
Dando continuidade à série de artigos sobre administração de instâncias MongoDB, quero falar no artigo de hoje sobre replicação ou espelhamento de instâncias, uma forma muito comum de garantir alta disponibilidade de aplicações através da redundância de databases.
Caso não tenha lido o artigo anterior, nele eu falei sobre criação de usuário e senha com diferentes perfis de acesso em instâncias de Mongo.
Claro que se você usa serviços profissionais em nuvem, geralmente mais caros, você geralmente ou não vai se preocupar com replicação (o serviço já faz automaticamente) ou vai configurar isso facilmente através de algum painel de controle.
No entanto, caso você tenha uma pequena aplicação ou mesmo não tenha grana para serviços como MongoDB Atlas, a dica de hoje pode te ajudar bastante. Caso não conheça o Atlas que acabei de citar, confira esse vídeo curtinho.
Se você não sabe nada ou muito pouco de MongoDB, sugiro não ler este artigo e procurar a minha série de MongoDB para Iniciantes em NoSQL. Ou então meu livro MongoDB para Iniciantes, já que o conteúdo deste artigo é um pouco mais avançado que o normal.
O que é uma Replica Set?
No MongoDB chamamos o popular espelhamento de replica set. Um replica set é um conjunto de processos que mantém o mesmo conjunto de dados (dataset). No MongoDB, assim como em outros bancos modernos, permite fazer este espelhamento de maneira bem simples e é um dos pilares de segurança, uma vez que derrubar um servidor de banco de dados é uma das formas de tirar uma aplicação do ar, sendo que replica sets dificultam isso.
Não obstante, replica sets muitas vezes auxiliam na velocidade de leitura (pois diferentes usuários podem estar lendo de diferentes réplicas ao mesmo tempo) e podem auxiliar na velocidade de acesso, caso você possua réplicas em diferentes áreas geográficas. Outros usos para replica sets incluem backup (você mantém uma réplica que ninguém acessa, apenas para backup near-realtime), reporting (você mantém uma réplica apenas para leitura e extração de relatórios) e disaster recovery (você chaveia para ela, em outro continente, em caso de perder o datacenter principal).
Basicamente, a arquitetura de uma replica set é constituída de um primário e os secundários. Como mostra a imagem abaixo, exemplificando o recomendado que é no mínimo 3 instâncias.
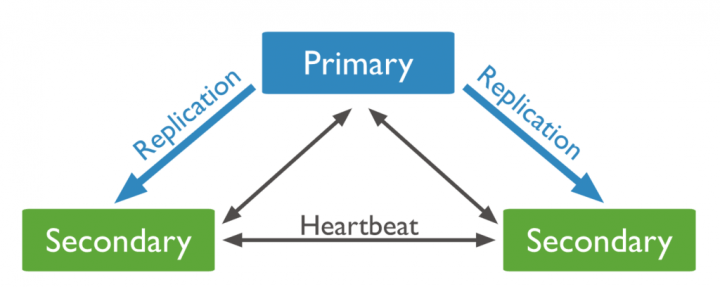
Basicamente o funcionamento é assim:
- somente o primário recebe escritas;
- todos recebem leituras;
- quando escrevem no primário, ele replica para todos os secundários;
- todos monitoram todos (heartbeat);
- se o primário cair, um secundário assume como primário e passa a receber as escritas;
Preferencialmente, todas instâncias devem possuir a mesma versão do MongoDB, para evitar problemas. Algumas funcionalidades até funcionam com duas instâncias, mas em caso de queda somente se tiver duas em pé é que uma será escolhida como primária, ou seja, permitirá escrita.
E com isso finalizamos o básico que você deve saber sobre replica sets antes de usá-las.

Criando um Replica Set
Replicar instâncias de MongoDB é muito simples, ao menos em um nível básico. Primeiro, suba com mongod uma instância de Mongo apontando os dados para uma pasta qualquer e passando o argumento replSet, como abaixo, que indica que esta instância faz parte do Replica Set “rs0”.
|
1 2 3 |
mongod --dbpath /replication/data/ -port 27018 --replSet "rs0" |
Note que mudei a porta default, pois como vou subir mais de uma instância na mesma máquina (apenas para fins de estudo) precisarei usar portas diferentes. Você vai notar também que fica dando uns erros no terminal, dizendo que o replica set ainda não foi inicializado. Pode ignorar eles por enquanto.
Agora suba outra instância de mongod apontando os dados para outra pasta (não pode ser a mesma), com outra porta mas mantendo o argumento replSet para a mesma Replica Set.
|
1 2 3 |
mongod --dbpath /replication/data2/ -port 27019 --replSet "rs0" |
Agora suba a terceira instância, para que tenhamos acesso a todas funcionalidades do replica set.
|
1 2 3 |
mongod --dbpath /replication/data3/ -port 27020 --replSet "rs0" |
O próximo passo é inicializar o Replica Set com estas três instâncias. Para fazer isso, abra outra janela de terminal e se conecte via mongosh em apenas uma das instâncias, a que será a primária, por exemplo, a primeira que subimos:
|
1 2 3 |
mongosh -port 27018 |
Uma vez conectado nesta instância, rode o comando abaixo que inicializa a Replica Set com todas as réplicas que você possui. Aqui o recomendado é que se use os DNS públicos das instâncias e não os IPs, para maior flexibilidade.
|
1 2 3 4 5 6 7 8 9 10 11 |
rs.initiate({ _id: "rs0", version: 1, members: [ { _id: 0, host : "localhost:27018" }, { _id: 1, host : "localhost:27019" }, { _id: 2, host : "localhost:27020" } ] }) |
Com isso, o Replica Set começará a funcionar depois de alguns segundos, sendo que vai notar pelas mensagens no terminal deles de que estão sincronizando dados (principalmente se um deles tinha dados e o outro não). O primary deve ser definido por eleição entre as réplicas, automaticamente. Se você quiser definir isso manualmente, adicione uma propriedade priority ao objeto member com um valor de 0 a 1000 (maior é melhor).
Se quiser adicionar outra replica mais tarde, pode se conectar no primário e usar o comando abaixo após já estar com a instância rodando como mostrei anteriormente (com replSet definido). No exemplo abaixo, eu subi ela em localhost na porta 27021.
|
1 2 3 |
rs.add({_id: 3, host: "localhost:27021"}) |
Por padrão, os secundários servem apenas como backup, ou seja, não podem ser acessados para leitura. Se quiser liberar a leitura em um secundário (lembrando que pode haver diferença mínima nos dados pois a replicação não é instantânea), use o comando abaixo na sessão do secundário:
|
1 2 3 |
db.getMongo().setReadPref("primaryPreferred") |
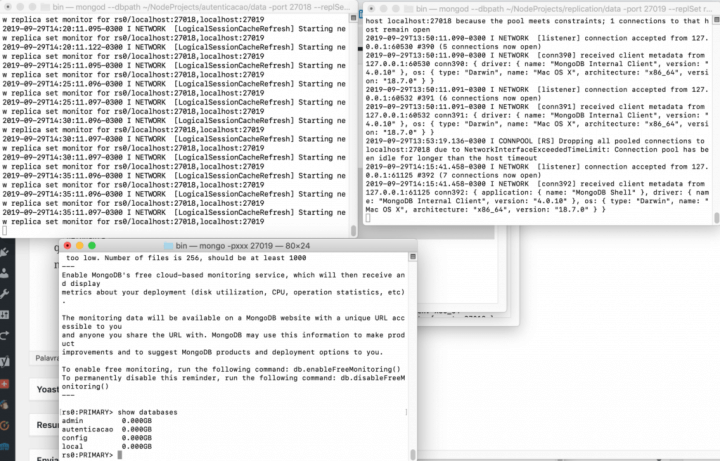
Já escrita é só no primário mesmo, não tem o que fazer. Agora se você se conectar a qualquer uma das instâncias da replica set notará que o console informa se você está no primário ou em um dos secundários, como mostra na imagem abaixo.
Uma coisa bacana é que, se você já tiver dados em uma das instâncias quando criar a Replica Set, eles automaticamente serão replicados assim que o Replica Set for inicializado, ou seja, pode ser uma estratégia de backup bem interessante subir de vez em quando um Replica Set para espelhar seu banco.
No mais, todo dado que você adicionar no primário, a partir do momento que criou a Replica Set, serão replicados para TODOS secundários assim que possível (geralmente em poucos segundos, dependendo do volume e distância geográfica).
Caso o primário caia, uma nova eleição será feita entre os secundários e um deles vai assumir. Por isso a importância de fazer Replica Sets com no mínimo 3 membros, embora funcione com 2, como fiz no exemplo.

Usando um Replica Set
E ao usar via aplicação, o que muda? Se você se conectar diretamente ao primário (para leitura e escrita) ou a um secundário (para leitura somente), nada vai mudar e os dados apenas estarão sendo replicados em background. Claro, se cair a instância que você está conectado, não vai adiantar estar replicado pois sua aplicação não conhece o Replica Set, mas apenas uma instância específica.
Agora, se você quer realmente aproveitar todos benefícios desta abordagem, o recomendado é se conectar informando o Replica Set, mudando sua connection string para algo similar ao abaixo:
|
1 2 3 |
mongodb://localhost:27018,localhost:27019/?replicaSet=rs0 |
Caso tenha usuário e senha, adicione-os à frente da primeira instância como faria normalmente e adicione mais um parâmetro no final da URL para informar o banco de autenticação, como abaixo:
|
1 2 3 |
mongodb://user:password@localhost:27018,localhost:27019/?replicaSet=rs0&authenticationDatabase=myDb |
Não é necessário listar todos os servidores da Replica Set na connection string, pois ao se conectar a um deles (o mais próximo e disponível) e ele informar que está na replicaSet informada na connection string, o client vai receber a informação de TODOS os demais membros da Replica Set, mesmo que alguns não estejam listados na connection string.
Isso porque a adição e remoção de membros do Replica Set acontece de maneira independente à aplicações que a usam, certo?
Ainda assim é recomendado informar mais de um membro na connection string pois pode ser que alguns membros estejam down no momento da conexão, aí o client vai tentar conectar no próximo.
Segurança em Replica Sets
Caso você esteja usando autenticação nos membros da sua Replica Set, e eu sugiro que o faça, é sempre mais fácil rodar as instâncias sem autenticação como eu fiz para fazer as configurações, no entanto, quando for colocar em produção vai precisar dela novamente. No entanto, depois de tudo configurado, se você rodar as instâncias com –auth, vai receber o erro de “unauthorized replSetHeartbeat …”.
O processo de heartbeat entre os membros do Replica Set exige que eles confiem uns nos outros. Uma forma bem comum de fazer isso é através de keyfiles. Para criar um keyfile, use os comandos abaixo no terminal:
|
1 2 3 4 |
openssl rand -base64 756 > caminho-pasta/key chmod 400 caminho-pasta/key |
Troque caminho-pasta para um caminho na pasta da sua instância de Mongo, deixe o key como está e copie o mesmo arquivo para as demais instâncias da Replica Set.
Agora quando for executar as suas instâncias, inclua o argumento –keyFile, como no exemplo abaixo, além do argumento –auth, é claro.
|
1 2 3 |
mongod --dbpath /replication/data2/ -port 27019 --replSet "rs0" --keyFile caminho-pasta/key --auth |
Com isso, as instâncias confiarão umas nas outras para replicação, uma vez que possuem a mesma chave e você terá um Replica Set seguro.
Com isso eu encerro mais este artigo sobre administração de MongoDB. Deixe nos comentários o que achou deste artigo!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.
[…] Administrando MongoDB: Replicação/Espelhamento […]
Gostei muito da explicação, estou atras de informações para levar o MONGO para o Kubernet vc teria algum material ?
Infelizmente não entendo nada de Kubernetes, Dockers e afins.