorno, separados por espaço, como abaixo.
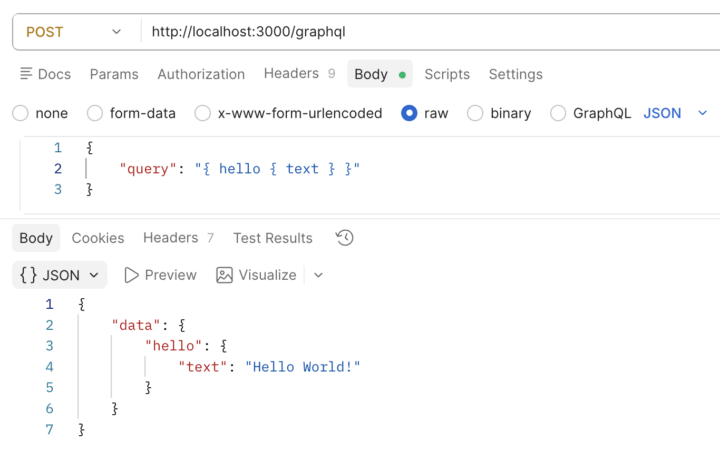
E essa é uma vantagem do GraphQL que foi citada antes, quem chama a API é que escolhe os dados que vai receber. Assim, quando essa requisição chega no server GraphQL, a query é analisada, o resolver é acionado e somente os dados necessários são incluídos na resposta, que você consegue ver no body da response na imagem acima. Apesar do hello possuir text e views, a requisição só pediu text e assim foi retornado.
Este meu exemplo é bobo e não faz nada relevante, mas imagine que ele poderia fazer uma consulta no banco de dados, por exemplo.

#4 – Mutações no GraphQL
Antes de avançarmos, lembra que eu deixei um parâmetro sem explicação na inicialização do GraphQL? O parâmetro graphiQL fornece pra gente uma interface gráfica para consultas quando você faz um GET no endpoint do GraphQL, assim você consegue testar diretamete do navegador.
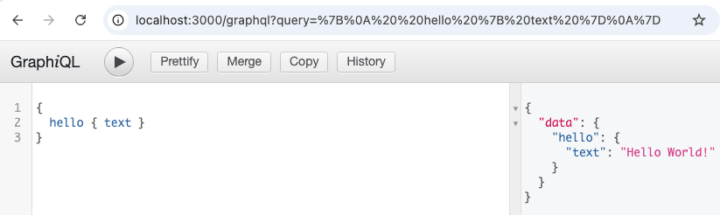
Mas vamos falar agora de mutations, ou seja, operações de escrita usando API GraphQL. O primeiro passo, assim como fizemos antes, é ir no schema.js e criar o schema, sendo que estou mostrando abaixo apenas o que mudou ou é novidade.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
input UserInputData { name: String! email: String! password: String! } type User { id: ID! name: String! email: String! logs: [String!] } type RootMutation { createUser(userInput: UserInputData): User! } schema { query: RootQuery, mutation: RootMutation } |
No schema definitions na propriedade mutation, o type que lista as funções de escrita (mutações). Tanto as funções de escrita quanto de leitura podem ter parâmetros, sendo que neste caso eu defini um userInput do tipo UserInputData, que definimos logo acima. Como toda boa função, também temos um retorno, que eu definir como obrigatório (!) e como sendo do tipo User, também descrito mais acima.
O tipo User possui alguns campos aleatórios, sendo que dois nos ensinam coisas novas: o id, que é do tipo especial ID (isso diz para o GraphQL que este é o identificador único da entidade) e o logs, que eu defini como um array opcional de strings.
Já o tipo UserInputData, apenas define o objeto com os parâmetros que serão passados para a mutação createUser. Como fizemos antes, o próximo passo é criar o resolver para esta mutação, no arquivo resolvers.js:
|
1 2 3 4 5 6 7 8 9 10 11 |
createUser({ userInput }, req) { const user = { id: Math.random().toString(), name: userInput.name, email: userInput.email, logs: [] }; return user; } |
Toda função com parâmetros vai ter um primeiro argumento chamado “args”, que aqui neste exemplo eu já estou destruturando, e um segundo chamado req (request), que é útil em algumas situações. Este meu exemplo é bem bobo e não faz nada na verdade, mas imagine que aqui você colocaria o seu código de salvar o usuário no banco de dados, por exemplo, retornando-o ao final do salvamento.
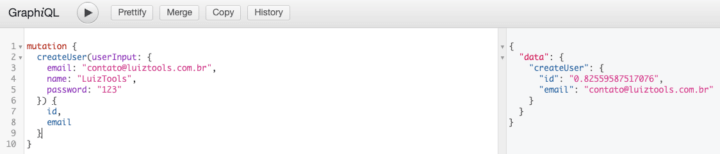
Agora, ao invés de testar no Postman, você pode testar na interface web do GraphQL, com o seguinte payload de mutation abaixo, que explico a seguir:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mutation { createUser(userInput: { name: "LuizTools", password: "123" }) { id, email } } |
Aqui usamos a keyword mutation e abrimos um objeto informando qual a mutação que queremos executar. Como a createUser espera um userInput, nos parênteses da função a gente passa o userInput como uma propriedade, recebendo um objeto com os três parâmetros esperados. Finalizada a passagem de parâmetro, abrimos chaves e informados quais os dados que queremos no retorno, sendo que aqui eu peguei apenas id e email.
O resultado você confere abaixo.
Uma última dica antes de encerrar este tutorial é você dar uma olhada na aba Docs, que fica à direita do browser, ensinando como usar as queries e mutations da sua API GraphQL, como se fosse um Swagger automático.
Até a próxima!







Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.