
Desde 2010 meu envolvimento com mecanismos de busca passou de um simples usuário do Google a um arquiteto e desenvolvedor de tais soluções.
De lá para cá tive a oportunidade de projetar e construir ferramentas verticais de busca (aquelas que buscam coisas específicas, ao contrário do Google que é genérico) que são usadas por milhares de pessoas todos os dias, sendo a mais famosa o Busca Acelerada (buscador vertical de veículos à venda na Internet), mas também outras menos conhecidas (por enquanto…) como o BuildIn, um buscador de notícias da construção civil e o Só Famosos, um buscador de notícias de celebridades.
Neste post, tento resumir os principais elementos necessários para se criar um mecanismo de busca, independente da linguagem de programação escolhida. No final do post, passo tutoriais de como programar tais mecanismos.

Passo 1: Esqueça o que você sabe sobre consultas
Se você nunca criou um mecanismo de busca antes e tudo o que sabe de buscas é usar SELECTs com LIKEs em um banco SQL, esqueça tudo isso. Claro, acho meio óbvio que se você está lendo esse post deve imaginar que qualquer mecanismo de busca que se preze (até mesmo o Bing) não faz LIKEs em milhões de páginas da Internet procurando pelos termos que você digitou.
A criação de um mecanismo de busca é ao mesmo tempo complexa (pois é fora do formato tradicional que estamos acostumados) e simples, pois os mesmos elementos estão sempre presentes. O importante aqui é entender os conceitos-chave para compor a solução ideal para o seu problema.
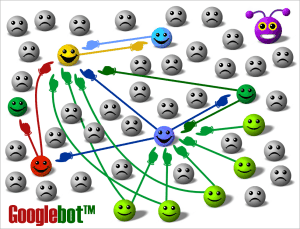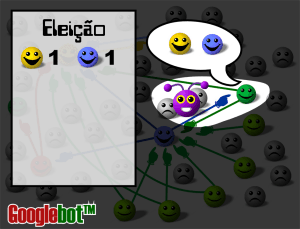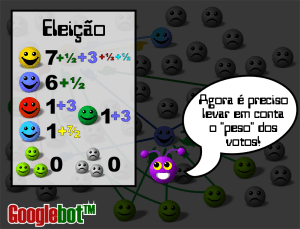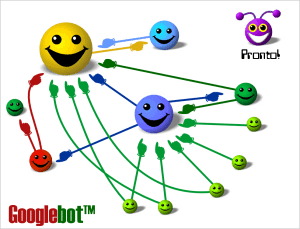
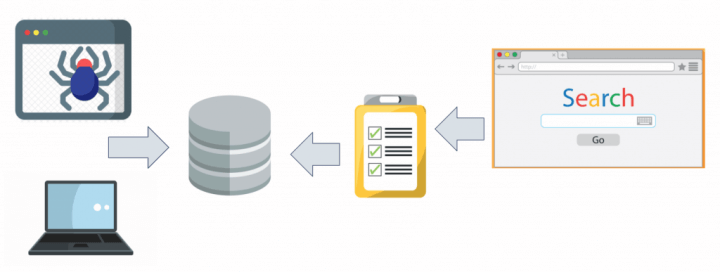
Passo 2: Criar um crawler
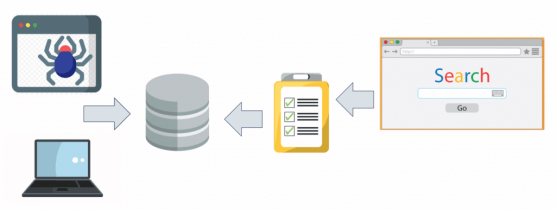
Independente do mecanismo de busca que você for criar (seja ele vertical ou genérico), você terá de criar um crawler primeiro. Um crawler ou spider é um “robô” (um algoritmo que funciona sozinho) que busca informações em uma determinada fonte de dados e cataloga elas no índice do seu mecanismo de busca, para que as consultas posteriores passem a considerar aqueles novos dados em seus resultados. Sem o trabalho do crawler é impossível criar um mecanismo de busca eficiente.
Em um buscador vertical, por exemplo de carros, o crawler acessa uma lista de sites de classificados de carros e procura as informações de cada um dos anúncios, coletando elas de maneira organizada e salvando em um banco de dados. Em um buscador de informações, o crawler acessa uma lista de notícias ou documentos e salva as partes que interessam para a busca em um banco de dados. Dependendo das suas necessidades o seu crawler pode separar a informações em categorias (carros, motos e caminhões, por exemplo), ou então as partes dela conforme seu conteúdo (imagens, notícias e arquivos, por exemplo).
É importante frisar que seu crawler deve ser um algoritmo separado do seu buscador, que deverá ficar rodando periodicamente para manter sua base de dados atualizada. Dependendo do volume de informações que você precisa atualizar na base, talvez seja interessante fazê-lo durante os horários de menor audiência para evitar lentidões em seu buscador. E dependendo da periodicidade com que os dados são atualizados, talvez você precise criar uma política para não ter de atualizar toda sua base toda vez que o crawler rodar.
Este processo de funcionamento do crawler chamamos de webcrawling. Webcrawlers como os do Google (chamado de GoogleBot) são muito complexos e não apenas lêem uma lista de sites mas “seguem” cada um dos links de cada site percorrendo assim todo emaranhado que é a nossa web atual. Cada vez que ele encontra um novo site que ele não conhecia, coloca-o no índice principal do Google para passar a ser rastreado periodicamente a partir de então.
Curiosidade: o GoogleBot original, que era muito bom para sua época, conseguia se replicar em 4 cópias e percorrer 100 páginas por segundo, catalogando 600kb de dados por segundo em sua base de dados.
Falo mais sobre bots nesse vídeo:

Passo 3: Criar um índice
Quando o seu crawler ler as informações de uma página ou documento você vai querer salvar apenas aquelas que são importantes para a busca, evitando que seu banco de dados vire algo colossal. As informações que lhe serão úteis na pesquisa variam de vertical para vertical, mas geralmente são um reflexo dos tipos de filtros que você irá disponibilizar ao seu usuário no site de busca, sendo um campo de texto livre o filtro mais comum (como o Google faz). Esse compilado de informações úteis para a pesquisa é o que chamamos de índice e é aqui onde mora a real complexidade de se criar um mecanismo que funcione de maneira eficaz e eficiente.
Os índices mais comuns de serem criados para mecanismos de busca baseados em texto são os índices invertidos. Por padrão os bancos de dados criam o que chamamos de forward index, ou índices diretos, onde com base no valor de uma chave do registro/documento, encontramos o restante do seu conteúdo. A ideia do índice invertido é o oposto: com base em um pedaço do conteúdo do registro/documento, encontramos sua chave para trazer o registro completo. Afinal, o usuário sabe algumas palavras do que ele vai buscar, mas não sabe qual a chave do registro/documento que ele quer, certo?!
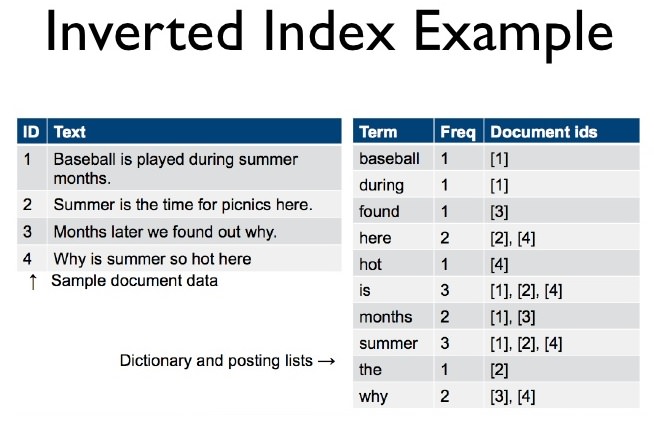
Uma técnica comum para criarmos este tipo de índice de maneira eficiente para uma pesquisa textual é montarmos um forward index primeiro, onde nossa chave será o identificador único do registro/documento e o seu valor será um conjunto de tags (strings) que devem levar o usuário àquele registro. É importante frisar que esse índice deve ser criado de maneira normalizada (sem acentos, por exemplo). Com o forward index pronto, você deverá criar o inverted index da seguinte maneira: para cada tag presente no registro atual (considerando que eu estou percorrendo os registros do forward index do primeiro ao último) eu adiciono a tag no índice invertido com o identificador do registro como seu valor. Assim, quando terminarmos de percorrer todo forward index teremos um índice invertido onde, para cada tag, sabemos todos os registros onde ela aparece.
Você pode ainda colocar elementos adicionais ao seu índice como um peso para cada tag em cada documento, por exemplo, para ajudar na ordenação dos resultados, calcular a densidade de cada palavra em cada documento, a sua proximidade do início do documento (e consequente relevância para o assunto) e muito mais. Esses “adicionais” é que geram tanta diferença entre pesquisar em um buscador como o Google vs pesquisar a mesma coisa no Bing ou no Yahoo!, por exemplo.
Curiosidade: você vai precisar conhecer um pouco de Estruturas de Dados para construir esses índices que mencionei e é aqui onde separamos os meninos dos homens na programação. Geralmente esses índices são criados em memória usando tabelas Hash que no Java, por exemplo, podem ser criadas com a coleção HashMap, enquanto que no C# podem ser criados com a coleção Dictionary. Independente da escolha, a chave (key) do índice invertido será uma String (a tag) enquanto que o valor (value) será uma coleção de inteiros (os ids dos registros no banco). Soluções mais complexas podem ser usadas dependendo da sua experiência, como usar Redis para os índices, usar Elastic Search para consultas complexas ou índices multivalorados no MongoDB. Mas garanto por experiência própria que as coleções acima mencionadas dão conta de buscadores básicos (até 1 milhão de registros indexados, aproximadamente).
A seguir veremos como consultar esse índice de maneira eficiente.
Passo 4: Criar um algoritmo de busca
Uma vez que você tem seu índice pronto, você terá de codificar o seu algoritmo de busca. Esse algoritmo também varia bastante conforme o que está sendo buscado. Em um algoritmo tradicional para busca textual, recebemos como entrada do usuário uma expressão que devemos normalizar (remover acentos, colocar tudo em maiúsculas ou minúsculas, entre outras tarefas incluindo corrigir erros de ortografia) para particioná-la e submetê-la ao nosso índice em partes, tag por tag gerada após a normalização.
Vamos pensar que o usuário pesquisou por “carro usado”, o que nos dá duas tags: “carro” e “usado”. Primeiro vamos em nosso índice procurar pela tag “carro”, onde obteremos as chaves de todos os registros que possuem a tag carro em seus dados. Depois, vamos em nosso índice procurar pela tag “usado”, onde obteremos as chaves de todos os registros que possuem a tag usado em seus dados. Agora, fazemos a intersecção dessas duas buscas (lembra de Teoria dos Conjuntos?), restando apenas uma coleção de chaves de registros que possuem ambas tags.
Alguns algoritmos não possuem esse tipo de precisão, trazendo registros que possuam apenas uma das tags mencionadas. Outros, são ainda mais críticos, exigindo que as tags sejam digitadas na mesma ordem em que são encontradas nos registros (se pesquisasse por “usado carro” não traria nada, por exemplo). Novamente, esses detalhes são a diferença na hora de exibir os resultados de um mesmo assunto em dois buscadores diferentes. Você terá de encontrar o que funciona para o seu domínio de problema.
Curiosidade: o segredo para construir um bom algoritmo é conhecer Estrutura de Dados (novamente) e Teoria dos Conjuntos. Algoritmos usam estruturas como Matrizes de Dispersão e comandos como intersecções, diferença, complemento e uniões de conjuntos para gerar os resultados, tudo dependendo das possibilidades que você quer dar ao seu usuário (AND, OR, etc). Em Java temos a excelente coleção HashSet para lidar com conjuntos, enquanto que o equivalente mais próximo em C# é o HashSet, mas que é inferior à sua contraparte open-source de mesmo nome. Voltando a citar o Redis, ele possui um tipo de coleção Set também, para lidar com operações entre conjuntos.

Passo 5: Criar o software cliente
Uma vez que você montou todo o backend de um mecanismo de busca, está na hora de criar a sua interface. Nenhuma novidade aqui: vai depender do buscador que você está criando. Eu sempre criei buscadores web mas com o passo-a-passo acima tanto faz se será web, desktop ou mobile. Você inclusive pode disponibilizar o seu algoritmo de busca via API e permitir que diferentes interfaces sejam criadas pra ele, para que o usuário utilize da maneira que melhor lhe convier.
Duas páginas merecem atenção aqui: a página de busca e a de resultados.
A página de busca, que pode ser apenas uma barra no topo do site ou algo mais sofisticado com algumas categorias pré-definidas, é onde o usuário vai usar os filtros que você disponibilizar a ele. Boas práticas nessa página incluem colocar o mínimo de filtros possível (forneça a opção de busca avançada se for necessário) e também colocar um autocomplete na busca, que vá sugerindo termos para evitar que o usuário escreva errado ao mesmo tempo que facilita a vida dele que pode clicar em uma das sugestões e já ver os resultados.
Já a página de resultados, essa depende da arquitetura da informação que você catalogou. Por exemplo, no Busca Acelerada apenas guardamos um resumo das principais informações do anúncio, cabendo ao visitante clicar no mesmo para ver os detalhes na página original do vendedor. O número de resultados disponíveis e a forma como eles serão apresentados têm de ser testados com seu público para determinar o que funciona melhor pra eles.
Feito essas duas páginas você terá o mínimo para lançar seu mecanismo de busca no ar!
Passo 6: Aperfeiçoar
Mesmo depois de pronta a versão 1.0 sempre há coisas a melhorar. Minha sugestão é colher feedback dos seus usuários com a técnica de NPS logo abaixo dos resultados da página. Procure indicar sua ferramenta para os amigos próximos e assista eles usando, para entender seu comportamento, ou então instale gravadores de sessão como HotJar, ClickTale e InspectLet, todos gratuitos, para ver como seus usuários usam sua ferramenta. Grave em logs no banco de dados as pesquisas que eles fazem e quantos resultados retornam, para trabalhar em cima dos pontos fracos e falhas do seu software e entender mais o que é pesquisado mais comumente.
E não pára por aí. Fique sempre atento a novas tecnologias que podem ajudar a melhorar seu buscador, principalmente bases de dados NoSQL e ferramentas open-source como RethinkDB, InfluxDB, Apache Hadoop, Apache Lucene e muitas outras. O segredo aqui é estar refinando sempre em busca de um mecanismo de busca cada dia melhor. Se o Google continua a melhorar seu buscador que já é excelente, que dirá o buscador que eu ou você construímos…
Nesse post aqui eu ensino como criar um mecanismo de busca com Node.js + MongoDB, uma combinação bem popular atualmente e neste aqui usando ASP.NET Core + MongoDB. Já neste outro post, ensino como criar um webscrapper, um tipo de crawler que lê informações de sites HTML.
No vídeo abaixo você também confere um passo a passo usando Node.js e MongoDB:
E aí, deixe o link do buscador que construiu aí nos comentários e vamos trocar experiências!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.
Muito bom
🙂
Criar um mecanismo de busca e muito bom
Veja http://www.youtubetv.com.br
Luiz não me lembro de ter visto ainda no seu blog, mas como é que está as pageviews ou acessos diários de seus projetos? em especial o buscaacelerada. Tudo bem se não quiser falar, apenas fiquei curioso quanto a isso.
O Busca Acelerada possui aproximadamente 500k visitas/mês somando desktop + mobile, o que gera uns 2M views/mês. Já o SóFamosos está engatinhando ainda, nem vale a pena citar números. Alguns dos outros projetos que fiz não são meus, fui pago para fazê-los para outras empresas, não faço ideia de como estão se saindo.
nossa @luizfernandojr:disqus acesso o busca acelerada e não imaginava que tivesse esse quantidade visitas….parabéns pelo projeto.
Valeu. 🙂
@luizfernandojr:disqus vc tem algum post sobre a estrutura que o busca acelerada usa atualmente, sobre servidores e custos para manter o projeto no ar.
Não escrevo nada de infra aqui no blog (até porque não manjo muito do assunto), mas os custos são baixos, algo como U$120/mês na AWS.
Qual a lista de programas que usaria pra criar um programa de busca para android ?
Depende muito do que você gostaria de buscar. Se os dados que quiser buscar tem de ser pesquisados diretamente no, terá de fazer um índice invertido in-memory para que a busca seja otimizada antes de chegar no SQLite. Já se os dados estão remotos, pode criar uma API de busca com as dicas desse tutorial aqui: https://www.luiztools.com.br/post/como-criar-um-mecanismo-de-busca-com-nodejs-mongodb/
Luiz, boa tarde!!
Tenho uma idéia de um site de busca, ou aplicativo, porém não tenho conhecimento de TI para por em execução esta idéia.
Caso queira ouvi-la pra ver se tem interesse em desenvolve-la entre em contato comigo.
Abraços.
Boa tarde Fagner. Infelizmente eu não desenvolvo mais projetos para terceiros. Sugiro contratar um freelancer como menciono neste post aqui: https://www.luiztools.com.br/post/terceirizando-online-com-estrangeiros/
Olá pessoal, Luiz tenho um site guia de endereços online, agora estou querendo Programa um bot para varrer a web em busca de registros de endereços telefone e nome de empresas e alimentar meu banco de dados é possível desenvolver um bot desses? Fico no aguardo por resposta, obrigado. Abraço.
É possível sim, eu desenvolvi dois projetos semelhantes, na época que fazia freelas ainda, um para um guia de classificados em 2010 e outro para um guia de empresas em 2011. O segredo para ganhar volume rapidamente é não crawlear a web inteira, mas sim outros guias mais maduros e depois fazer uma curadoria dos dados para remover duplicidades, inconsistências, etc. Aqui no blog você encontra tutoriais que podem te ajudar nisso.
Luiz no caso seria melhor programar ele Java ou PHP mesmo, e se leva muito tempo para programa esse bot
Antigamente eu fazia bots em C#, hoje em dia só faço com Node.js, assim como ensino aqui no blog (procure por webscrapper na caixa de pesquisa do blog), por facilidade e performance.
O tempo de programação depende de vários fatores, dentre eles: prática na construção desse tipo de algoritmo, suporte da linguagem à criação de bots, variedade de fontes a serem coletadas, complexidade da análise que será aplicada aos dados, etc. É complicado de eu dizer o quanto você ou sua equipe demorariam pra fazer um bot do jeito que você deseja.
Luiz brigadão cara me ajudou bastante, vou dá uma sacada nos tutoriais também para ir no caminho certo, grande abraço.
[…] dicas: Como criar um mecanismo de busca. […]
Preciso fazer um buscador de produtos importados. Ir no site dos fornecedores e compilar os resultados dos produtos em ordem.
O primeiro passo é verificar se os fornecedores possuem APIs ou fornecem acesso ao banco de dados deles. Caso contrário, terá de criar um webscrapper para ler das próprias páginas do site, o que é bem mais trabalhoso. Tem tutorial aqui no blog também.
O melhor é se integrar com os fornecedores via API, fazer isso na “mão grande” pode até te gerar problemas, embora tecnicamente dê para fazer. Se for pelo segundo caminho, deverá criar um webscrapper para cada site de fornecedor, segue tutorial: https://www.luiztools.com.br/post/webscrapping-com-node-js/
Excelente artigo! Como já faz um bom tempo, gostaria de saber quais tecnologias utilizaria hoje? Recomendaria alguma ferramenta que encurtasse esse caminho? Teria algum curso atualizado?
Obrigada!
Infelizmente não tenho nenhum curso que aborde este assunto especificamente, mas Node é abordado em todos eles. Hoje em dia eu usaria as mesmas tecnologias citadas (Node+Mongo) ou a stack do Elasticsearch, a julgar da experiência da equipe e/ou funcionalidades necessárias no buscador.
Muito legal. Tenho uma idéia para criar um buscador mas não entendo de programação. Você tem alguma recomendação para que eu dê o passo inicial?
Tem essa playlist no meu canal que ensina programação do completo zero: https://www.youtube.com/watch?v=c9mDHLYAIu8&list=PLsGmTzb4NxK3r0_sMLyHKaYX97tPN2QPm