
Este post vem sendo pedido por alguns amigos tem algum tempo já. Isso porque mecanismos de busca tem sido motivo de muito estudo de minha parte desde 2010, quando estava me formando na faculdade e resolvi criar o Busca Acelerada, o primeiro mecanismo de busca que desenvolvi. De lá pra cá tive a oportunidade de desenvolver buscadores de legislação, de fofocas de famosos, de informações da construção civil e muito mais.
A ideia então é eu mostrar, rapidamente, como se cria um site básico de busca que, embora simples, já será muito superior à maioria dos buscadores que os desenvolvedores fazem baseados em SQL. Sim, porque o meu site de busca não usará SQL, mas sim NoSQL, MongoDB para ser mais exato. E para a performance ficar ainda melhor, ele será feito usando a dupla NodeJS + MongoDB que nasceu pra ficarem juntos!
Para conseguir acompanhar este post, você já deve conhecer NodeJS + MongoDB. Caso não conheça, sugiro começar com este tutorial aqui. Também é altamente recomendado que tenha lido esse meu outro post, sobre como criar mecanismos de busca.
Note que não vou ensinar aqui como se criam crawlers ou qualquer outro algoritmo de coleta de informações para popular seu mecanismo, conforme citado no post sobre mecanismo de busca. Considero aqui que você já tem uma massa de dados que deseja oferecer através de um site de busca. Pode ser uma base SQL tradicional, um XML, um Excel, você que sabe.
Caso realmente precise criar um crawler, leia este post aqui!
Com tudo isso em mente, vamos começar!
Veremos nesse artigo:
- Configurando o Projeto
- Configurando o Banco
- Preparando os dados
- Configurando o ORM
- Criando as views
- Programando a busca
Querendo algo mais “pesado” de MongoDB, sugiro este post aqui, focado nesta tecnologia de banco de dados. Também recomendo dar uma olhada no vídeo abaixo, nele eu crio um mecanismo de busca, mas sem usar o Mongoose:
Parte 1: Configurando o projeto
Baixe e instale o NodeJS na sua máquina. Se não souber como ou tiver alguma dificuldade, pode usar o vídeo abaixo como guia.
Depois, instale globalmente o pacote Express Generator, com o comando abaixo em um terminal com permissão de administrador. Esse pacote está bem desatualizado, mas vai servir pra ganharmos tempo na estrutura básica do projeto, depois pode substituir por algo mais profissional, como ReactJS, por exemplo.
|
1 |
npm install -g express-generator |
Agora crie uma pasta para seus projetos Node e vá até ela via linha de comando, digitando:
|
1 |
express -e --git buscador-node-mongoose |
Isso irá criar toda a estrutura de pastas do nosso projeto buscador-node-mongoose usando Express. Agora entre na pasta do projeto recém criado com ‘cd’ e instale as extensões do mongodb e do mongoose:
|
1 |
npm install mongoose mongodb |
Depois, vá na pasta views e dentro do arquivo error.ejs, cole o seguinte código HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<!DOCTYPE html> <html lang="en"> <head> </head> <body> <h1 class="text-center title-1"> Error </h1> <hr class="center-block small text-hr"> <h2><%= error.status %></h2> <p> <%= error.stack %> </p> </body> </html> |
Os demais arquivos vamos mexer depois.

Parte 2: Configurando o banco
Aqui você tem duas opções: usar um Mongo em uma plataforma, como a Atlas, e outra é baixar e executar localmente, que é o que ensino com o vídeo abaixo e explico a seguir, caso prefira ler.
Baixe e extraia o MongoDB (é apenas uma extração de pastas e arquivos, que sugiro que faça em C:\\). Agora abra o prompt de comando, navegue até a pasta onde foi instalado o seu Mongo, geralmente em “c:\\program files\mongodb”, acesse a subpasta “bin” e dentro dela digite o comando (certificando-se que exista uma pasta data dentro da pasta mongodb que você deverá criar):
|
1 |
mongod --dbpath c:\\mongodb\data |
Isso irá criar e deixar executando uma instância do MongoDB dentro da pasta data do mongodb. Não feche esse prompt para manter o Mongo rodando local.
Independente da opção escolhida
Agora é hora de baixar e extrair o Mongo Shell (mongosh) que é uma ferramenta utilitária de linha de comando disponível neste link. Com o executável mongosh na pasta bin, abra outro prompt de comando e navegue até a pasta bin do MongoDB novamente, digitando o comando “mongosh” para iniciar o client do Mongo. Se o seu MongoDB é local, o comando será apenas mongosh, no entanto, se for remoto, você vai se conectar da seguinte maneira:
|
1 |
mongosh mongodb://<host>:<porta>/<nomeBanco> -u <usuario> -p <senha> |
Substitua os valores entre <> pelos seus valores reais. Depois de devidamente conectado (local ou remoto, não importa), chame o comando abaixo para se conectar ao banco que usaremos nesse projeto (substituindo nomeBanco pelo nome do seu banco, aqui chamarei de searchengine).
|
1 |
use searchengine |
Deixe o prompt aberto, usaremos ele em breve para inserir alguns dados de exemplo em nosso banco do buscador.

Parte 3: Preparando os dados
Você pode ter uma base SQL com os dados consolidados do seu negócio e usar o MongoDB apenas como índice e/ou cache de busca. Ou então você pode usar apenas o MongoDB como fonte de dados. Fica à seu critério.
Caso escolha usar SQL e MongoDB, você terá de ter algum mecanismo para mandar os dados que deseja que sejam indexados pelo seu buscador para o Mongo. Este post não cobre migração de dados (mongoimport é o cara aqui), então você deve fazer por sua conta e risco usando os meios que conhecer.
Caso escolha apenas usar o Mongo, você apenas terá de alterar as suas coleções pesquisáveis para incluir um campo com o índice invertido que vamos criar na sequência, com nosso buscador de exemplo.
Em ambos os casos, a sua informação “pesquisável” deve ser armazenada de uma maneira prática de ser pesquisada, o que neste exemplo simples chamaremos de tags. Cada palavra dentro das informações pesquisáveis do seu sistema deve ser transformada em uma tag, que geralmente é um texto todo em maiúsculo (ou minúsculo) e sem acentos ou caracteres especiais.
Por exemplo, se quero tornar pesquisável os nomes dos meus clientes, que no meu SQL estão como “Luiz Júnior”, eu devo normalizá-lo para as tags “LUIZ” e “JUNIOR”, separadas. Assim, quando pesquisarem por luiz, por junior, or luiz junior e por junior luiz, este cliente será encontrado.
Assim, cada registro na sua coleção do MongoDB terá um atributo contendo as suas tags, ou informações pesquisáveis, o que facilmente fazemos com um atributo do tipo array no Mongo. Como abaixo:
|
1 2 3 4 5 6 |
{ "_id": ObjectId("123-abc-456-def"), "nome": "Luiz Fernando Duarte Júnior", "tags": ["LUIZ", "FERNANDO", "DUARTE", "JUNIOR"], ... } |
Para podermos fazer a busca depois usaremos uma query com um $in ou um $all, que são operadores do Mongo para pesquisar arrays de palavras (seus termos de busca) dentro de arrays de palavras (as tags).
Então, caso esteja migrando dados de um SQL para o Mongo, certifique-se de quebrar e normalizar as informações que deseja pesquisar dentro de um campo tags, como o acima, que será o nosso índice de pesquisa.
Para fins de exemplo, usaremos a massa de dados abaixo (apenas 2 registros) para pré-popular nosso banco com clientes (customers) que já possuem tags normalizadas como mencionado acima. Note que as tags de cada customer são um misto de seus nomes e profissões, o que você pode facilmente fazer com seus dados também.
|
1 2 |
custArray = [{"nome":"Luiz Júnior", "profissao":"Professor", "tags":["LUIZ","JUNIOR","PROFESSOR"]},{"nome":"Luiz Duarte", "profissao":"Blogueiro", "tags":["LUIZ","DUARTE","BLOGUEIRO"]}] db.customers.insertMany(custArray); |
O comando acima deve ser executado no console cliente do Mongo, logo após o “use searchengine”.
Obviamente existem técnicas de modelagem de banco para mecanismos de busca muito mais elaboradas que essa. Aqui estamos tratando todas as informações textualmente sem classificação do que é cada uma, sem se importar com a ordem ou peso delas, etc. Mas a partir daqui você pode fazer as suas próprias pesquisas para melhorar nosso algoritmo.
Mais pra frente, quando fizermos as nossas pesquisas, vamos fazê-las sempre buscando no campo tags, ao invés de ir nos atributos do documento. Até porque nosso buscador terá apenas um campo de busca, assim como o Google, como veremos adiante.
Mas e a performance disso?
Para resolver este problema vamos criar um índice nesse campo no MongoDB. Mas não é qualquer índice, mas sim um índice multi-valorado pois o campo tags é um array de elementos. O Mongo organiza campos multi-valorados em índices invertidos, que são exatamente um dos melhores tipos de índices básicos que podemos querer em um mecanismo de busca simples como o nosso. Eu já mencionei sobre índices invertidos no post sobre Como criar um mecanismo de busca.
|
1 |
db.customers.createIndex({ "tags": 1 }); |
O comando acima deve ser executado no console cliente do Mongo e fará com que todos os customers inseridos a partir de então (bem como os já existentes) respeitarão essa regra do índice no campo tags. Para verificar se funcionou o nosso índice, teste no console cliente do Mongo consultas como essa que traz todos os clientes que possuam a tag LUIZ (isso funciona para lógica OR também, pois recebe um array de possibilidades):
|
1 |
db.customers.find({"tags": { $in: ["LUIZ"] }}).pretty() |
Ou esse que traz todos com as tags LUIZ e JUNIOR (aqui temos lógica AND):
|
1 |
db.customers.find({"tags": { $all: ["LUIZ","JUNIOR"] }}).pretty() |
Elas deverão funcionar de forma extremamente performática, mesmo que tenha adicionado centenas de milhares de clientes.
Parte 4: Configurando o ORM
Aqui usaremos o Mongoose, o mais profissional e eficiente ORM para NodeJS + MongoDB na época em que escrevo este post. Fiz testes com um concorrente, o Monk, e a diferença era de 50% a mais de performance, então fique com o Mongoose. Caso não goste de ORMs, neste outro tutorial ensino como usar o MongoDB com o driver nativo e caso prefira outro ORM, ensino Prisma nesse aqui.
Conforme definimos na parte 1 deste tutorial, o Mongoose foi instalado como sendo uma das dependências em nosso package.json, então basta utilizarmos ele em nossos códigos JS. Crie na raiz do seu projeto um arquivo db.js e dentro coloque a conexão do Mongoose com seu MongoDB, mais o esquema da sua coleção que será consultada (troque a string de conexão apropriadamente).
|
1 2 3 4 5 6 7 8 9 10 11 |
const mongoose = require('mongoose'); mongoose.connect('mongodb://usuario:senha@servidor:porta/nomeBanco'); const customerSchema = new mongoose.Schema({ nome: String, profissao: String, tags: [String] }, { collection: 'customers' } ); module.exports = { Mongoose: mongoose, CustomerSchema: customerSchema } |
Note que definimos o schema da nossa coleção customers, incluindo o campo tags como sendo um array de elementos, como já vimos na parte 3 deste tutorial.
Parte 5: Criando as views
Agora vamos criar as views que vamos utilizar: a de pesquisa e a de resultados de pesquisa (chamada de SERP pelos especialistas: Search Engine Results Page). Na verdade vamos fazer as duas em uma, por pura preguiça deste que vos escreve. 😉
Dentro da pasta views do seu projeto, abra index.ejs e cole o seguinte código HTML dentro dele:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<!DOCTYPE html> <html lang="en"> <head> </head> <body> <center> <h1> Search Engine </h1> <form action="/search" method="get"> <input type="text" name="query" /> <input type="submit" value="Search" /> </form> </center> </body> </html> |
Essa é uma página de busca bem simples, com um formulário contendo um campo e um botão de pesquisar. Quando o formulário é submetido, enviamos o usuário para a página de resultados, que vamos criar na sequência.
Salve o arquivo, reinicie seu servidor NodeJS (derrube-o com Ctrl+C se estiver executando e depois inicie-o com npm start a partir da pasta do projeto searchengine).
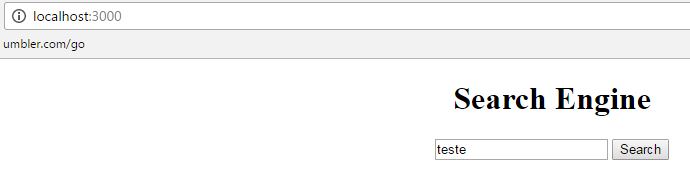
Se você pesquisar alguma coisa, como a palavra teste da foto, verá que não vai funcionar, vai dar erro 404, porque ainda não criamos a página de resultado, nem a rota para ela. Na verdade usaremos a mesma página, com algumas modificações.

Parte 6: Programando a busca
Inclua o seguinte código que mistura HTML com JS (característica da view engine EJS que estamos utilizando) logo após seu formulário de busca, na index.ejs:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<% if(results){ if(list.length > 0){ %> <b>Resultados da pesquisa por <%= search %>:</b> <ul> <% list.forEach(function(item){ %> <li><%= item.nome %> (<%= item.profissao%>)</li> <% }); %> </ul> <% } else{ %> <b>Nenhum resultado encontrado para <%= search %>!</b> <% } } %> |
Esse código vai permitir que, na mesma página de busca, a gente liste os resultados logo abaixo, quando houverem. Quando não existirem resultados, uma mensagem informará adequadamente.
Note que incluímos aí uma série de elementos que vamos ter que programar agora, para que funcionem, entre eles as variáveis results, list e search, que devem ser passadas através da rota que levará o usuário até esta página.
Primeiro, vamos modificar a rota default que leva até a index com a caixa de busca para que ela retorne a variável results como false, indicando que não há resultado a serem exibidos e que a lista de resultados não deve ser exibida pois é um acesso à home. O código abaixo deve estar em routes/index.js:
|
1 2 3 4 |
/* GET home page. */ router.get('/', function(req, res, next) { res.render('index', { results: false }); }); |
Substitua o código original da rota default por este. Isso garantirá que a nossa index.ejs continue funcionando mesmo após nossas últimas adições.
Agora, adicione uma nova rota no mesmo arquivo routes/index.js, que atenderá às requisições /search que são feitas quando se clica no botão de busca da index.
|
1 2 3 4 5 6 7 8 |
/* GET search page. */ router.get('/search', async (req, res, next) => { const searchParams = req.query.query.toUpperCase().split(' '); const db = require('../db'); const Customer = db.Mongoose.model('customers', db.CustomerSchema, 'customers'); const docs = await Customer.find({ tags: { $all: searchParams } }); res.render('index', { results: true, search: req.query.query, list: docs }); }); |
Aqui nós pegamos a variável de querystring chamada query e colocamos ela toda em maiúsculas e damos um split pelos espaços, para transformar os termos de busca em um array de termos. O ideal é criar alguma rotina de normalização dos termos de busca, para fazer coisas mais avançadas que essa como remover acentos, etc, mais deixo ao seu critério.
Uma vez com os termos de busca OK, carregamos a variável db com os dados do banco, carregamos o model de customers e damos um find por documentos que possuam as tags que estamos buscando. Nesse caso estou usando um $all, que faz a lógica AND, mas você pode ajustar facilmente por um $in, para fazer a lógica OR ou ainda fazer uma mescla através de análise da pesquisa realizada (tipo o que o Google faz quando digitamos com aspas – AND – ou sem aspas – OR).
O resultado da pesquisa é retornado em um objeto contendo results:true (foi realizada uma pesquisa), search (os termos pesquisados) e list (os documentos retornados). Esse objeto será usado pela lógica anterior que colocamos no EJS que itera sobre os elementos e os renderiza como itens de uma lista não ordenada.
Salve todos os arquivos que não estejam salvos, reinicie o seu servidor Node e mande executar novamente. Você irá entrar na tela index normal, mas quando pesquisar por algum termo que exista no seu banco, verá uma tela de resultados como essa:
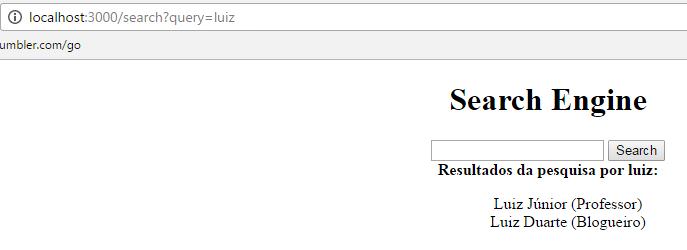
Ou, caso tenha pesquisado por um termo que não existe, verá algo como:
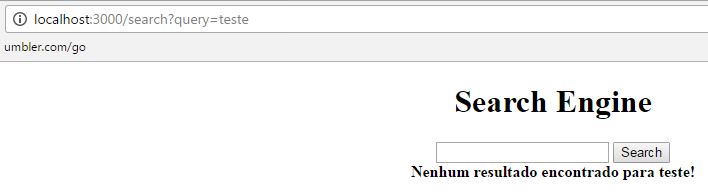
Claro que você pode fazer muitas modificações nos seus resultados de pesquisa. Você pode querer jogá-los em uma página separada, com um layout mais profissional. Pode querer colocar links neles que levarão o usuário para páginas com detalhes sobre os clientes. Pode querer implementar algum tipo de autocomplete na caixa de busca, usando o Typeahead do Bootstrap. Pode implementar algum mecanismo para sinônimos, plurais, etc para tornar sua busca mais inteligente.
Há milhares de coisas que você pode fazer e eu poderia escrever um ebook sobre isso. Se tivesse tempo no momento. 😀
De qualquer maneira, acho que já consegui dar uma luz à quem nunca criou um buscador antes. Ou quem criou apenas usando LIKE % do SQL tradicional. :/
Caso queira transformar seu algoritmo de busca em uma API, recomendo fortemente dar uma olhada sobre como criar uma API com NodeJS.
Caso queira aprender a criar o crawler para pegar as informações, esse tutorial pode lhe mostrar como.
Caso vá colocar esse projeto em produção e esteja enfrentando problemas, dê uma olhada nesse post sobre como fazer deploy em servidores Windows.
Depois que colocar ele em produção, visando obter muitas visitas vindas do Google, sugiro ler esse meu artigo aqui sobre SEO para mecanismos de busca.
Um abraço, e até a próxima!
Curtiu o post? Então clica no banner abaixo e dá uma conferida no meu livro sobre programação web com Node.js!








Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.