

Você já se perguntou o que acontece quando você digita uma URL no navegador, do início ao fim da requisição?
Neste artigo, eu vou falar não apenas sobre como funciona o HTTP/1.1, mas também como o Node.js trabalha com este importantíssimo protocolo da web. Assim, mesmo que você não programe em Node, este artigo serve de referência para o protocolo HTTP em si. Caso programe em Node, vai te dar uma boa base do módulo http do Node, um dos mais essenciais.
Veremos neste artigo:
- O protocolo HTTP
- O módulo http do Node.js
- Construindo um servidor HTTP em Node
- Fazendo requisições HTTP em Node
Se preferir, você pode acompanhar boa parte deste conteúdo no vídeo abaixo.
Vamos lá!

O protocolo HTTP
Se você já fez uma entrevista para uma vaga de programador web provavelmente já lhe perguntaram “o que acontece quando você digita algo na caixa de busca do Google e aperta Enter?”
É uma pergunta muito popular pois os entrevistadores técnicos querem entender se você consegue explicar alguns dos conceitos básicos e se você tem alguma ideia de como a Internet realmente funciona.
Neste tópico eu vou mostrar pra você o que acontece quando você digita um endereço na barra do navegador e aperta Enter. É um tópico muito interessante e útil, pois é uma tecnologia muito presente, que raramente muda e que permite a existência de um complexo e vasto ecossistema que é a Internet.
Então começando a explicação, imagine que você digitou uma URL no navegador e apertou Enter. É aqui que nossa aventura começa…
DNS Lookup
O browser começa o DNS Lookup para obter o endereço IP do servidor. O nome do domínio é um apelido para nós humanos lembrarmos mais facilmente, mas a internet é organizada de maneira que os computadores trabalham apenas com os endereços IP para saber onde estão os computadores em um formato numérico como 222.324.3.1 (IPv4).
O primeiro lugar onde o IP é procurado pelo browser é no cache de DNS da sua máquina. Se não estiver lá, ele vai procurar no arquivos hosts (que varia de local conforme seu SO). Se não encontrar nada lá, a última alternativa é perguntar ao servidor de DNS.
O endereço do servidor de DNS fica salvo nas preferências do sistema, na parte de redes. Dois populares servidores de DNS são:
- 8.8.8.8: o servidor de DNS do Google;
- 1.1.1.1: o servidor de DNS da CloudFlare;
O mais comum é que as pessoas usem o servidor de DNS fornecido pelo seu provedor de Internet.
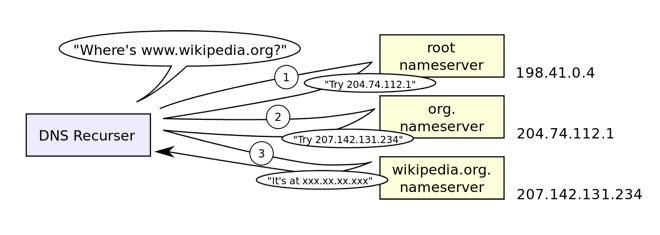
E quando esse servidor de DNS não possui a resposta para a requisição realizada? Aí é que entram os servidores raiz de DNS, 13 pontos de conexão ao redor do mundo que, ao invés de terem todos os endereços do mundo cadastrados, possuem o endereço dos servidores top-level.
Um servidor top-level é aquele responsável por uma extensão TLD (top-level domain) como .com, .br, .org, etc. O servidor top-level para os domínios .br, por exemplo, possui cadastrado todos os endereços de domínios terminados em .br.
Note que neste servidores existem caches. Conforme vão sendo feitas perguntas que eles não conhecem a resposta (i.e. domínios que eles não saibam o IP) eles descobrem onde fica perguntando uns aos outros e depois armazenam em seus caches locais, para que na próxima requisição seja mais rápido dar a resposta.
Mas ok, o processo de DNS lookup descobriu o IP da máquina onde está a URL que você está querendo acessar. Isso porque todos os domínios de Internet devem ser adquiridos junto a vendedores certificados, que possuem Name Servers online 24x7x365 (o ano inteiro, todos os dias, o tempo todo). Quando você compra um domínio, você recebe o endereço dos seus Name Servers, que são sempre mais de um para garantir alta disponibilidade, como por exemplo:
- ns1.dreamhost.com
- ns2.dreamhost.com
- ns3.dreamhost.com
Inicia-se a procura pela máquina que queremos acessar no primeiro NS e somente são utilizados os outros no caso do primeiro não estar online. Mas enfim, nossa jornada de DNS Lookup termina aqui, acabamos de encontrar a máquina onde o site está hospedado.
Conexão e Requisição
Uma vez que temos o endereço IP da máquina correta, o browser pode se conectar na mesma para podermos enviar as requisições.
A requisição é um documento de texto estruturado de uma maneira específica conforme determinada pelo protocolo de comunicação. Ela é composta de três partes:
- a linha de requisição
- o cabeçalho de requisição
- o corpo de requisição
A linha de requisição, que é obviamente uma única linha, possui:
- o método HTTP
- o local do recurso a ser acessado
- a versão do protocolo
Por exemplo:
|
1 |
GET / HTTP/1.1 |
O cabeçalho da requisição é composto e pares chave-valor que definem algumas propriedades da requisição. Existem dois deles que são obrigatórios: Host e Connection, enquanto que todos os demais são opcionais.
Exemplo:
|
1 2 |
Host: luiztools.com.br Connection: close |
O Host indica o nome do domínio que você quer acessar, enquanto que Connection indica se queremos que a conexão seja fechada ou se mantenha aberta após a requisição.
Alguns outros cabeçalhos muito comuns são:
- Origin
- Accept
- Accept-Encoding
- Cookie
- Cache-Control
- Dnt
Mas existem muitos outros. O cabeçalho da requisição termina com uma linha em branco.
Já o corpo da requisição é opcional, não sendo utilizados em requisições GET, por exemplo, mas muito utilizado em requisições POST e alguns outros verbos, além de poder conter dados em vários formatos como JSON.
Como estamos em um cenário de acesso a uma URL, ou seja, um GET, ignoraremos o corpo por enquanto.
A resposta
Uma vez que a requisição é enviada, o servidor processa ela e envia de volta uma resposta. A resposta começa com o código de status e a mensagem de status. Se a requisição foi bem sucedida e retornar um 200, ela começará com um:
|
1 |
200 OK |
Mas as requisições podem ser respondidas com diferentes códigos e status, como estes:
|
1 2 3 4 5 6 |
404 Not Found 403 Forbidden 301 Moved Permanently 500 Internal Server Error 304 Not Modified 401 Unauthorized |
Eu falo com mais detalhes dos status code neste outro artigo. Logo após, a resposta possui uma lista de cabeçalhos HTTP e o corpo da resposta, que no caso de acessar uma página de um site, será um documento HTML.
Analisando o HTML
Uma vez que o navegador obtenha o HTML do corpo da resposta e inicie a sua análise, ele irá repetir o mesmo processo completo (do DNS lookup até receber o arquivo) para cada um dos recursos presentes na página HTML como:
- arquivos CSS
- imagens
- ícones
- arquivos JS
E aí inicia o processo de renderização da página conforme as regras de todos estes arquivos juntos na estrutura HTML.
É importante entender que, apesar do exemplo ter sido em cima de HTML, que ele é o mesmo para qualquer recurso na web.

O módulo HTTP do Node.js
O módulo http do Node.js fornece funções úteis e classes para construir um servidor HTTP. Ele é um módulo-chave para os recursos de rede do Node.
Ele pode ser facilmente incluído em um módulo Node.js usando:
|
1 |
const http = require('http') |
O objeto http declarado ali possui algumas propriedades e métodos, além e algumas classes.
http.METHODS
Esta propriedade lista todos os métodos HTTP suportados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
> require('http').METHODS [ 'ACL', 'BIND', 'CHECKOUT', 'CONNECT', 'COPY', 'DELETE', 'GET', 'HEAD', 'LINK', 'LOCK', 'M-SEARCH', 'MERGE', 'MKACTIVITY', 'MKCALENDAR', 'MKCOL', 'MOVE', 'NOTIFY', 'OPTIONS', 'PATCH', 'POST', 'PROPFIND', 'PROPPATCH', 'PURGE', 'PUT', 'REBIND', 'REPORT', 'SEARCH', 'SUBSCRIBE', 'TRACE', 'UNBIND', 'UNLINK', 'UNLOCK', 'UNSUBSCRIBE' ] |
http.STATUS_CODES
Esta propriedade lista todos os códigos de status HTTP e sua descrição:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
> require('http').STATUS_CODES { '100': 'Continue', '101': 'Switching Protocols', '102': 'Processing', '200': 'OK', '201': 'Created', '202': 'Accepted', '203': 'Non-Authoritative Information', '204': 'No Content', '205': 'Reset Content', '206': 'Partial Content', '207': 'Multi-Status', '208': 'Already Reported', '226': 'IM Used', '300': 'Multiple Choices', '301': 'Moved Permanently', '302': 'Found', '303': 'See Other', '304': 'Not Modified', '305': 'Use Proxy', '307': 'Temporary Redirect', '308': 'Permanent Redirect', '400': 'Bad Request', '401': 'Unauthorized', '402': 'Payment Required', '403': 'Forbidden', '404': 'Not Found', '405': 'Method Not Allowed', '406': 'Not Acceptable', '407': 'Proxy Authentication Required', '408': 'Request Timeout', '409': 'Conflict', '410': 'Gone', '411': 'Length Required', '412': 'Precondition Failed', '413': 'Payload Too Large', '414': 'URI Too Long', '415': 'Unsupported Media Type', '416': 'Range Not Satisfiable', '417': 'Expectation Failed', '418': 'I'm a teapot', '421': 'Misdirected Request', '422': 'Unprocessable Entity', '423': 'Locked', '424': 'Failed Dependency', '425': 'Unordered Collection', '426': 'Upgrade Required', '428': 'Precondition Required', '429': 'Too Many Requests', '431': 'Request Header Fields Too Large', '451': 'Unavailable For Legal Reasons', '500': 'Internal Server Error', '501': 'Not Implemented', '502': 'Bad Gateway', '503': 'Service Unavailable', '504': 'Gateway Timeout', '505': 'HTTP Version Not Supported', '506': 'Variant Also Negotiates', '507': 'Insufficient Storage', '508': 'Loop Detected', '509': 'Bandwidth Limit Exceeded', '510': 'Not Extended', '511': 'Network Authentication Required' } |
http.createServer()
Retorna uma nova instância da classe http.Server e seu uso é muito simples:
|
1 2 3 |
const server = http.createServer((req, res) => { //cada requisição recebida dispara este callback }) |
http.request()
Realiza uma requisição HTTP para um servidor, criando uma instância da classe http.ClientRequest.
http.get()
Similar ao http.request(), mas automaticamente define o método HTTP como GET e já finaliza a requisição com req.end() automaticamente.
O módulo HTTP também fornece cinco classes:
- http.Agent
- http.ClientRequest
- http.Server
- http.ServerResponde
- http.IncomingMessage
Um objeto http.ClientRequest, por exemplo, é criado quando chamamos http.request() ou http.get(). Quando uma resposta é recebida o evento response é chamado com a resposta, passando uma instância de http.IncomingMessage como argumento.
Os dados retornados por uma resposta pode ser lido de duas maneiras:
- você pode chamar o método response.read()
- no event handler response você pode configurar um listener para o evento data, assim você pode receber os dados em formato de stream (bytes)
Já a classe http.Server é comumente instanciada e retornada quando criamos um novo servidor usando http.createServer(). Uma vez que você tenha um objeto server, você pode acessar seus métodos:
- close() que encerra as atividades do servidor, não aceitando mais novas requisições;
- listen() que inicia o servidor HTTP e espera novas conexões;
A classe http.ServerResponse é muito utilizada como argumento nos callbacks que tratam a resposta de requisições, a famosa variável ‘res’ presente em muitos callbacks, como abaixo:
|
1 2 3 |
const server = http.createServer((req, res) => { //res é um objeto http.ServerResponse }) |
É importante sempre salientar que após utilizarmos o objeto res devemos chamar o método end() para fechar a resposta e enviar a mesma para o cliente que fez a requisição.
Objetos res/response possuem alguns métodos para interagir com os cabeçalhos HTTP:
- getHeadernames() traz a lista de nomes dos header presentes na resposta;
- getHeaders() traz uma cópia dos headers presentes;
- setHeader(‘nome’, valor) altera o valor de um header;
- getHeader(‘nome’) retorna o valor de um header;
- removeHeader(‘nome’) remove um header;
- hasHeader(‘nome’) retorna true se a response possui este header;
- headersSent() retorna true se os headers já foram enviados ao cliente;
Depois de fazer as alterações que desejar nos cabeçalhos do response, você pode enviá-los ao cliente usando response.writeHead(), que aceita o statusCode como o primeiro parâmetro, a mensagem opcional e os cabeçalhos.
|
1 2 |
response.statusCode = 500 response.statusMessage = 'Internal Server Error' |
Ok, mas nem só de cabeçalhos vive a resposta, certo? Para enviar dados ao cliente no corpo da requisição, você usa write(). Ele vai enviar dados bufferizados para a stream de resposta.
E por fim, a classe http.IncomingMessage é criada nas requisições. Mostrarei ela na prática mais à frente.
Está curtindo o post? Para uma formação ainda mais completa como programador web recomendo meu livro sobre programação web com Node.js clicando no banner abaixo!

Construindo um servidor HTTP em Node
Um servidor web HTTP para fazer um Olá Mundo é algo muito simples e popularmente conhecido na Internet. Você pode copiar o código abaixo e colar em um arquivo de texto com extensão ‘.js’:
|
1 2 3 4 5 6 7 8 9 10 |
const http = require('http') const port = 3000 const server = http.createServer((req, res) => { res.statusCode = 200 res.setHeader('Content-Type', 'text/plain') res.end('Olá Mundo!n') }) server.listen(port, () => { console.log(`Servidor iniciou em http://localhost:${port}/`) }) |
Analisando linha por linha, temos:
- inicialização do objeto HTTP;
- definição da porta que o servidor irá esperar requisições;
- criação do servidor e definição do callback que irá tratar cada requisição (objeto http.IncomingMessage);
- dentro do callback modificamos a resposta (objeto http.ServerResponse) para retornar o status 200 (ok) e definir o cabeçalho como sendo texto e o HTML como sendo apenas ‘Olá Mundo!’ (fechando a resposta também);
- e por fim, iniciamos a execução do servidor na porta especificada, definindo o callback que vai executar quando o servidor começar a funcionar;
Depois, para executar (considerando que você já tenha instalado o Node.js na sua máquina), basta abrir o terminal de linha de comando, navegar até a pasta onde você salvou o arquivo com ‘cd’ e depois rodar:
|
1 |
C:Usersluiztoolsdocuments> node servidor.js |
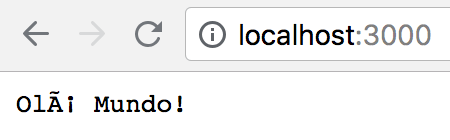
Se tudo funcionar, uma mensagem irá aparecer no console indicando que o servidor está funcionando. Se você acessar no navegador o endereço localhost:3000 você receberá como retorno um Olá Mundo muito simples, mas funcional (ignore o problema de encoding, por favor).
Fazendo requisições HTTP com Node
Nesta seção veremos como fazer requisições HTTP com Node.js. Na verdade usarei HTTPS nestes exemplos, que é o mesmo protocolo mas operando sobre canal criptografado (TLS/SSL), pra evitar captura de dados por intrusos lendo o canal de comunicação.
GET Request
Fazer uma requisição GET em Node.js é bem simples, como mostra o código abaixo. Fazemos GET requests quando queremos ler uma página da Internet ou obter dados de uma API:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
const https = require('https') const options = { hostname: 'www.google.com.br', port: 443, path: '/about/', method: 'GET' } const req = https.request(options, (res) => { console.log(`statusCode: ${res.statusCode}`) res.on('data', (d) => { process.stdout.write(d) }) }) req.on('error', (error) => { console.error(error) }) req.end() |
Nele, eu carreguei o módulo https ao invés do http que vínhamos trabalhando até então, defini que o site que vamos acessar é o google.com.br, na página ‘about’, usando o método GET (pois queremos obter as informações desta página) e na porta 443.
A porta 443 é a padrão para HTTPS, enquanto que a 80 é a padrão para HTTP.
Todas estas definições foram armazenadas em uma constante options que será passada para a função https.request que criará um novo objeto de requisição (o ‘req’). O callback desta função será disparado quando o GET terminar. Nesta situação, ele vai imprimir no console os dados retornados.
Além disso, foi determinado um listener (‘on’) para erros, que serão jogados também no console.
Finalizamos e enviamos a requisição através da chamada da função end(). O resultado será um monte de HTML no seu console, nada muito útil, mas funcional.
POST Request
Fazer um POST é igualmente simples, com a diferença de que aqui usaremos o corpo da requisição HTTP, que no GET não é utilizado. Fazemos POST requests quando queremos enviar dados para um servidor (ao invés de receber, como no caso do GET) e o trecho de código abaixo exemplifica isso:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
const https = require('https') const data = JSON.stringify({ exemplo: 'valor' }) const options = { hostname: 'requestbin.fullcontact.com', port: 443, path: '/14dbyg71', method: 'POST', headers: { 'Content-Type': 'application/json', 'Content-Length': data.length } } const req = https.request(options, (res) => { console.log(`statusCode: ${res.statusCode}`) res.on('data', (d) => { process.stdout.write(d) }) }) req.on('error', (error) => { console.error(error) }) req.write(data) req.end() |
Neste exemplo eu usei os serviços da RequestBin, um site onde você cria uma URL sua para fazer testes de requisições. O resultado da requisição você pode ver abaixo:
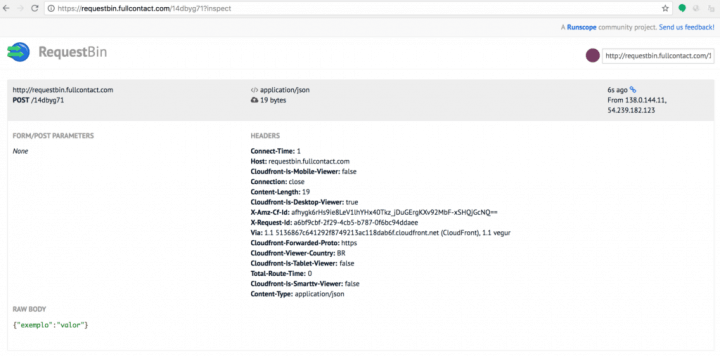
A grande diferença do código do POST vs GET é o objeto data, onde criamos um JSON (uma notação bem popular para envio de dados pela Internet) e enviamos ele usando a função req.write, lá no final do código.
Note que ao criarmos o https.request também definimos um callback para exibir os dados retornados pelo POST. Sim, não é somente o GET que retorna dados, o POST também retorna o conteúdo da resposta, embora seu uso primário seja para enviar dados.
PUT, DELETE, PATCH, etc
Existem muitos outros verbos HTTP, cada um com a sua utilidade. Embora possamos emular qualquer comportamento usando apenas GET e POST, é interessante usar e implementar os verbos adequados para garantir o correto funcionamento dos servidores web.
Outros verbos úteis são:
- PUT: para atualizar um documento;
- DELETE: para excluir um documento;
- PATCH: para atualizar parte de um documento;
A forma de uso é a mesma que foi exemplificada no POST, mudando apenas no objeto options o method utilizado.
E com isso encerramos este nosso extenso artigo/tutorial sobre o protocolo HTTP e sua aplicação no Node através do módulo homônimo. Querendo aprender como utilizar HTTP na prática através de construção de WebAPIs, acesse este post com Mongo, este com MySQL e este com SQL Server.
Ficou com alguma dúvida? Deixe nos comentários terei muito prazer em ajudar!
Curtiu este tutorial? Conheça o meu curso online de Node.js e MongoDB para aprender a fazer aplicações web e APIs incríveis com esta fantástica plataforma. Basta clicar no banner abaixo!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.
[…] com a primeira parte. Se não conhece o protocolo HTTP, essencial para desenvolvimento web, leia este post. Já se você não gosta de ORMs e quiser aprender a mexer com o MongoDB nativamente, use este post […]
Eu gostaria de parabeniza-lo pelo tutorial.
Apenas citar como forma de colaboração que na rota de login, o guards esta interferindo na posição informada pelo tutorial. Então sugiro colocar o código:
UseGuards(AuthGuard)
@Get(“clientes”)
getClientes() {
return this.appService.getClientes();
}
abaixo do código:
@Post(“login”)
async login(@Body() body) {
…
return { auth: true, token: token };
}
throw new UnauthorizedException();
}
Assim , o código segue o fluxo de leitura de cima para baixo e a rota privada fica sendo apenas a última. Porque ao realizar novo login da maneira que esta atualmente o código, o body.user vem como undefined
Isso ai. Um grande abraço!
Agradeço a contribuição mas nesse tutorial aí não tem guard nenhum não. Usamos no máximo a lib HTTP pura do Node.js, hehe.
Sensacional, gostaria de saber se poderia disponibilizar o link para aprofundar ainda mas no assunto de como funciona por trás.
Infelizmente eu não tenho mais conteúdo do que o exposto neste artigo e nos demais citados ao longo dele.