

Recentemente, atendendo a inúmeros pedidos ao longo dos anos, eu escrevi um tutorial de Git e GitHub para iniciantes no assunto, já que é um requisito onipresente nas vagas de desenvolvimento tem alguns anos. Na primeira parte do tutorial, que você confere aqui, eu falei o que é, para que serve, preparamos o ambiente, criamos e clonamos o repositório e fizemos as primeiras alterações, stagings e commit, terminando com um push para a main. Podemos dizer que passamos por um ciclo completo. Não um ciclo profissional, mas completo.
Por que falo isso? Porque via de regra, em projetos profissionais, como aqueles que você vai vir a trabalhar em empresas, você não vai trabalhar na branch main e muito menos ficar commitando e fazendo push nela, não é assim que funciona já que a main é um espelho de produção e muitas vezes o commit nela dispara fluxos de CI/CD que colocam a nova versão online.
Então nessa lição nós vamos entrar mais a fundo em algumas práticas mais profissionais com Git e GitHub. Se preferir, você pode acompanhar pelo vídeo abaixo, tem o mesmo conteúdo.
Vamos lá!
#1 – Navegando pelos Commits
Uma vez que você tenha “pushado” seu primeiro commit, vale dar uma olhada na página do repositório no GitHub para ver o que houve.
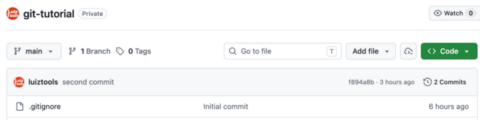
Você vai notar na faixa cinza logo acima dos arquivos a mensagem do commit mais recente (“second commit”), o identificador do mesmo, há quanto tempo ele foi feito e a quantidade total de commits no projeto. Se você clicar na mensagem do commit, você vai para página com detalhes do mesmo, onde poderá ver os arquivos adicionados e alterados, com as adições em verde, remoções em vermelho e demais alterações em amarelo.
Agora se você clicar no número de commits, verá algo ainda mais interessante: a lista completa de commits do projeto.
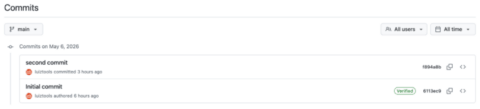
Com essa lista você consegue ver as mensagens de commit, alterações feitas em cada momento do tempo, ver como estava o repositório naquele instante (Browse Repository) ou até mesmo voltar no tempo. Sim, se você precisar, por qualquer motivo, recuperar uma versão anterior do projeto, você pode usar o comando abaixo para fazê-lo, bastando ter o id do commit que você pode pegar na direita da listagem de commits.
|
1 2 3 |
git checkout <id_commit> |
Esse comando vai restaurar na pasta do projeto a versão em específico que você forneceu, permitindo que você use ele, faça novas modificações a partir dela e muito mais. Apenas atenção ao fato de que você está trabalhando no passado, então se for fazer alterações, não é tão simples assim de juntar elas com a versão principal depois, o mais recomendado nesse caso é criar novas branches, o que vamos ver a seguir.

#2 – Branching e Merging
Uma das vantagens de se trabalhar com um ferramenta de controle de versão é a possibilidade de se duas ou mais pessoas trabalharem em paralelo no mesmo projeto. No entanto, quando Alice está trabalhando em uma feature A e Bob na feature B, as alterações de um podem acabar afetando o trabalho do outro, certo? Claro, com cada um trabalhando na sua máquina, este problema só vai aparecer quando forem juntar as alterações. Quando isso acontecer, eles precisam fazer o que chamamos de merge (fusão), mas já vamos chegar lá.
O problema aqui é que tanto Alice quanto Bob não deveriam estar trabalhando diretamente no espelho de produção, ou seja, na versão main. Isso porque enquanto eles tocam novas funcionalidades, pode ser que surja uma demanda urgente a ser resolvida na versão de produção, o que vai exigir um novo código e um novo deploy. Se eles ficarem mexendo na versão de produção, ela seria comprometida e possivelmente desestabilizada, algo que jamais pode acontecer. Neste caso, sempre que Alice e Bob forem incluir novas funcionalidades, eles devem primeiro criar uma nova branch da main.
Uma branch (ou ramificação) é uma cópia do projeto com vida própria, como se fosse uma nova linha do tempo a partir de um ponto qualquer, geralmente o mais recente. Cada desenvolvedor pode criar a sua própria branch e trabalhar nela independente dos demais, inclusive fazendo commits nesta branch. Mais pra frente, quando o seu trabalho tiver terminado, ele pode fazer o merge dela com outra existente, como a main por exemplo, a fim de juntar no histórico principal. A imagem abaixo ilustra isso.
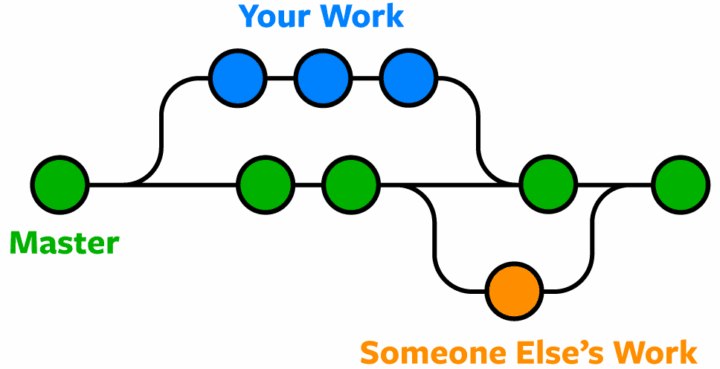
Neste exemplo, temos a branch master (antigo nome da main) em verde, simbolizando a versão principal do projeto. Em determinado momento o dev azul criou uma branch a partir do primeiro commit da main (bolinha verde) para trabalhar em novos recursos, juntando seu trabalho à branch principal três commits mais à frente (bolinha verde de número 4). Note que ele próprio teve três commits também, sendo o primeiro de criação da branch e os demais de alterações que ele fez, mas tudo na sua branch alternativa. Durante esse período, um dev laranja também abriu outra branch no commit 3 da main, que viria a se fundir com ela novamente mais recentemente, ao final do grafo.
Via de regra, o Git é naturalmente inteligente para fazer o merge das alterações do dev azul à main e do dev laranja à main. Logo, o merge das alterações costuma ser automático e todo o histórico é mantido. Isso claro, desde que não existam conflitos. Quando alterações do dev azul e do laranja entram em conflito, já que o laranja só começou a trabalhar antes do azul mergear as alterações dele, é necessário fazer uma análise, de preferência com alguma ferramenta visual, e entender o código que fica, o código que sai ou fazer um meio-termo. Isso é o merge, que entraremos em detalhes mais à frente. Por ora, esse entendimento inicial já é o suficiente e vamos aprender agora como criar branches.

#3 – Usando branches
O primeiro passo para começarmos a usar branches, depois de entender o conceito (explicado anteriormente), é descobrir quais branches existem atualmente no projeto, o que pode ser feito com o comando abaixo.
|
1 2 3 |
git branch |
Isso vai listar os nomes delas, um abaixo do outro, sendo que é esperado que liste somente “main” neste momento. Um asterisco ao lado do nome indica que ela é a branch atualmente selecionada na sua máquina.
Agora imagine que você vai iniciar o desenvolvimento de uma nova funcionalidade. O primeiro passo é criar uma nova branch, certo? Você faz isso com o comando abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 |
git branch nome_branch //ou git switch -c nome_branch //ou git checkout -b nome_branch |
Qualquer um dos três comandos cria uma nova linha do tempo a partir do último commit da branch atualmente selecionado, e você pode confirmar isso com o comando “git branch”. No entanto, o primeiro comando apenas cria mas não a disponibiliza para trabalharmos. Para realmente começarmos a fazer alterações independentes da main, em nossa nova branch, precisamos selecionar ela, com um dos comandos abaixo.
|
1 2 3 4 5 6 7 |
git switch nome_branch //ou git checkout nome_branch |
Agora se você fizer novamente o comando para listar branches, vai ver as mesmas branches lá, mas a sinalização de branch selecionada vai estar ao lado da nova que você criou. A partir de então, todas alterações que você fizer e commitar, estarão pertencendo única e exclusivamente à branch nova e não à main. Experimente fazer alterações e rodar novamente os comandos para salvá-las.
|
1 2 3 4 5 6 7 8 9 |
//faça alterações no projeto git add . git commit -m "explique alterações" //ou os dois juntos com: git commit -am "explique alterações" |
Agora se você rodar o comando para ver os commits (abaixo), você verá que na sua nova branch (a minha se chama nova_pagina) tem um commit a mais.
|
1 2 3 |
git log --oneline |

A sinalização “HEAD” indica qual o commit mais atual para aquela branch apontada. Note então que tenho um HEAD para a nova_pagina (minha nova branch) e outro para a main, que é a branch origin (de onde a minha ramificação partiu).
Opcionalmente, você pode fazer push desse commit para o repositório remoto no GitHub, a fim de não manter suas alterações apenas localmente. Note que isso não é o mesmo que fazer um merge, é apenas um update de uma branch sua, substituindo uma versão antiga dela.
|
1 2 3 |
git push --set-upstream origin <nome_branch> |
A flag –set-upstream é necessária para dizer para onde enviar seu push, neste caso para a origin da branch que você vai passar o nome ao final do comando. Caso contrário, o Git poderia pensar que é pra mandar pra main, mas como ele não faria isso implicitamente uma vez que sua branch selecionada é outra, ele daria um erro.
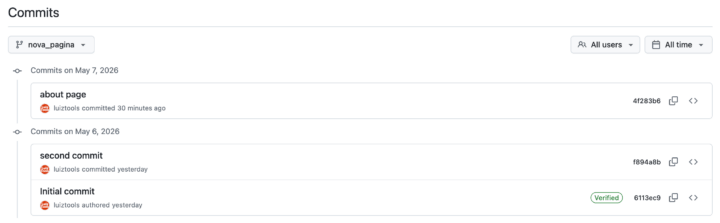
Uma vez com o commit salvo online, você pode vê-lo na página do repositório no GitHub, mas somente se você selecionar a branch correta no select à esquerda. Se você olhar na lista de commits da main, este novo commit não existirá nela.
A seguir, veremos como juntar branches (merge).

#4 – Fazendo Merges
Em determinado momento você vai terminar o trabalho que estava fazendo na nova branch, certo? Quando isso acontecer, se você quiser que tudo que você fez passe a fazer parte da versão principal do projeto, você vai ter de fazer a fusão (merge) da sua branch com a main. Antes disso, eu recomendo sempre que você pegue do repositório online as últimas alterações da sua branch que talvez você não tenha. Isso pode ser devido a outro colega trabalhando na mesma branch ou porque você fez alterações usando máquinas diferentes. Independente do motivo, o comando para baixar atualizações da sua branch é bem simples, como abaixo.
|
1 2 3 |
git pull |
Agora para fazer o merge entre duas branches, o primeiro passo é trocar a branch selecionada para a de destino (a “verdade”), neste caso a main (quero trazer as alterações da outra branch para a main do projeto).
|
1 2 3 4 5 6 7 |
git checkout main //ou git switch main |
Com a branch de destino selecionada, você vai usar o comando abaixo para puxar as alterações da nova branch por cima da branch atualmente selecionada (main).
|
1 2 3 |
git merge <nome_branch> |
Se não houverem conflitos, o próprio Git vai juntar os arquivos alterados, adicionados, removidos, etc como exibido abaixo, onde um novo arquivo foi adicionado, com 97 linhas.

Note que o merge é local, então se quiser que a nova versão “mergeada” vá para o repositório online, faça push novamente.
Caso não queira mais usar a branch nova após o merge, você pode exclui-la com o comando abaixo.
|
1 2 3 |
git branch -d nome_branch |
Opcionalmente, se quiser fazer um force delete de uma branch, use “-D”.
Mas isso que fizemos é o cenário de merge mais feliz possível, certo? Quando a main está lá, paradinha, enquanto você desenvolve em outra branch e depois as alterações deságuam nela. No entanto, em um ambiente tradicional de trabalho nem sempre é assim.

#5 – Resolvendo Conflitos
Em um segundo teste, imagine o seguinte cenário: nova branch criada, alteração realizada em arquivo A. Git add, commit e push. Ok, alterações na branch estão online.
Agora volte para a branch main, altere algo em outro arquivo B. Git add, commit. Agora tente fazer o merge novamente a partir da main, trazendo as alterações da outra branch. Você vai ver que vai se abrir uma janela pedindo uma mensagem de commit para este merge. Sim, neste caso em que temos duas linhas do tempo que terminam em pontos diferentes, precisaremos fazer um merge commit. Deixe uma mensagem na primeira linha (# são usados para comentários) ou use a mensagem default e confirme o salvamento. Depois faça o push para enviar tudo para o GitHub.
Com isso, agora nós teremos na main um novo commit específico para o merge. Veja abaixo como diferente do merge anterior, não trouxemos os commits da branch nova para a main, mas sim temos um merge commit específico com a fusão de tudo após o último commit que tínhamos feito na main, isso porque usamos ela como base para o merge (a “verdade”).
Mas este ainda é um cenário feliz, afinal, cada branch teve apenas alterações em arquivos diferentes. Mas o que acontece quando dois ou mais devs fazem alterações nos mesmos arquivos?
O último cenário que precisamos exercitar é o de merge com conflitos. Mas antes de fazer uma alteração que necessite de resolução manual de conflitos, é interessante configurar o editor padrão do Git para estas situações. Na situação anterior, precisamos apenas deixar uma mensagem e provavelmente você teve de fazê-lo via terminal, certo? No entanto resolver conflitos de código via terminal não é uma boa ideia, então recomendo mudar para que o editor padrão do Git seja o VS Code, o que você pode fazer com o comando abaixo.
|
1 2 3 |
git config --global core.editor "code --wait" |
Caso prefira outro editor, basta ajudar o comando final de acordo.
Agora troque de branch ou crie uma nova, faça alterações no index.html. Git add, commit e push nessa nova branch.
Depois, volte pra main e faça alterações no mesmo index.html, no mesmo trecho de antes (para gerar o conflito), mas com valores diferentes. Git add, commit.
Quando você for fazer o git merge, notará que o terminal vai avisar que o merge automático falhou e que você vai precisar fazer merge manual na ferramenta escolhida anteriormente, o VS Code no meu caso.
Indo para o VS Code, vai se abrir o código apresentando as duas versões misturadas e algumas opções:
- Accept Current Changes: aqui você prioriza a sua versão local e descarta a da outra branch;
- Accept Incoming Changes: aqui você prioriza a versão da branch e descarta a sua local;
- Accept Both: aqui o Git vai juntar as duas, em linhas diferentes;
- Compare Changes: aqui abre outra janela, dividida ao meio, para comparar os dois arquivos;
O que você tem de fazer é comparar as possibilidades e tomar a melhor decisão para o cenário, que vai variar caso a caso. Quando tiver decidido, clique na opção correspondente e salve o arquivo. Depois faça staging das alterações, commit e push.
Conflito resolvido!
E com isso terminamos mais um capítulo da nossa saga de Git e GitHub para iniciantes.
Até a próxima!







Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.