
Anteriormente eu escrevi um tutorial aqui no blog de como fazer upload de arquivos em Node.js, usando as bibliotecas Formidable e Multer. Se você não sabe como fazer isso ainda, esse é um pré-requisito para este tutorial, então volte lá e leia o outro tutorial!
No entanto, em aplicações web profissionais, quer elas sigam a metodologia de 12-Factor App ou não, você NÃO DEVE armazenar os arquivos carregados (que fizeram upload) na sua aplicação junto ao servidor da mesma. Ao invés disso, você deve armazenar em um serviço próprio para armazenamento de arquivos.
Alguns motivos incluem:
- o servidor da sua aplicação deve ser descartável, principalmente se estiver usando Docker, mas os arquivos carregados não são descartáveis;
- o custo de armazenamento do servidor da sua aplicação muitas vezes é maior que o custo de armazenamento de um serviço de armazenamento;
- quanto maior o tamanho do servidor da sua aplicação, mais difícil é para fazer backups e restaurações, e arquivos carregados impactam muito no tamanho;
- centralizar os arquivos carregados em um serviço de armazenamento lhe permite uma gestão melhor e mais apurada;
Entendido este ponto, se você for ter muitos arquivos carregados na sua aplicação, é hora de procurar uma solução melhor para armazená-los. Dependendo do tipo de conteúdo, periodicidade de acesso, necessidades específicas de busca, etc existem diversas soluções que podem ser usadas.
Arquivos simples de baixa criticidade, em aplicações pequenas? Que tal o Google Drive (tutorial aqui)!
Arquivos em grande quantidade mas com baixa frequência de acesso (como backups e “arquivo morto”)? Que tal o AWS Glacier?
Documentos e outros arquivos de cadastro com informações que precisam ser auditadas, consultadas, preocupação com LGPD, etc? Procure por ECMs (Enterprise Content Management) como o Alfresco.
Para os demais cenários, eu recomendo o AWS S3 (sigla para Simples Storage Service).
O S3 é um disco virtual, que a Amazon chama de bucket (balde), onde você cria e faz a gestão de diretórios e arquivos de qualquer tipo. Ele pode ser de acesso público ou privado, pode estar “atrás” de CDNs (como o AWS CloudFront) para baixar a latência de acesso, pode ser integrado com soluções Serverless, pode disparar eventos na fila da Amazon (o SQS) e muito mais.
Ou seja, ele é muito mais do que uma pasta ‘uploads’ no servidor da sua aplicação seria, e tudo isso por um preço bem baixo, baseado em centavos de dólar por GB de armazenamento e mais alguns centavos de dólar por GB de download cada vez que um arquivo é requisitado.
Você vai ver neste tutorial:
Vamos lá!

#1 – Setup do Bucket
O primeiro passo obviamente é você ter uma conta na AWS, se autenticar no seu painel e ir na área de credenciais de segurança, que ficam dentro da sua conta de usuário (o menu com o seu nome no topo).
Uma vez dentro da área de credenciais de segurança, crie chaves de acesso (caso ainda não possua), lembrando que você pode ter até duas chaves apenas e que a Amazon não fornece backup, então guarde-as em um lugar seguro.
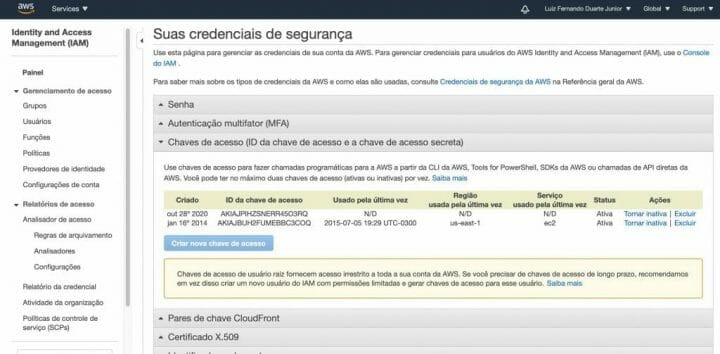
As chaves são compostas de um Access Key e de um Access Secret, sendo este último o mais “sensível” e que não deve ser compartilhado com ninguém. Usaremos estas informações mais tarde.
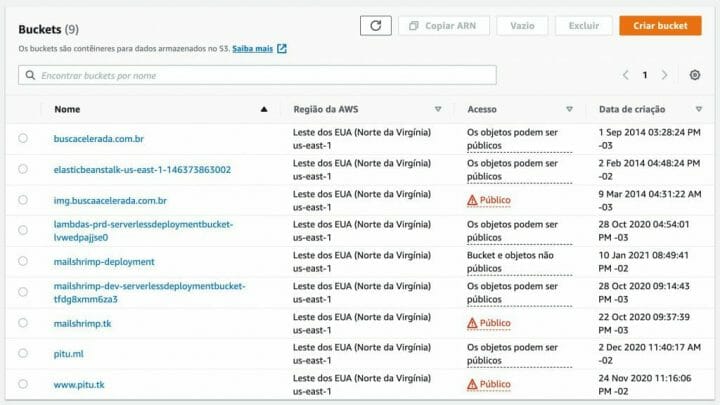
Agora vá no menu de Serviços na sua conta da AWS e procure por S3, para acessar a tela de listagem de buckets, como abaixo. Clique na opção Criar bucket em laranja.
Abrirá uma tela de configuração do bucket, onde inicialmente você tem de dar um nome ao mesmo, a região onde ele será criado (crie próximo do seu servidor de aplicação) e permissões de acesso, que geralmente o recomendado é que seja privado, a menos que esteja criando um servidor de arquivos público.
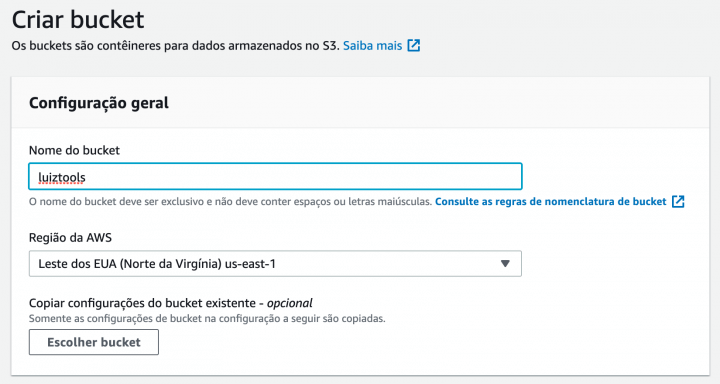
Se estiver lidando com arquivos de conteúdo sensível, você pode habilitar a opção de criptografia dos dados do disco e até do versionamento do mesmo, caso precise voltar em algum ponto do tempo. Note que essas opções consumirão mais espaço e consequentemente sua conta ficará maior no final do mês.
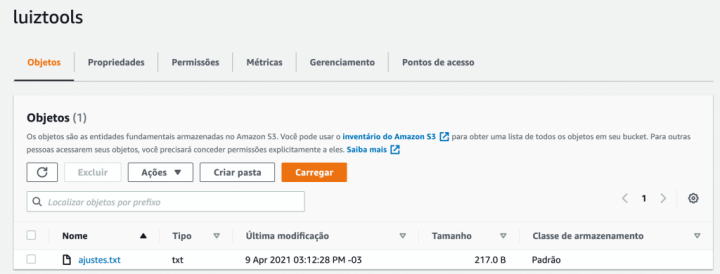
Você será direcionado para a tela de listagem de buckets novamente e clicando no nome do seu bucket você irá para uma área onde pode mudar as configurações realizadas mas, principalmente, gerenciar os arquivos de seu bucket: pode criar e excluir pastas, fazer upload e download de arquivos, etc.
Importante salientar que a exclusão de pastas ou até mesmo do próprio bucket, só podem ser feitos quando os arquivos dentro da pasta ou do bucket tiverem sido todos excluídos. Este é um mecanismo de segurança contra exclusão acidental de pastas e do bucket em si.

#2 – Setup do Projeto
Aqui vou considerar que você já tem uma aplicação web em Express funcionando e que ela já faz upload de arquivos para o servidor. Você deve ter um código parecido com este aqui, onde um arquivo é recebido via POST e salvo no servidor.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
router.post('/', (req, res, next) => { const formidable = require('formidable'); const fs = require('fs'); const form = new formidable.IncomingForm(); form.parse(req, (err, fields, files) => { const path = require('path'); const oldpath = files.filetoupload.path; const newpath = path.join(__dirname, '..', files.filetoupload.name); fs.renameSync(oldpath, newpath); res.send('File uploaded and moved!'); }); }); |
Caso não entenda nada do código acima, recomendo realizar primeiro o tutorial de upload de arquivos. Caso entenda mas não tenha o projeto acima, você pode fazer o download através do formulário ao final deste tutorial ou simplesmente adaptar os códigos a seguir.
Em seu projeto Node.js e instale nele duas dependências, o AWS SDK e o dotenv.
|
1 2 3 |
npm i aws-sdk dotenv |
O AWS SDK é a biblioteca de componentes prontos para usarmos os recursos da AWS em Node.js. Já o dotenv é um popular pacote para fazer gestão de variáveis de ambiente e configurações da sua aplicação.
Como o AWS SDK exige uma série de configurações de ambiente para funcionar adequadamente, usaremos o dotenv para fazer isto.
Agora, crie um arquivo criar arquivo .env na raiz do seu projeto, com o seguinte conteúdo.
|
1 2 3 4 5 6 |
AWS_ACCESS_KEY_ID=<SEU ACCESS KEY> AWS_SECRET_ACCESS_KEY=<SEU ACCESS SECRET> AWS_REGION=<SIGLA DA SUA REGIÃO> AWS_S3_BUCKET=<BUCKET> |
Lembra das credenciais de acesso que criamos no início do tutorial? Pois é, precisaremos delas aqui, coloque o access key e o access secret neste arquivo, nos referidos campos.
O AWS_REGION você também determinou quando criou o bucket, mas aqui deve ir somente a sigla dele. Você consegue bem fácil na sua conta, é só ver a região que está listada no topo da sua conta e usar a sigla dela na configuração do .env, será algo como us-east-1.
O nome do bucket em si também foi definido na criação e você não deve ter dificuldades em achar.

#3 – Upload no S3
Agora que temos a infraestrutura e o projeto criados e configurados, é hora de construirmos o código que enviará os arquivos do nosso servidor para o bucket no S3.
Crie um arquivo s3Client.js na raiz do seu projeto e inclua o código abaixo dentro dele, que comentarei a seguir.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
const AWS = require('aws-sdk'); const fs = require('fs'); async function uploadFile(fileName, filePath, mimeType) { const s3 = new AWS.S3({ apiVersion: '2006-03-01', region: process.env.AWS_REGION }); const fileContent = fs.readFileSync(filePath); const params = { Bucket: process.env.AWS_S3_BUCKET, Key: fileName, Body: fileContent, //ContentType: mimeType//geralmente se acha sozinho }; const data = await s3.upload(params).promise(); return data.Location; } async function listObjects(filter) { const s3 = new AWS.S3({ apiVersion: '2006-03-01', region: process.env.AWS_REGION }); const params = { Bucket: process.env.AWS_S3_BUCKET, Prefix: decodeURIComponent(filter) }; const result = await s3.listObjectsV2(params).promise(); return result.Contents.map(item => item.Key); } module.exports = { uploadFile, listObjects } |
A primeira linha é apenas um require para carregar o AWS SDK que instalamos antes e o fs, para podermos ler o arquivo do nosso servidor que queremos enviar para a Amazon.
Abaixo, temos duas funções, a primeira que é a que faz o upload para o S3, e que vou explicar melhor abaixo, e uma segunda que deixei de brinde, que é para pesquisar pastas e arquivos no seu S3.
No uploadFile, que é o nosso foco aqui, nas primeiras linhas eu instancio um objeto S3 com uma classe do pacote AWS-SDK e leio os bytes do arquivo que vou enviar para a nuvem da Amazon.
A seguir, configuro os parâmetros deste meu envio: o nome do bucket (que estou pegando do dotenv), o nome de destino do arquivo (key) e o conteúdo em bytes do mesmo (body). Opcionalmente eu posso passar o Content-Type/Mime-Type do arquivo, caso seja de algum tipo que a AWS não reconheça sozinha. Se ela não reconhecer, você sempre terá de fazer download do arquivo quando tentar acessar o mesmo, já se ela reconhecer como vídeo, por exemplo, poderá assistir o vídeo no navegador.
Note que chamei uma função .promise() ao fim do upload. Isso porque, por padrão, o upload espera um callback e se quisermos trabalhar com Promises, precisamos desta última chamada que adicionei. Também note que estou retornando apenas a propriedade Location do do data, que é a URL do seu arquivo no S3.
Após exportar nossa função no s3Client.js, vamos voltar ao código em que fazemos upload para o servidor da aplicação e vamos alterar o código para que, uma vez que o arquivo chegue no servidor, a gente envie ele para a AWS usando nosso s3Client.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
router.post('/', (req, res, next) => { const formidable = require('formidable'); const form = new formidable.IncomingForm(); form.parse(req, async (err, fields, files) => { const s3Client = require('../s3Client'); const url = await s3Client.uploadFile(files.filetoupload.name, files.filetoupload.path); res.send(`File uploaded at ${url}`); }); }); |
Aqui, modifiquei o callback da função parse do Formidable para que envie o arquivo que acabamos de fazer upload para o S3, usando nosso client. Atenção ao fato de que files é o objeto do Formidable que traz os arquivos submetidos no formulário e filetoupload é o name do campo file do meu HTML, contendo as propriedades name (nome original do arquivo) e path (caminho do arquivo já no meu servidor).
Utilizei de Async/Await para que a legibilidade fique mais simples e pego a URL retornada e imprimo na tela da aplicação.
Antes de testar nossa aplicação, você deve carregar as variáveis de ambiente, o que pode ser feita no código mas eu cada vez mais tenho preferido colocar no próprio comando de inicialização mesmo, como abaixo (package.json).
|
1 2 3 |
"start": "node -r dotenv/config ./bin/www" |
Agora suba a sua aplicação com npm start e teste o upload que deve aparecer lá no seu painel do S3, na Amazon.
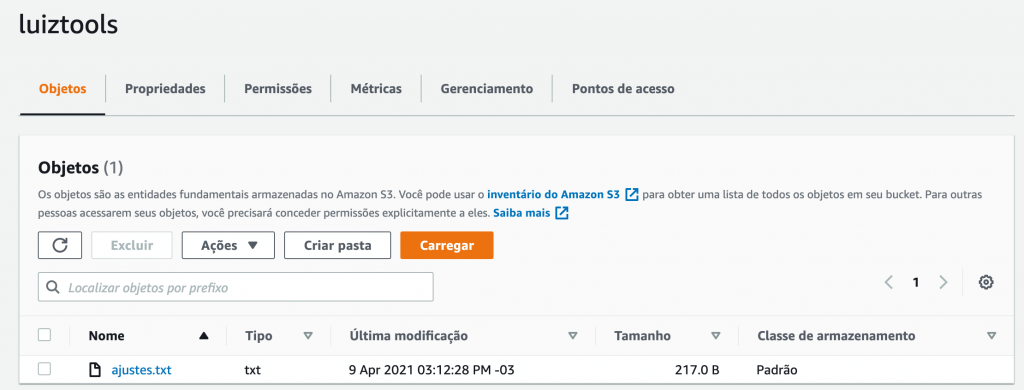
Se você tiver um erro do tipo “AccessDenied: Access Denied” quer dizer que as suas credenciais no dotenv estão erradas, inválidas ou que escreveu o nome das variáveis erroneamente. Nos dois primeiros casos, recomendo que volte ao passo inicial de setup aqui do tutorial e na área de credenciais, exclua as existentes e recrie.
Já se escreveu erroneamente o nome das variáveis de ambiente no arquivo .env, apenas refaça esta etapa aqui no tutorial. Elas são carregadas automaticamente e por causa disso precisam estar 100% iguais ao que manda a documentação da AWS, que é o que apresentei mais cedo.
Que tal um upload de arquivos para o S3 disparar uma função serverless/Lambda na AWS?
Além disso, caso você trabalhe forte o conceito de testes unitários, pode ser útil aprender a mockar as APIs da AWS em seus testes.
Deixa aí nos comentários!
Quer ver na prática como utilizar o S3 (e vários outros serviços da AWS) para, por exemplo, hospedar aplicações em ReactJS? Conheça meu curso clicando no banner abaixo!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.