

Todas as vezes que comecei a aprender uma nova linguagem de programação, logo depois de escrever o primeiro Olá Mundo, eu inicio um projeto de CRUD. CRUD é uma abreviação para Create, Retrieve, Update e Delete, ou seja, as 4 operações elementares em um sistema de cadastro. E com Solana não foi diferente, ajudando a descobrir diversas coisas fundamentais desta tecnologia. Neste tutorial de hoje eu vou lhe ensinar como criar um programa CRUD de livros para blockchain Solana, usando o framework Anchor, utilizando Rust no programa e TypeScript nos testes.
Este não deve ser o seu primeiro contato com Anchor ou com Solana, para isso recomendo que tenha feito este tutorial antes.
Vamos lá!
#1 – Criando o Projeto
Para criar esse projeto você vai precisar ter Node.js e o Rust instalados na sua máquina. Caso precise de ajuda, falo sobre a instalação completa do ambiente neste artigo. Rode o comando abaixo para inicializar seu projeto com o nome “crud-solana” e compilá-lo uma primeira vez (rodando os testes na sequência).
|
1 2 3 4 5 6 |
anchor init crud-solana cd crud-solana anchor build anchor test |
Com os comandos acima executados com sucesso quer dizer que nosso projeto inicial está criado e podemos trabalhar na customização dele agora. Na pasta programs, vamos trabalhar no lib.rs para fazer nosso CRUD de livros, enquanto que na pasta tests temos o crud-solana.ts para os unit tests do CRUD.
No lib.rs vamos começar definindo o elemento mais fundamental do nosso programa: um livro.
|
1 2 3 4 5 6 7 8 9 |
#[derive(AnchorSerialize, AnchorDeserialize, Clone)] pub struct Book { pub id: u32, pub title: String, pub author: String, pub year: u16, } |
Aqui eu defini um livro como sendo uma estrutura (struct) serializável (macros AnchorSerialize e AnchorDeserialize) com id (unsigned integer de 32-bit), título (String), autor (String) e ano de lançamento (unsigned integer de 16-bits). Se somarmos o espaço necessário para cada campo estamos falando de 4 + 32 + 32 + 2 bytes ou 70 bytes por livro, sendo que considerei 32 bytes por String (mas poderia ser maior). Guarde este número, usaremos ele logo mais.
Os livros serão guardados dentro de uma account que terá um vector (“array dinâmico”) e um contador que usaremos mais tarde para gerar ids autoincrementais para os livros, como aconteceria em um banco de dados. Abaixo a struct da nossa account Library.
|
1 2 3 4 5 6 7 |
#[account] pub struct Library { pub books: Vec<Book>, pub next_id: u32, } |
Também vamos precisar de um erro personalizado, para lançarmos quando não encontrarmos um livro que o usuário tentou manipular. Para isso definimos um enum de CustomError que hoje terá apenas um BookNotFound, mas que no futuro pode ter outros erros.
|
1 2 3 4 5 6 7 |
#[error_code] pub enum CustomError { #[msg("Book not found")] BookNotFound, } |
E por fim, para finalizar, vou criar uma última struct bem parecida com a primeira, que chamarei de BookData.
|
1 2 3 4 5 6 7 8 |
#[derive(AnchorSerialize, AnchorDeserialize, Clone)] pub struct BookData { pub title: String, pub author: String, pub year: u16, } |
Essa struct servirá apenas para tipar os parâmetros de algumas funções. Até poderíamos usar a struct Book, mas isso implicaria em passar inclusive o id do livro, coisa que nem sempre queremos.
Antes de finalizarmos nosso setup geral, vamos ajustar o arquivo crud-solana.ts na pasta tests para que ele importe as dependências que vamos precisar.
|
1 2 3 4 5 6 |
import assert from "assert"; import * as anchor from "@coral-xyz/anchor"; import { Program } from "@coral-xyz/anchor"; import { CrudSolana } from "../target/types/crud_solana"; |
E também o describe padrão para algumas variáveis globais que vamos precisar mais adiante, quando estivermos escrevendo os testes unitários.
|
1 2 3 4 5 6 7 8 9 10 |
describe("crud-solana", () => { // Configure the client to use the local cluster. anchor.setProvider(anchor.AnchorProvider.env()); const program = anchor.workspace.CrudSolana as Program<CrudSolana>; let libraryAccount : anchor.web3.Keypair; const signer = anchor.getProvider().publicKey; //os its vão aqui |
Com isso nosso projeto está pronto para implementarmos o CRUD.

#2 – Inicializando o Programa
Como em programas Solana geralmente temos de fazer a criação de uma account e não há um constructor padrão, é sempre de bom tom começar a programação pela função de inicialização dos dados. Para isso, vamos definir uma struct para o contexto de uma função que criaremos na sequência, chamado Initialize.
|
1 2 3 4 5 6 7 8 9 10 |
#[derive(Accounts)] pub struct Initialize<'info> { #[account(init, payer = signer, space = 8 + 4 + 4 + (50 * (4 + 32 + 32 + 2)))] pub library: Account<'info, Library>, #[account(mut)] pub signer: Signer<'info>, pub system_program: Program<'info, System>, } |
Nosso contexto de inicialização é bem padrão: ele define uma account (library), um signer e o programa que irá executar a criação (System). Atenção especial aqui às macros sobre a library que indicam que a account será criada na primeira chamada desse contexto (init), que o signer será o payer dessa transação e que o espaço necessário para nossa account é de:
- 8 bytes para o descritor da account;
- 4 bytes para o descritor do vetor de livros;
- 4 bytes para o contador de ids (32-bits);
- e 50x o espaço de um livro (70 bytes);
Ou seja, estamos alocando em nossa account o espaço necessário para armazenar 50 livros. Existem técnicas que podemos usar para expandir esse armazenamento mais tarde ou até poderíamos programar de modo que o armazenamento fosse infinito por padrão, mas são itens bem mais complicados e que fogem ao escopo deste tutorial. O que você deve saber neste momento é que existem um limite de 10.240 bytes (~10KB) de tamanho de account usado por uma única instrução e um limite máximo de ~10MB por account no geral. Assim, no máximo conseguiríamos alocar um espaço inicial para pouco mais de 140 livros considerando a configuração acima.
Dadas essas explicações e configurado esse contexto, volteo ao módulo principal do programa e mude a sua função initialize que vem por padrão para o seguinte código.
|
1 2 3 4 5 6 7 8 |
pub fn initialize(ctx: Context<Initialize>) -> Result<()>{ let library = &mut ctx.accounts.library; library.next_id = 0; library.books = Vec::new(); Ok(()) } |
Repare como estamos usando o contexto Initialize no primeiro parâmetro da função de mesmo nome. Com esse contexto (ctx) nós pegamos emprestado uma cópia mutável da library e inicializamos nela o gerador de ids e o vetor de livros. Note que o Vector aceita “infinitos” livros, mas na verdade a limitação dele é com o espaço da account onde ele está, como citado anteriormente.
Agora que criamos nossa primeira função, vamos programar nosso primeiro teste. Ou quase isso.
Na verdade eu não vou escrever um teste específico para o initialize, mas ao invés disso, vou fazer com que o initialize rode a cada teste executado, para garantir que os testes tenham sempre um ambiente limpo e inicializado corretamente, sem gerar qualquer conflito ou dependência entre eles. Isso é possível com a instrução beforeEach, dentro do describe.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
beforeEach(async () => { // Cria uma nova conta antes de cada teste libraryAccount = anchor.web3.Keypair.generate(); await program.methods .initialize() .accounts({ library: libraryAccount.publicKey, signer }) .signers([libraryAccount]) .rpc(); }); |
Aqui eu gero uma nova account a ser usada no teste e chamo a função de initialize, passando a account, o signer padrão do Anchor e o signer específico da account que será criada. Assim, antes de cada teste teremos uma account limpa para ser usada, algo que conseguiremos ver se está plenamente funcional logo mais, quando implementarmos a primeira funcionalidade do CRUD em si: o create/cadastro.

#3 – Cadastrando e Retornando Livros
A primeira operação do CRUD que vamos fazer é o cadastro. Como é de praxe, precisamos ter um contexto para a função e embora pareça tentador reaproveitar o contexto criado para a função initialize isso não é possível. Como o contexto do initialize descreve uma account com a macro init, se usássemos ele na função de criação de livro haveria uma tentativa de criar account do zero toda vez que fôssemos adicionar um novo livro, o que não é o comportamento desejado. Ao invés disso, vamos criar um novo contexto, específico para as funções do CRUD, como abaixo.
|
1 2 3 4 5 6 7 8 9 |
#[derive(Accounts)] pub struct BookDatabase<'info> { #[account(mut)] pub library: Account<'info, Library>, #[account(mut)] pub signer: Signer<'info>, } |
Nessa struct eu digo que a library é mutável (mut) e o signer também, já que vai depender de quem chamar a função. Repare que aqui eu não preciso especificar o programa externo que vamos rodar, pois não precisamos de nenhum além do nosso próprio.
Agora que já temos as estruturas auxiliares fica muito mais fácil, podendo partir para a função em si que vai dentro do módulo do programa, que fica como abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
pub fn add_book(ctx: Context<BookDatabase>, book_data: BookData) -> Result<()> { let library = &mut ctx.accounts.library; library.next_id += 1; let new_book = Book { id: library.next_id, title: book_data.title, author: book_data.author, year: book_data.year }; library.books.push(new_book); Ok(()) } |
Essa é uma função (fn) pública (pub) cujo contexto (ctx) é o BookDatabase que criamos há pouco e os dados do novo livro chegarão a partir de um parâmetro book_data do tipo BookData. Lembra que criamos uma struct BookData lá atrás? Ela é quase igual à Book, mas não tem id e serve apenas como tipo de parâmetro mesmo.
Dentro da função nós pegamos emprestado uma referência mutável para a library da account, incrementamos o contador de ides e criamos um novo livro a partir da struct Book usando os dados que vieram em book_data + o id gerado (autoincremental). Por fim, para salvar o novo livro basta chamarmos a função push existente no vector.
Para testarmos essa função temos de ir até o crud-solana.ts e adicionar nosso primeiro “it” nele, como abaixo. Para quem já escreveu testes em Jest ou Tape antes, não tem nenhuma novidade aqui.
|
1 2 3 4 5 6 7 8 9 10 11 |
it("should add book", async () => { await program.methods .addBook({ title: "Teste", author: "LuizTools", year: 2024 }) .accounts({ library: libraryAccount.publicKey, signer }) .rpc(); const library = await program.account.library.fetch(libraryAccount.publicKey); assert.ok(library.books.length === 1); }); |
Nosso teste de adição de livro chama a função addBook (note como o Anchor muda o snake case do Rust para camel case do JS automaticamente pra gente) passando um objeto com as propriedades definidas no BookData e na subfunção accounts passamos um objeto com as propriedades definidas no contexto BookDatabase. Como o resultado dessa transação é apenas um hash, desconsideramos o retorno e usamos a função fetch presente nas accounts para pegar os dados da nossa library e ver se o livro foi corretamente cadastrado como esperado.
Para rodar nosso teste, execute o comando ‘anchor test’ no terminal e tudo deve passar como esperado.
Note que acabamos testando também a leitura/retorno de livros com o teste acima. Em Solana nós temos como único retorno de funções programadas o hash da transação, logo não criaremos uma função específica para retornar um ou mais livros. Ao invés disso, sempre que precisar ler algum dado deve fazê-lo através do fetch na respectiva account, como fizemos na penúltima linha do teste. Uma vez que tenhamos o objeto da account de volta, podemos manipular ele como quisermos, iterando até encontrar o elemento que desejamos, por exemplo. Vou mostrar um exemplo melhor a seguir.

#4 – Atualizando um Livro
Agora vamos para o U de Update em nosso CRUD. Aqui temos uma complicação que a função de edit vai sempre receber um objeto BookData mas nem sempre iremos querer alterar todos os dados de um livro. Sendo assim, devemos criar uma lógica para comparar campo a campo e alterar somente aqueles que mudaram de fato. Sendo assim, abaixo uma sugestão de como criar a nossa função de edição que compara campo a campo para alterar somente aqueles que foram informados e que mudaram em relação aos valores já armazenados.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
pub fn edit_book(ctx: Context<BookDatabase>, id: u32, new_data: BookData) -> Result<()> { let library = &mut ctx.accounts.library; if let Some(book) = library.books.iter_mut().find(|b| b.id == id) { if new_data.title != "" && book.title != new_data.title { book.title = new_data.title; } if new_data.year > 0 && book.year != new_data.year { book.year = new_data.year; } if new_data.author != "" && book.author != new_data.author { book.author = new_data.author; } return Ok(()); } Err(CustomError::BookNotFound.into()) } |
Eu começo pegando uma referência mutável da library e em cima dela uso a função iter_mut do Rust para iterar de forma mutável sobre o vector. Para cada elemento presente, usamos um find para pesquisar o livro “b” cujo id seja igual ao id passado por parâmetro, retornando uma referência mutável do mesmo com a função Some.
Uma vez com o livro encontrado, comparamos se há mudança campo a campo (e se o campo foi passado com algum valor) e fazemos as alterações necessárias, retornando ok ao final. Caso não seja encontrado livro com o id em questão, devolvemos um erro personalizado de BookNotFound (repare a função into ao final da inicialização do erro, para que ocorra o typecasting para o tipo de erro padrão). Não se preocupe com a complexidade assintótica desse algoritmo, já que ele sempre irá rodar com poucos elementos uma vez que uma account não passa de 10MB (pouco mais de 142k livros no pior cenário possível).
Agora, para escrevermos o teste desta função nós precisamos fazer o cadastro antes da edição e depois a consulta para ver se somente o campo que passamos, mudou.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
it("should edit book", async () => { await program.methods .addBook({ title: "Teste", author: "LuizTools", year: 2024 }) .accounts({ library: libraryAccount.publicKey, signer }) .rpc(); const newTitle = "Teste2"; await program.methods .editBook(1, { title: newTitle, author: "", year: 0 }) .accounts({ library: libraryAccount.publicKey, signer }) .rpc(); const library = await program.account.library.fetch(libraryAccount.publicKey); const book = library.books.find((b) => b.id === 1); assert.ok(book.title === newTitle); assert.ok(book.author === "LuizTools"); assert.ok(book.year === 2024); }); |
Aqui está o complemento do teste de retorno de livros, já que carregamos a library com fetch e depois usamos a High Order Function find em cima do array de livros para iterar sobre eles e achar o livro específico que alteramos pelo seu id. Repare como informei ano 0 na edição e “” no autor, para que ela seja ignorada e se mantenha o ano e autor originais do cadastro. Assim no teste consigo testar todos os campos, para ver se ficaram como espero, apenas com o título alterado.
Se rodar a bateria de testes com anchor test, todos devem passar.
Para complementar, é interessante também testar o cenário de não encontrar o livro para edição. Veja um exemplo de teste abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
it("shouldn't edit book (not found)", async () => { try { await program.methods .editBook(999, { title: "Non-existent Book", author: "Nobody", year: 2025 }) .accounts({ library: libraryAccount.publicKey, signer }) .rpc(); assert.fail("Expected an error but did not receive one"); } catch (err) { assert.match(err.message, /BookNotFound/); } }); |
Repare como caso dê erro, verificamos se na mensagem do erro temos a regex /BookNotFound/. E caso não dê erro, o teste falha com o assert.fail.

#5 – Excluindo um Livro
Agora vamos para a quarta e última operação do CRUD: o D de Delete. Voltemos ao lib.rs para adicionar esta última função.
|
1 2 3 4 5 6 7 8 9 |
pub fn delete_book(ctx: Context<BookDatabase>, id: u32) -> Result<()> { if let Some(index) = ctx.accounts.library.books.iter().position(|b| b.id == id) { ctx.accounts.library.books.remove(index); return Ok(()) } Err(CustomError::BookNotFound.into()) } |
Nela, eu recebo o id do livro a ser excluído e procuro ele usando um iterador (iter) a fim de procurar seu index com a função position, usando o id como filtro. Como não iremos alterar dados do livro eu posso usar iter() ao invés de iter_mut() como fizemos na edição. Uma vez que eu tenha o índice do livro, podemos usar a função remove do vector e retornar ok em caso de sucesso ou um erro de BookNotFound caso não encontre o livro a ser excluído.
Para escrever o teste desta função é bem simples e sem grandes novidades, devemos apenas cadastrar um livro primeiro, depois removê-lo e por fim ver se o array está vazio novamente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
it("should delete book", async () => { await program.methods .addBook({ title: "Teste", author: "LuizTools", year: 2024 }) .accounts({ library: libraryAccount.publicKey, signer }) .rpc(); await program.methods .deleteBook(1) .accounts({ library: libraryAccount.publicKey, signer }) .rpc(); const library = await program.account.library.fetch(libraryAccount.publicKey); assert.ok(library.books.length === 0); }); |
Por fim, assim como fizemos na edição, vamos fazer um teste específico para o cenário de fracasso também.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
it("shouldn't delete book (not found)", async () => { try { await program.methods .deleteBook(999) .accounts({ library: libraryAccount.publicKey, signer }) .rpc(); assert.fail("Expected an error but did not receive one"); } catch (err) { assert.match(err.message, /BookNotFound/); } }); |
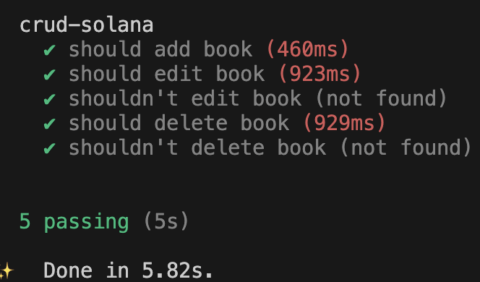
Com isso, ao rodar o comando anchor test, todos os seus testes devem estar passando, como abaixo.
Até mais!





Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.