

Outro dia eu escrevi um tutorial aqui no site sobre o LangChain, um canivete-suíço quando o assunto é criar aplicações que usam IA. Você pode ver este primeiro tutorial aqui, aliás, o que eu super recomendo para entender o básico sobre este popular framework. Hoje, eu quero te ensinar como usar ele para criar aplicações RAG ou Retrieval-Augmented Generation, uma técnica muito boa para expandir o conhecimento dos LLMs de mercado com dados específicos da sua empresa, sistema, etc.
Se preferir, você pode assistir ao vídeo abaixo, o conteúdo é o mesmo.
Vamos lá!
#1 – O que é RAG?
Uma das maiores deficiências dos modelos de IA generativa (LLM) que usamos atualmente, como o ChatGPT, é a suas alucinações quando lhes faltam informações precisas sobre determinado assunto. Isso costuma acontecer com mais frequência quando ele simplesmente desconhece o assunto por ser uma informação privada (não está disponível publicamente na Internet) ou muito recente, já que os treinamentos pelos quais estes modelos passam acabam gerando “linhas de corte” no conhecimento que aquele modelo possui. Uma das técnicas para resolver essa deficiência se chama RAG.
O Retrieval-Augmented Generation ou Geração Aumentada por Retorno, é uma técnica onde um modelo retorna informações externas e então as usa para gerar respostas melhores e mais precisas. Ao invés do modelo usar apenas seu treinamento prévio, ele usa de documentos, bases de dados ou o que mais você fornecer a ele como “treinamento extra” para aquela pergunta em questão.
Obviamente nem tudo são flores e usar RAG em seus sistemas traz complexidades adicionais como a vetorização dos dados, que aliás precisam ter boa qualidade para serem úteis, e a construção de uma aplicação específica para retorná-los. Além disso, como é uma etapa extra no uso da LLM, isso tende a tornar suas respostas como um todo mais lentas. Sendo assim, vale sempre a pena fazer uma prova de conceito e avaliar se tem bom fit com a sua necessidade. Pensando nisso, abaixo eu proponho um exemplo de RAG simples para você ter um primeiro contato e entender melhor como funciona na prática.

#2 – Setup do Projeto
Se você já programa Node.js ou ao menos fez o tutorial anterior de LangChain você já possui todo o ambiente preparado na sua máquina e tem uma chave de API da OpenAI, certo? Você pode fazer RAG com todos os principais modelos de mercado, mas como já usei OpenAI em outros tutoriais aqui do site e do canal, vou seguir com ela.
Vamos começar nosso exemplo criando o seu projeto Node.js com os comandos abaixo, um de cada vez.
|
1 2 3 4 5 6 |
mkdir langchain-rag cd langchain-rag npm init -y npm install dotenv @langchain/classic @langchain/core @langchain/openai @langchain/textsplitters langchain pdf-parse@1.1.1 |
As extensões que instalamos no último comando foram:
- DotEnv: para configurações do projeto;
- LangChain: o framework LangChain;
- @LangChain/OpenAI: SDK de integração com as APIs da OpenAI;
- @LangChain/Core: lib necessária para o SDK acima funcionar;
- @LangChain/Classic: lib que possui o VectorStore que vamos usar;
- @LangChain/TextSplitters: lib para ajudar no parsing dos dados;
- pdf-parse: lib para leitura de PDF (a fonte de dados que vou usar, repare na versão do pacote);
Agora abra o projeto no VS Code e crie um arquivo .env na raiz do projeto com as variáveis que vamos usar, principalmente a sua chave da OpenAI e lembre-se de não subir esse .env para seu GitHub se for versionar o projeto.
|
1 2 3 4 |
# .env OPENAI_API_KEY=xxxxxxx |
Agora vá no seu package.json e mude o type para module, a fim de podermos usar a sintaxe de ESModules no projeto.
|
1 2 3 |
"type": "module", |
Também crie um index.js e coloque nele o carregamento do .env.
|
1 2 3 4 |
//index.js import "dotenv/config"; |
Na raiz do seu projeto, coloque um arquivo de texto em formato PDF, com o nome file.pdf. Pode ser qualquer coisa, desde que possua texto em seu interior (não pode ser aqueles PDFs escaneados, só com imagens).
Agora sim, temos tudo pronto para programar nosso exemplo.

#3 – Preparando os Dados
O nosso primeiro passo quando vamos criar uma solução RAG é o carregamento e vetorização dos dados. Isso porque LLMs não fazem busca textual literalmente falando. Todos os dados acessados por elas estão matematicamente dispostos em uma base vetorial gigantesca para que a busca e geração da resposta seja rápida e eficiente, baseada em similaridade probabilística. E é justamente isso que temos de fazer com nosso documento: vetorizá-lo, transformado todos os tokens (palavras, símbolos, etc) em coordenadas vetoriais.
Para fazer isso, vamos começar importando tudo que vamos usar neste projeto em nosso index.js, sem se importar com os objetos importados, que serão explicados em seu devido tempo. Dependendo do seu grau de experiência com Node.js você pode já conhecer alguns deles ou deduzir para que servem.
|
1 2 3 4 5 6 7 8 |
import fs from "fs"; import readline from "node:readline/promises"; import pdf from "pdf-parse"; import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai"; import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters"; import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory"; |
Agora vamos criar uma função que carrega o arquivo PDF que será nossa fonte externa de dados a ser vetorizada.
|
1 2 3 4 5 6 7 |
async function loadPdfText(pdfPath) { const pdfBuffer = fs.readFileSync(pdfPath); const parsed = await pdf(pdfBuffer); return parsed.text || ""; } |
O resultado é o texto lido do arquivo inteiro, sem qualquer modificação.
Agora vamos carregar o documento com a função acima e quebrar o texto em chunks, que são blocos de informação que serão usados mais tarde para embasar as respostas do LLM. Isso é necessário para que não tenhamos de adicionar o documento inteiro no contexto da pergunta ao LLM, mas sim apenas o bloco mais relevante para ele ter a informação que precisa dada a pergunta que foi realizada.
|
1 2 3 4 5 6 7 8 9 |
const PDF_PATH = "file.pdf"; const CHUNK_SIZE = 1200; const CHUNK_OVERLAP = 200; const pdfText = await loadPdfText(PDF_PATH); const splitter = new RecursiveCharacterTextSplitter({ chunkSize: CHUNK_SIZE, chunkOverlap: CHUNK_OVERLAP }); const chunks = await splitter.splitText(pdfText); |
A constant CHUNK_SIZE serve para definir o tamanho do chunk em caracteres, enquanto que a CHUNK_OVERLAP define a sobreposição entre os chunks. Isso porque uma frase pode acabar sendo cortada antes do fim devido ao CHUNK_SIZE, perdendo informação importante, então o CHUNK_OVERLAP funciona como uma margem de tolerância antes e depois dos chunks.
Essas duas informações são usadas no objeto RecursiveCharacterTextSplitter do LangChain, que faz o split do texto em chunks seguindo as nossas regras.
Agora é a hora de vetorizar as informações dos nossos chunks, o que vamos fazer com Embeddings, uma espécie de agrupamento de tokens por similaridade, usando funções matemáticas complexas que felizmente o LangChain nos fornece funções prontas para lidar. Como vou utilizar os modelos da OpenAI, usarei a classe OpenAIEmbeddings para fazer este trabalho pra gente, com o modelo text-embedding-3-small, ideal para análises rápidas e baratas do nosso RAG.
|
1 2 3 4 5 6 7 8 9 10 11 |
const embeddings = new OpenAIEmbeddings({ model: "text-embedding-3-small", openAIApiKey: process.env.OPENAI_API_KEY }); const TOP_K = 4; const vectorStore = await MemoryVectorStore.fromTexts(chunks, chunks.map(() => ({})), embeddings); const retriever = vectorStore.asRetriever(TOP_K); |
Esse modelo de embedding (não confundir com o modelo GPT da resposta) é usado para gerar os dados vetorizados a partir dos chunks, o que faremos com a classe MemoryVectorStore que servirá também armazenar os dados vetorizados, funcionando como um banco in-memory para os retornos do RAG. Existem soluções mais poderosas que essa no mercado, como o famoso ChromaDB, mas não é tão simples de usar quanto o MemoryVectorStore para pequenas fontes de dados como essa.
Aquela constante TOP_K define a quantidade de chunks mais relevantes do nosso documento que serão usados para “aumentar” (o A do RAG) o contexto da LLM que irá gerar a resposta à pergunta. Assim, quando fizermos uma pergunta, passaremos ela primeiro no RAG, pegaremos os 4 chunks mais relevantes e entregaremos a pergunta original e os 4 chunks para o LLM usar como contexto para a resposta. Mas falaremos melhor disso a seguir, por ora, apenas retornamos o vectorStore como um objeto retriever.

#4 – Configurando o Modelo
Agora que temos os dados vetorizados e prontos para uso via RAG, vamos codificar a junção deles com o nosso modelo. Aqui eu inicializo um objeto ChatOpenAI com o modelo de LLM que usaremos para responder às perguntas, a temperatura em zero para ele se ater ao contexto e não inventar muito e a chave de API.
|
1 2 3 4 5 6 7 8 9 10 |
const model = new ChatOpenAI({ model: "gpt-4.1-mini", temperature: 0, openAIApiKey: process.env.OPENAI_API_KEY }); console.log("PDF carregado e indexado. Digite sua pergunta (ou 'sair' para encerrar).\n"); const rl = readline.createInterface({ input: process.stdin, output: process.stdout }); |
Esse modelo será usado mais adiante e termina todo o setup geral, se você subir agora a aplicação, ela vai exibir alguns warnings de carregamento do PDF e encerrar após imprimir a mensagem. O que precisamos fazer agora é criar um mecanismo para que o terminal fique aguardando perguntas do usuário, que serão respondidas usando RAG + LLM, o que faremos usando aquele readline que inicializei na última linha do bloco.
A seguir, vamos criar um loop infinito onde ficaremos aguardando perguntas do usuário até ele querer sair encerrando a aplicação. A cada pergunta, vamos chamar uma função answerQuestion (a ser criada) passando a pergunta, o retriever e o modelo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
try { while (true) { const question = (await rl.question("Pergunta> ")).trim(); if (!question) { continue; } const normalized = question.toLowerCase(); if (normalized === "sair" || normalized === "exit" || normalized === "quit") { break; } await answerQuestion(question, retriever, model); console.log("\n---\n"); } } finally { rl.close(); } |
Agora vamos fazer a função answerQuestion. Antes de fazer ela diretamente, precisamos criar uma função buildContext para pesquisar os chunks mais relevantes do documento baseado na pergunta que o usuário fez e devolver eles, usando o retriever. O resultado desta função é uma string com os trechos mais relevantes do documento para a pergunta realizada.
|
1 2 3 4 5 6 7 8 9 |
async function buildContext(question, retriever) { const docs = await retriever.invoke(question); return docs .map((doc, i) => `[Trecho ${i + 1}]\n${doc.pageContent}`) .join("\n\n"); } |
Agora vamos fazer a função answerQuestion, que usa a buildContext. Após ela construir o contexto com base na informação retornada do documento, nós usamos o modelo passando uma instrução adicional para ele ser bem objetivo e a pergunta do usuário, assim como fizemos no tutorial passado, de GPT. Lembre-se: o modelo somente conhece aquilo que enviamos pra ele + seu treinamento prévio, não há estado sendo armazenado entre as perguntas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
async function answerQuestion(question, retriever, model) { const context = await buildContext(question, retriever); const response = await model.invoke([ { role: "system", content: "Voce eh um assistente de RAG. Responda apenas com base no contexto recuperado. Se nao houver informacao suficiente, diga claramente que nao encontrou no PDF." }, { role: "user", content: `Pergunta: ${question}\n\nContexto recuperado do PDF:\n${context}` } ]); console.log("Pergunta:", question); console.log("\nResposta:\n", response.content); } |
O resultado é um terminal que responde perguntas usando seu PDF como fonte máxima de informação, como abaixo, onde eu testei usando um PDF de 1300 páginas de um processo trabalhista.
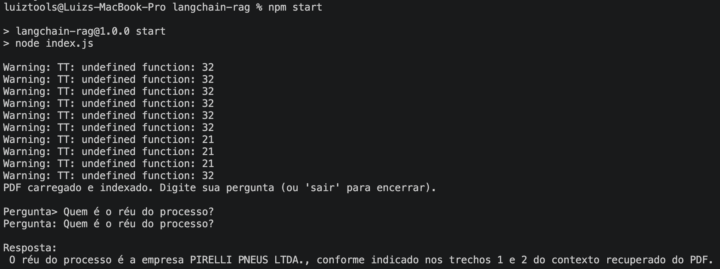
Você pode fazer quantas perguntas você quiser sobre os dados do documento sem ter de recarregar o mesmo. Como ele fica armazenado em um vector store na memória, ele somente vai refazer o demorado processo de vetorização dos dados se você reiniciar a aplicação.
Até a próxima!





Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.